Table of Contents
Algorithm
Leetcode 741: Cherry Pickup
https://dreamume.medium.com/leetcode-741-cherry-pickup-eddb682bbb42
Review
服务 Facebook 多流:通过重新设计获得效率和性能
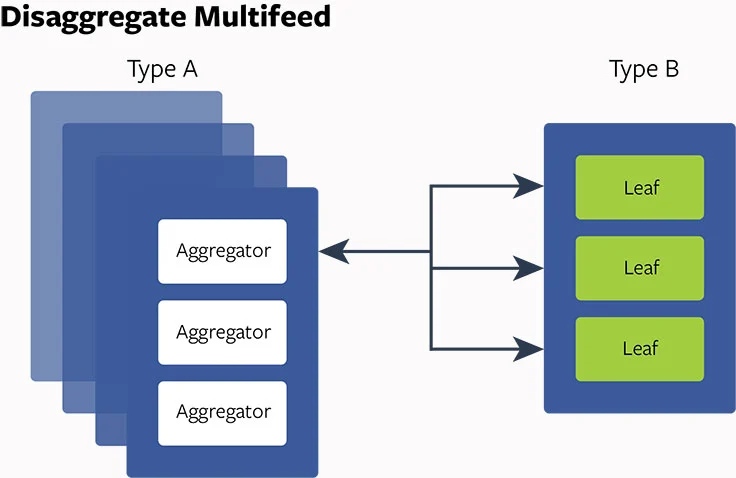
Disaggregation 的强大
Disaggregation 已证明对 Facebook 是一个有用的策略。分割系统为它们的核心组件和再让他们合成的想法对我们的基础设施在灵活性和可扩展性上更有意义
disaggregation 是什么意思?当工程师通常使用各种类型的服务器,每个有它自己的 CPU,内存和闪存或磁盘,每个服务器配置使用这些资源的不同比例。运行在服务器上的服务以一种固定聚合的方式使用这些资源。Disaggregation,相反地,创建特殊的服务器池,每个聚焦在一种资源类型比如计算,内存,HDD 存储或闪存等
分割系统为构建块和让这些分片适配可有多维度的优势:
- 硬件替换高效和利用高效:我们可单独升级和替换每种资源类型,有潜力地减少总的硬件替换数。另外,每种资源(比如 CPU,内存)可更好的扩展这样能更好的利用和最小化资源浪费
- 自定义配置:我们可定制存储设计,例如,针对我们的需要
- 加速新技术适配:当一个新的硬件技术变得有效,我们可快速适配
- 软件生产可靠性和性能:软件生产组件可被重新设计且每个组件可在单独的服务器池中运行。这允许软件性能提升和可靠性得到改善
- CPU 效率:各种工作负载在同一个服务器可能不能很好工作,对内核或处理器来说管理工作负载来获得高 CPU 利用率很困难
一个例子,我们均衡 disaggregation 的概念来重新设计多流,一个包含在新闻流里的分布式后台系统。当一个人获取他的 Facebook 流,多流查找用户的朋友,找到所有他们的最新动作,且决定基于某个关系和排名算法下如何渲染。disaggregation 的结果关系到基础设施跨越多个方面的追踪:
- 高效:多流 aggregator 和叶子基础设施对内存和 CPU 消耗优化的 40% 效率改进
- 性能:10% 的多流 aggregator 延时缩减
- 扩张性:多流的每个组件(例如,aggregator 和叶子)可独立扩展
- 可靠性:增加流量峰值的恢复能力;组件故障(例如 aggregator 和叶子)隔离
多流构建块
为理解如何获得这些结果,我们应该首先分解多流主要的高层组件
- Aggregator:查询引擎接受用户请求和从后端存储提取新闻流。它也做新闻流 aggregation,排名和过滤且返回结果给客户端。aggregator 是 CPU 密集的但内存不密集
- 叶子:分布式存储层索引大多数最近的新闻流动作和在内存中存储它们。通常 20 个叶子服务器作为一个组工作且全复制包含所有用户的索引数据。每个叶子服务从 aggregator 来的数据提取请求。每个叶子是内存密集的但 CPU 不密集
- 尾部:输入数据流水线指导用户动作和实时反馈到叶子存储层
- 持久化存储:从开始重加载一个叶子的裸日志和快照
多流,老方式:聚集设计
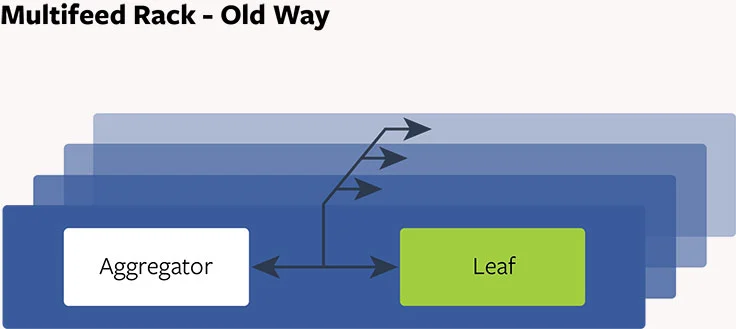
过去,每个多流 aggregator 跟一个叶子成对,且它们位于一个共享的服务器上。二十个这样的服务器在一起成组,作为一个复制节点且包含用户的新闻流数据。每个复制节点有 20 个 aggregator 和 20 个叶子。当接收到一个请求,每个 aggregator 发散请求到所有叶子来提取数据,排行和过滤数据且返回结果给客户端。我们获得多流服务器高 CPU 能力和大型内存存储。但这有一些问题:
- 可靠性:通常对一个 aggregator 可能获得一个有很大朋友的用户的一个重请求,导致 CPU 使用上的一个凸起高峰。如果峰值足够大,因为 aggregator 消耗 CPU,在相同服务器上的叶子可能变得不稳定。任何 aggregator(和它对应的服务器)和叶子交互也变得不稳定,导致复制节点一个迭代的问题出现
- 硬件可扩展性:我们的基础设施中有许多复制节点。容量配置基于 CPU 服务用户请求的需求。我们添加数百个复制节点来协调随时间增长的流量。这样,对每个 CPU 的内存增加。明显内存过度构建因为当复制节点增加时它不是必要的资源
- 资源浪费:每个尾部转发用户行为且反馈到一个叶子服务器。它是多流的实时数据流水线。叶子服务器花费 10% 的 CPU 来执行这些实时升级。我们提到的复制节点数使用不必要的 CPU 资源保持我们的叶子存储更新
- 性能:aggregator 和叶子有非常不同的 CPU 特性。aggregator 线程跟叶子线程的 CPU 缓存竞争,导致缓存冲突和资源竞争。因为很多线程运行导致高的线程切换成本
Disaggregate 多流设计和实验
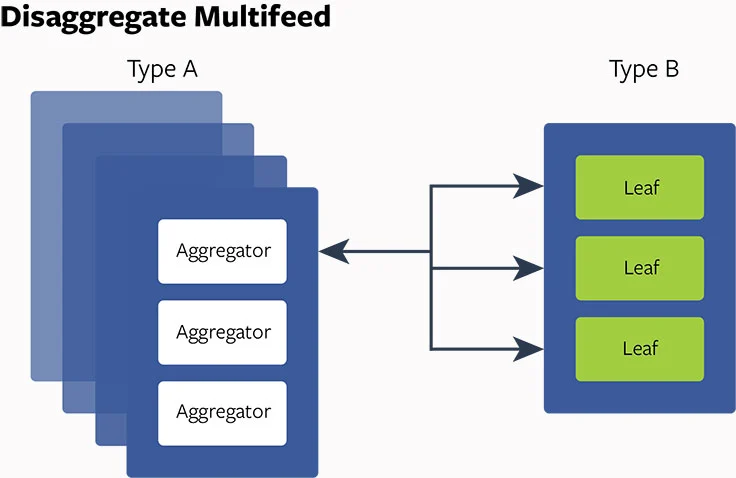
对这些确定的问题:我们如何构建硬件和改变软件产品架构来处理这些问题?在深入调查和分析之后,我们决定实现 disaggregate 硬件/软件设计多流处理。首先,我们设计一些服务器持有密集 CPU 的能力(A 类型服务器)且一些有大内存存储(B 类型服务器)。然后我们把 aggregator 放在 A 类型服务器上且叶子放在 B 类型服务器上,这使我们能够优化线程配置,减少线程切换成本,启动更好的 NUMA 平衡,且调整 aggregator 和叶子的比例
disaggregate 设计在我们内部的实验中显示的改进:
- 优化硬件/服务使用率:通过调整 aggregator 和叶子的比例,我们可缩减总的 CPU 到内存比例从 20:20 到 20:5 或 20:4。这对内存是 75% 到 80% 的缩减
- 服务能力可扩展性:aggregator 和叶子能力可被独立扩展。这允许软件有更多的灵活性
- 性能:aggregator 的平均客户端延时降低 10%
- 可靠性:disaggregate 设计更能适应突然的写流量高峰。任意 aggregator 故障可作为独立事件,不影响其他 aggregator 和叶子
对这样的鼓舞结果,我们快速的采用了设计。我们从概念设计到最后的部署只用了几个月,且把新的 disaggregate 架构添加在现有的多流配置上。其次,我们对其他 Facebook 服务比如搜索探索 disaggregate 闪存雪橇技术,操作分析和数据库。我们乐观认为受益是显著的
Tips
Avoiding Double Payments in a Distributed Payments System
背景
Airbnb 迁移了它的基础设施到面向服务架构(SOA)。SOA 提供许多优点,比如开启开发者指导说明和更快地迭代能力。然而,它也对票务和支付应用程序带来挑战因为它使维护数据集成更加困难。一个 API 调用一个服务进一步调用 API 到下面的服务,每个服务改变状态且可能有副作用,相当于执行一个复杂的分布式交易
为确保所有服务间的一致性,会使用一些协议比如两阶段提交。没有这样的协议,分布式交易会对数据集成维护,允许优雅的降级和取得一致性形成挑战。请求在分布式系统中也必然存在失败 - 连接丢失和在某点超时,特别对包含多个网络请求的交易
有三个不同的常用技术用于分布式系统来获得最终一致性:读修复,写修复和异步修复。每个处理有各自的好处和妥协。我们的支付系统在各种功能中使用这三个处理
异步修复包含服务器响应运行数据一致性检查,比如表扫描,lambda 函数和 cron 任务。另外,服务器到客户端的异步通知在支付中广泛使用来强制客户端的一致性。异步修复,异步通知可用于读写修复技术的结合,提供一个解决方案复杂度上对防御妥协的第二条线
在本文中我们的解决方案使用写修复,客户端到服务器的每个写调用尝试修复一个不一致,被破坏的状态。写修复需要客户端更灵活且允许重复的请求且不维护状态(除了重试)。客户端可按需请求最终的一致性,在用户体验上控制它们。幂等在实现写修复中是一个及其重要的属性
幂等是什么?
一个 API 请求是幂等的,客户端可重复调用并获得相同的结果。即多次重复的请求效果相同,如同一个请求一样
这个技术在票务和支付系统包括资金转移里普遍使用,支付请求只完整处理一次(也成为只转发一次)。如果一个转移资金的单一操作多次调用,底层系统最多只转移一次。这样 Airbnb 支付 API 避免多次支付给宿主,甚至多次向客户收费
设计上,幂等允许一个 API 使用自动重试机制从客户端多个调用来获得最终的一致性。这个技术通常在幂等的客户端服务器关系中使用,且现在有时我们使用在我们的分布式系统中
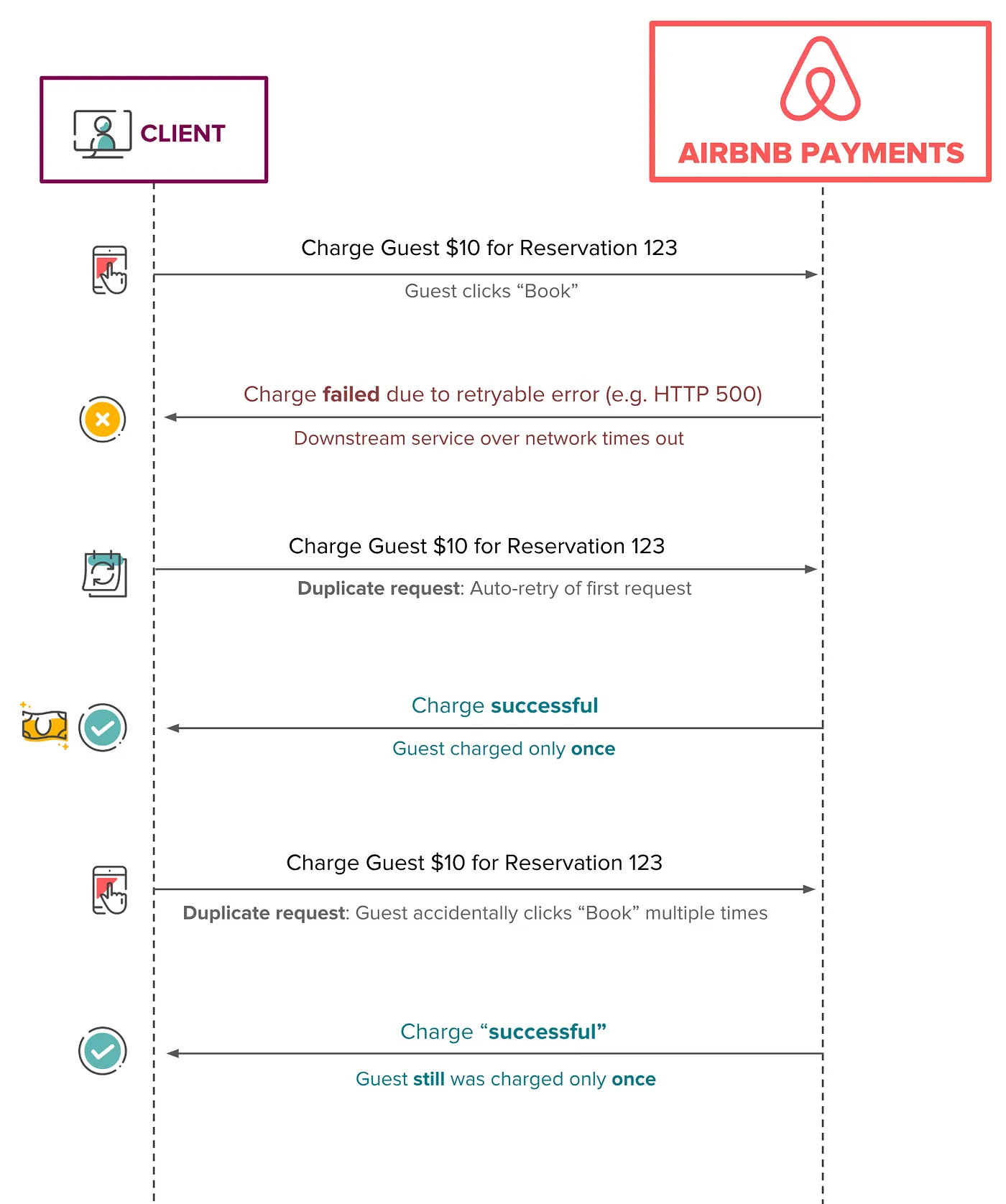
在高层,如下的图显示一些简单的重复请求和理想的幂等行为的场景。不管收费请求有多少次,客户最多只被收费一次
问题状态
对我们的支付系统保证最终一致性是最重要的。幂等是一个想要的机制在分布式系统中达到它。在 SOA 世界里,我们将故意运行一些错误。例如,如果客户端消费响应失败如何恢复?如果响应丢失或客户端超时会怎么处理?如果竞争条件导致订阅按钮点击两次会怎么处理?我们的需求如下:
- 实现一个单一的,对我们给定案例特殊自定义处理的解决方案,我们更需要一个一般化能配置幂等的解决方案用于 Airbnb 的各种支付 SOA 服务
- 当基于 SOA 的支付产品迭代中,我们不能不能在数据一致性上妥协因为这将直接影响我们的社区
- 我们需要非常低的延迟,这样构建一个分离,单独的幂等服务不能低效。最重要的,服务将遭遇原本就要解决的相同问题
- Airbnb 使用 SOA 扩展它的工程师组织,让每个开发者对数据集成和最终一致性挑战特殊化是低效的。我们想要产品开发者屏蔽这些困扰并让他们集中于产品开发和快速迭代
另外,对代码可读性,可测试性和解决问题能力的妥协都被认为是不可能取得成功的
解决方案的解释
我们想要能够唯一确认每个来的请求。另外,我们需要精确跟踪和管理特别请求的生命周期
我们在多个支付服务中实现和利用 Orpheus,一个一般化幂等库。Orpheus 是希腊神话中的传奇英雄,他能策划和吸引所有生物
我们选择一个库作为一个解决方案因为它提供低延时且对高速产品代码和低速系统管理代码间提供清晰地隔离。在高层,它包含如下简单的概念:
- 一个幂等键给到框架,代表一个幂等请求
- 幂等信息表,总是从一个切片主数据库中读写(为一致性)
- 数据库交易组合代码库的不同部分来确保原子性,使用 Java lambda
- 错误响应分类为可重试和非可重试
我们将详细说明幂等保证的复杂分布式系统可变成自愈和最终一致性。我们也将谈及一些妥协和我们的解决方案需要考虑到的额外复杂性
保持数据库提交到最小
在幂等系统中的一个关键需求是只生成两个输出,成功或失败,并确保一致性。否则,数据变种可导致数小时处理和不正确的支付。因为数据库提供 ACID 属性,数据库交易在确保一致性时可有效使用原子性写数据。一个数据库提交可保障整体为成功或失败
Orpheus 聚焦在假设大多数标准 API 请求可分割为三个不同的阶段:Pre-RPC,RPC 和 Post-RPC
一个 RPC 或原创过程调用指当一个客户端生成一个请求到一个远端服务器且等待该服务器在重置它的处理前完成请求的过程。在支付 API 的上下文中,我们把一个 RPC 作为一个网络中到下流服务的一个请求,其包括外部支付处理和请求银行。剪短地说,如下是每个阶段发生的事情:
- Pre-RPC:支付请求的细节记录在数据库中
- RPC:请求在网络中对外部服务活跃且收到响应。这是做一个或多个幂等计算或 RPC 的地方(例如,如果有重试首先查询交易状态的服务)
- Post-RPC:从外部服务记录响应细节到数据库,包含它的成功和是否一个坏的请求可重试
为维护数据集成,我们继承两个简单的规则:
- 在 Pre 和 Post-RPC 阶段没有网络上的服务交互
- 在 RPC 阶段没有数据库交互
我们需要想要避免混合数据库操作和网络通信。我们学到在 Pre 和 Post-RPC 阶段网络调用(RPC)是困难的且导致一些坏的结果比如快速连接池耗尽和性能降级。网络调用是不可靠的。因此,我们封装 Pre 和 Post-RPC 阶段在数据库交易内部被库本身初始化
我们也想要调用单个 API 请求可能包含多个 RPC。Orpheus 支持多 RPC 请求,但本文中我们想要阐述我们的想法进程只设计单 RPC 的情况
![]()
如上图所示,每个数据库提交在每个 Pre-RPC 和 Post-RPC 阶段被组合成一个数据集交易。这确保原子性 - 工作的整体(Pre-RPC 和 Post-RPC 阶段)可作为一个整体一致性的失败或成功。这个动机是系统应该失败在它可恢复的地方。例如,如果一些 API 请求在一个长的数据库提交中失败,它会非常困难地系统性保持追踪每个失败发生的地方。注意到所有网络通信,RPC,从所有数据库交易中分离
这里一个数据库提交包含一个幂等库提交和应用程序层数据库提交,所有组合在相同的代码块中。不小心处理,在真实的代码中这将开始变得杂乱。我们也感觉它不应该是产品开发者的责任来调用某个幂等函数
用 Java Lambda 来恢复
Java lambda 表达式可无缝组合多个句子为一个数据库交易,而不影响可测试性和代码可读性
如下是一个例子,在行为中用 Java 简单使用 Orpheus
public Response processPayment(InitiatePaymetRequest request, UriInfo uriInfo)
throw YourCustomException {
return orpheusMamager.process(request.getIdempotencyKey(),
uriInfo,
// 1. Pre-RPC
() -> {
// Record payment request information from the request object
PaymentRequestResource paymentRequestResource = recordPaymentRequest(request);
return Optional.of(paymentRequestResource);
},
// 2. RPC
(isRetry, paymentRequest) -> {
return executePayment(paymentRequest, isRetry);
},
// 3. Post RPC - record response information to database
(isRetry, paymentResponse) -> {
return recordPaymentResponse(paymentResponse);
});
}
在更深一层,有一个源码的简单摘录
public <R extends Object, S extends Object, A extends IdempotencyRequest> Response process(
String idempotencyKey,
UriInfo uriInfo,
SetupExecute<A> preRpcExecutable, // Pre-RPC lambda
ProcessExecutable<R, A> rpcExecutable, // RPC lambda
PostProcessExecutable<R, S> postRpcExecutable) // Post-RPC lambda
throws YourCustomException {
try {
// Find previous request (for retries), otherwise create
IdempotencyRequest idempotencyRequest = createOrFindRequest(idempotencyKey, apiUri);
Optional<Response> responseOptional = findIdempotencyResposne(idempotencyRequest);
// Return the resposne for any deterministic end-states, such as
// non-retryable errors and previously successful responses
if (responseOptional.isPresent()) {
return responseOptional.get();
}
boolean isRetry = idempotencyRequest.isRetry();
A requestObject = null;
// STEP 1: Pre-RPC phase:
// Typically used to create transaction and related sub-entities
// Skipped if request is a retry
if (!isRetry) {
// Before a request is made to the external service, we record
// the request and idempotency commit in a single DB transaction
requestObject =
dbTransactionManager.execute(
tc -> {
final A preRpcResource = preRpcExecutable.execute();
updateIdempotencyResource(idempotencyKey, preRpcResource);
return preRpcResource;
});
} else {
responseObject = findResponseObject(idempotencyRequest);
}
// STEP 2: RPC phase:
// One or more network calls to the service. May include
// additional idempotency logic in the case of a retry
// Note: NO database transactions should exist in this executable
R rpcResponse = rpcExecutable.execute(isRetry, requestObject);
// STEP 3: Post-RPC phase:
// Response is recorded and idempotency information is updated,
// such as releasing the lease on the idempotency key, Again,
// all in one single DB transaction
S response = dbTransactionManager.execute(
tc -> {
final S postRpcResponse = postRpcExecutable.execute(isRetry, rpcResponse);
updateIdempotencyResource(idempotencyKey, postRpcResponse);
return postRpcResponse;
});
return serializeResponse(response);
} catch (Throwable exception) {
// If CustomException, return error code and resposne based on
// 'retryable' or 'non-retryable'. Otherwise, classify as 'retryable'
// and return a 500.
}
}
这些隔离提供一些妥协。开发者必须使用预先考虑来确保代码可读性和可维护性作为新开发者持续贡献。他们也需要一致评估适合的依赖和数据。API 调用现在需要重构为三个更小的代码块,其限制开发者写代码的自由度。它事实上对一些复杂 API 调用高效分离成三个阶段比较困难。我们的一个服务实现了有限状态机,对每个交易用 StatufulJ 作为一个幂等的阶段,你可安全地在一个 API 调用中多次幂等调用
处理异常 - 重试或不重试
对 Orpheus 框架,服务器应该知道一个请求是否可安全重试及什么时候不行。当情况出现时,异常需要被小心地处理 - 它们应该被分类为可重试或不可重试。这对开发者添加了一层复杂度且如果没有很好地处理将产生坏的影响
例如,假设一个下载服务临时故障,但异常抛出错误的标签为不可重试而实际上应该为可重试。该请求被定义为失败,且后续重试请求将返回不可重试的错误。相反地,如果一个异常被标签为可重试当它实际上应该为不可重试,则导致双花并需要人工干预
一般的,我们相信未知运行时异常由于网络和基础设施问题(5XX HTTP 状态)为可重试。我们期望这些错误是暂时的,且我们期望后续的重试最终会成功
我们分类验证错误,比如无效的输入和状态(比如,你不能退还一笔退款),不可重试(4XX HTTP 状态) - 我们期望同一请求的所有后续重试在相同的状态下失败。我们创建一个自定义,一般化异常类处理这些情况,缺省为不可重试,且对某些其他情况,分类为可重试
请求负载对每个请求仍然是相同的且不能修改,否则它违背了幂等请求的定义
| 可重试 | 不可重试 |
|---|---|
| 临时的 - 我们期望后续请求得到不同的结果 | 我们期望后续请求也会失败 |
| 内部的服务器错误 | 无效的输入和请求 |
| 数据库或网络连接问题 | 行为不支持 |
| 5XX HTTP 状态 | 4XX HTTP 状态 |
还有更多的模糊边界情况需要小心处理。例如,一个 null 值从数据库返回由于连接问题导致,其跟从客户端或三方响应返回的不同
客户端扮演一个重要角色
如同在文章开始所提及的,客户端在一个写修复系统中必须更智能。当与一个幂等库如 Orpheus 交互时它必须拥有一些关键责任:
- 对每个新请求用一个唯一的幂等键;重试时使用相同的幂等键
- 在调用服务之前持久化这些幂等键到数据库
- 适时消费成功的响应并消除幂等键
- 确保在重试时对请求负载的修改是不允许的
- 基于业务需要小心设计和配置自动重试策略(使用指数回退或随机等待时间来避免突暴问题)
如何选择一个幂等键
选择一个幂等键是至关重要的 - 客户端可基于使用的键选择要么请求水平的幂等或条目水平的幂等。这个决定基于不同的业务情况而不同,但请求水平幂等是最直接和常见的
对请求水平的幂等,一个随机且唯一的键应该从客户端选择为了确保在条目收集水平上的幂等。例如,如果我们想要允许对保留订购(比如小的预先支付)有多个不同的支付,我们需要确保幂等键是不同的。使用 UUID 格式是一个好例子
条目水平幂等比请求水平幂等更严谨和受限制。如果我们想要确保一个给定 ID 1234 的一个给定 $10 的支付一次只能退回 $5,因为我们可技术上使得 $5 请求为两次。我们然后想要使用一个确定性的幂等键基于条目模型来确保条目水平的幂等。一个例子格式为 payment-1234-refund。每个退回请求对一个唯一的支付在条目水平上(1234 支付)为幂等了
每个 API 请求有一个过期租赁
多个确定的请求可由多次用户点击或客户端由一个激进的重试策略而激发。这个可潜在地创建竞技条件对我们的社区在服务器或双花上。为避免这个,API 调用,在框架的帮助下,每次在一个幂等键上需要获得一个数据库底层锁。这保证了一个租赁,或一个权限,对给定的请求来保护将来的处理
一个租赁及过期时间覆盖了在服务器端超时的场景。如果没有响应,则一个 API 请求可在当前租赁过期时重试。应用程序可配置关键规则使其比 RPC 超时有一个更高的租赁超时
Orpheus 对一个幂等键提供一个最大重试窗口来提供一个安全避免异常系统行为导致粗暴的重试
记录响应
我们也记录响应,为维护和监控幂等行为。当一个客户端对一个已经达到确定性结尾状态的交易生成相同的请求,比如一个非可重试性错误(比如验证错误)或一个成功的响应,响应被记录在数据库中
持久化响应有一个性能折中 - 客户端可能在重试中接收到快速响应,但这个表会受到应用程序吞吐量的成比例增长。如果我们不注意这个表将快速变得庞大。一个可能的解决方案在某个时间点定期删除行,但删除一个幂等响应太早将有负面效果。开发者也应该警惕不要做向后兼容改变到响应条目和结构
避免复制数据库 - 主服务器粘性
当用 Orpheus 读写幂等信息,我们选择在主数据库直接做。在一个分布式数据库系统中,这是在一致性和延迟之间的一个折中。因为我们不能容忍高延迟或读未提交的数据,使用主数据库的这些表比较适合我们。这样,不需要使用缓存或数据库复制节点。如果一个数据库系统没有配置强读一致性(我们的系统用 MySQL),使用复制节点对这些操作对幂等有负面影响
例如,假设一个支付系统存储它的幂等信息在复制节点数据库上。一个客户端提交一个支付请求到服务,处理被接受,但客户端由于网络问题还没有收到响应。响应存储在服务的主数据库,最终会被写入到复制节点。然而,在复制节点延迟事件中,客户端会触发一个幂等重试到服务且响应还没有记录到复制节点。因为响应“不存在”(在复制节点),服务将错误的再次执行支付,导致双花。下面的例子展示了在几秒钟内的复制节点延迟导致对 Airbnb 社区严重的金融影响
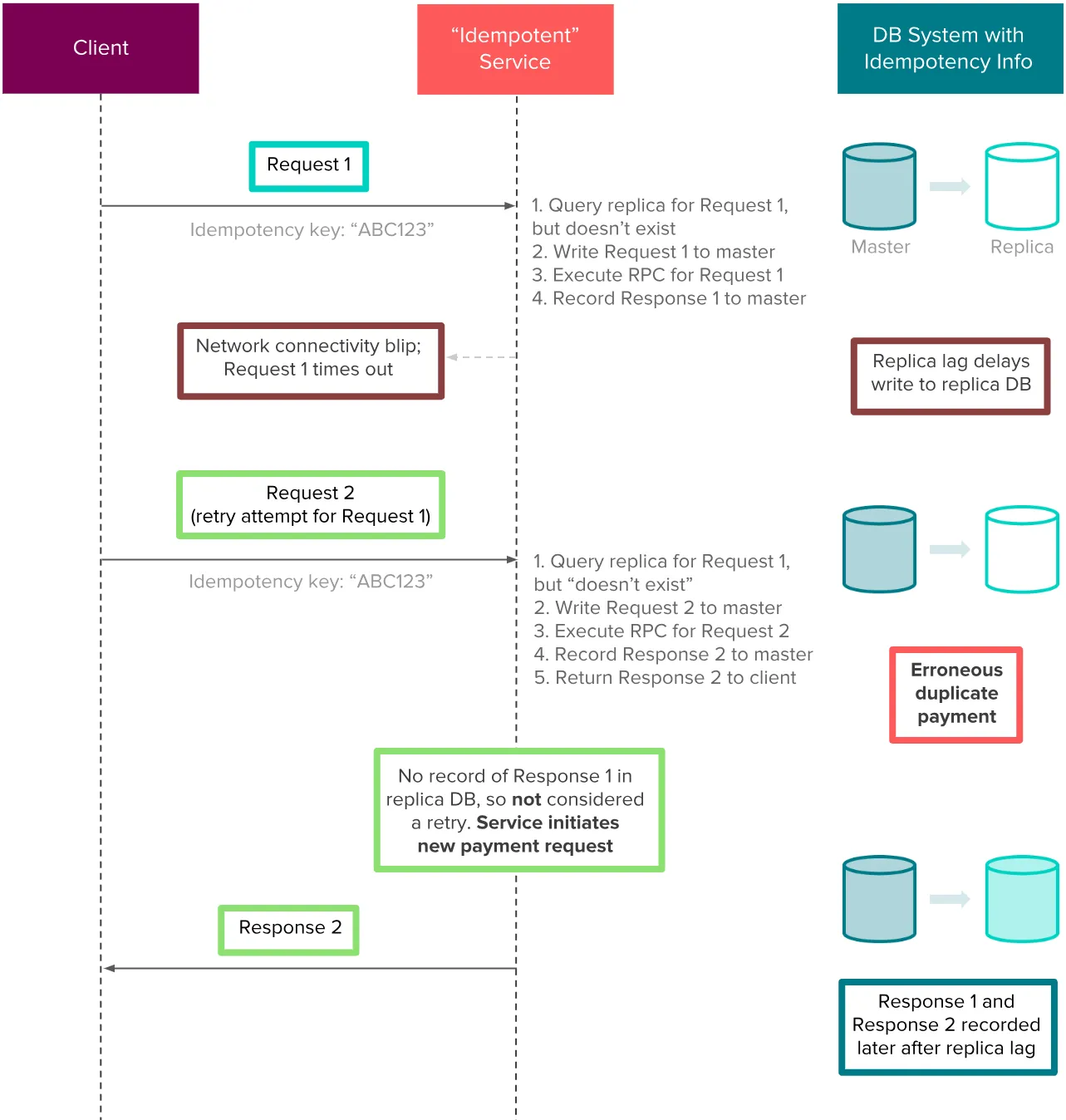

当使用单一的主服务器,很明显扩展性将变成一个问题。我们通过按幂等键分片数据库来平衡这个问题。幂等键我们使用高 cardinality 和平均分布,使它们能被高效分片
最后的想法
在分布式系统领域有无数的不同解决方案来缓和一致性挑战。Orpheus 其中一个对我们来说作用很好因为它一般化且轻量。一个开发者在新服务上可简单导入该库,且幂等逻辑作为应用程序概念和模型之上的一个单独抽象层
然而,达到最终一致性不能避免引入一些复杂度。客户端需要存储且处理幂等键且实现自动重试机制。开发者在实现和处理 Java lambdas 时需要额外的上下文和必须精确处理。另外,当前的 Orpheus 版本在集中测试中,我们会持续找到问题改进它:重试请求负载匹配,对方案改变和嵌套迁移的改进支持,RPC 阶段限制数据库访问等等
当这些考虑最重要时,Orpheus 如何使得 Airbnb 支付成功呢?因为它的启动,我们对我们的支付在一致性上实现了五个九的 SLA,同时我们的年度支付容量成倍增长
Share
我们已经设计和实现了 Google 文件系统,用于大型分布式数据密集应用程序的可扩展分布式文件系统。它提供运行在廉价商业硬件上的容错,转发高聚集性能给大量客户端
当如以前的分布式文件系统一样共享许多相同的目标,我们的设计由我们的应用程序负载和技术环境观测驱动,当前的及参与的,反应了跟一些早期文件系统假设的标志性分离。这使得我们重新检查传统的选择并探索激进的不同设计点
文件系统成功满足了我们的存储需求。它在 Google 中作为存储平台广泛应用,它使用我们的服务包含需要大型数据集的搜索和开发效能来产生和处理数据。最大的簇提供跨越超过一千台机器上数千个磁盘数百 TB 数据的存储,被数百个客户端并行访问
在本文中,我们呈现文件系统接口扩展设计来支持分布式应用程序,讨论我们设计的许多方面,且报道微观评测和实际使用上的度量
简介
我们设计实现了 Google 文件系统(GFS)来满足 Google 数据处理的快速增长需求。GFS 共享许多跟之前的分布式文件系统相同的目标,比如性能,可扩展性,可靠性和有效性。然而,它的设计由我们的应用程序工作负载和技术环境的关键观测驱动,包含当前的和参与的,反应到跟某些早期文件系统设计假设的标志性不同。我们重新检查传统选择和探讨在设计空间上的激进的不同点
首先,组件故障是规范而不是异常。文件系统包含由廉价商业部件组成的数千个存储机器和被大量客户端机器访问。组件的数量和质量虚拟保证一些在任意时刻会不能工作且一些不能从它们当前的故障中恢复。我们看到由应用程序、操作系统 Bug,人为操作和磁盘故障,内存,连接器,网络和电力供应等引起的问题。因此,常量观测,错误检测,容错和自动恢复必须集成进系统中
其次,传统标准下文件很大。数 GB 的文件很常见。每个文件典型地包含许多应用程序对象比如 Web 文档。当我们与快速增长的数 TB 级数据集工作包含数十亿个对象,管理数十亿个大约 KB 级别文件是笨拙的,即使文件系统支持它。结果,设计假设和参数比如 I/O 操作和块大小不得不重访问
第三,多数文件已添加新数据而不是修改现存数据的方式改动。在文件中随机写实际上不存在。一旦写入,文件是只读的,且经常是串行读。各种数据共享这些特征。一些包含大型仓库数据分析程序会搜索。一些为数据流被应用程序持续产生。一些为压缩数据。一些为一台机器生产的中间结果且在另一台上处理,有可能同时也可能延迟。给定这些大文件的访问范型,添加变成性能优化的核心且原子化保证,而缓存数据在客户端阻塞它的处理
第四,共存的应用程序和文件系统 API 增加整个系统的灵活性。例如,我们释放 GFS 一致性模型来简化文件系统,而在应用程序上不引入过于复杂的负担。我们也引入一个原则添加操作这样多个客户端可同时添加到文件不需要额外的同步操作。这些将在后续章节详细讨论
多个 GFS 簇为不同的目的采用。最大的有超过 1000 个存储节点,超过 300 TB 的磁盘存储和在连续基础上数百个不同机器上客户端负重访问
设计总览
假设
在设计我们需要的文件系统时,我们通过假设提供挑战和机会来引导。我们提及一些关键观测和更详细地展示我们的假设
- 系统构建在许多经常故障的廉价商业组件上。它可常量观测自身且检测,容错和用日常常规来恢复组件故障
- 系统存储适中数量的大文件。我们期望数百万个文件,每个典型的 100 MB 或更大。几 GB 的文件是常见的且应该被高效管理。小文件必须支持,但我们不需要优化它
- 工作负载主要包含两类读:大流读和小的随机读。在大流读中,单个操作典型地读数百个 KB,更通常的是 1 MB 或更多。相同客户端的成功操作通常读取文件的一个连续范围。一个小的随机读典型地读取某偏移下的几 KB。性能敏感的应用程序通常批量且排序它们的小的读取来提升文件的稳定而不是来回读
- 工作负载也有许多大的顺序写数据添加到文件。典型的操作大小跟那些读相似。一旦写入,文件很少修改。在文件中任意位置进行小写入是支持的但不高效
- 系统必须高效实现对多个客户端并行添加内容到文件有良好的语义。我们的文件通常作为生产者消费者队列或多方合并。数百个生产者,每个机器运行一个,将并行添加内容到文件。最小的同步原子化是必须的。文件可延后读,或一个消费者可能同时读文件
- 高带宽支持比低延迟更重要。我们的多数目标应用程序在高速处理数据上有要求,而少量对单个读写有严格的响应时间要求
接口
GFS 提供一个相似的文件系统接口,虽然它没有实现比如 POSIX 那样的标准 API 接口。文件以目录分层组织且由路径名确定。我们支持常见的创建,删除,打开,关闭,读写文件操作
更进一步,GFS 有快照和记录添加操作。快照以廉价方式创建一个文件目录树的备份。记录添加允许多个客户端并行添加数据到相同的文件同时保证每个独立客户端添加的原子性。这用来实现多路合并结果和生产者消费者队列使得许多客户端可在无锁情况下同时添加。我们发现这些类型文件在构建大型分布式应用程序时非常有用。快照和记录添加将在后续章节讨论
架构
一个 GFS 簇包含一个主和多个块服务器,被多个客户端访问。如下图所示。通常是典型的一个商业 Linux 机器运行用户级服务器进程。在同一台机器上运行块服务器和客户端也是很容易的,如果机器资源允许且由运行可能的较脆弱应用程序代码可接受导致的更低的可靠性
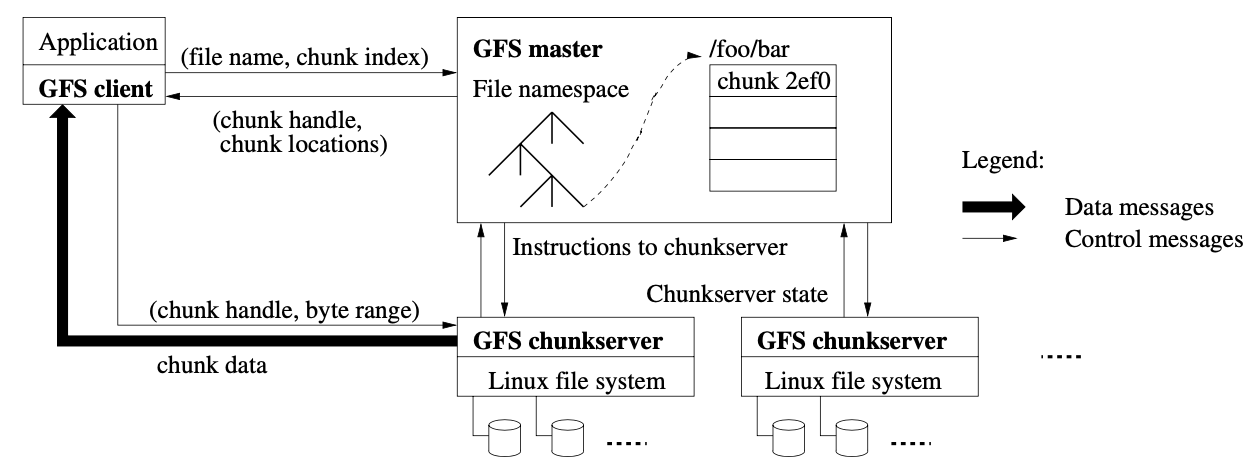
文件被分割成固定大小的块。每块由一个不可修改且全局唯一的 64 位块柄确定,其由主服务器在块创建的时间点上给出。块服务器存储块在本地磁盘上作为 Linux 文件和通过一个块句柄和字节范围读写块数据。对可靠性,每个块复制在多个块服务器上。缺省的,我们存储三个复制节点,用户可为文件命名空间的不同区域指定不同的复制级别
主服务器维护所有文件系统 metadata。这包括命名空间,访问控制信息,从文件映射到块,且块的当前位置。它也控制系统级别活动比如块租赁管理,孤儿块垃圾收集和块服务器之间块迁移。主服务器定期用心跳信息与每个块服务器通信来给出它的指令和收集它的状态
GFS 客户端代码连接每个应用程序实现文件系统 API 和主服务器与块服务器通信来在应用程序收益上读写数据。客户端在 metadata 操作上与主服务器交互,但所有数据容忍通信直接到块服务器。我们不提供 POSIX API 且因此不需要 hook 到 Linux vnode 层
客户端和块服务器都不缓存文件数据。客户端缓存提供的收益很少因为多数应用程序通过大文件流或工作集太大而不能缓存。通过消除缓存一致性问题它们简化客户端和系统(客户端不缓存 metadata)。块服务器不需要缓存文件数据因为块作为本地文件存储且 Linux 的缓存区缓存以保持在内存中频繁访问数据
单个主服务器
单个主服务器极大简化了我们的设计和启动主服务器来使复杂块位置和复制决定使用全局信息。然而,我们必须在读写上最小化包含这样它不会变成瓶颈。客户端不通过主服务器读写文件数据。客户端询问主服务器它应该联系哪个块服务器。它缓存这个信息在限定时间内且对许多顺序操作直接与块服务器交互
让我们对上图的读交互作一个简单的解释。首先,使用固定块大小,客户端传输一个文件名和应用程序在文件块索引中指定的字节偏移。然后,它发送给主服务器一个请求包含文件名和块索引。主服务器用块句柄和复制节点位置来响应。客户端缓存这个信息使用文件名和块索引作为键
客户端然后发送一个请求到一个复制节点,通常是最接近的一个。请求指定块句柄和块中字节范围。后续相同块的读不再需要客户端主服务器交互直到缓存信息过期或文件被重新打开。事实上,客户端典型地在请求中询问多个块且主服务器也包含这些块的信息给它们。这个额外信息使得一些将来的客户端和主服务器交互在实际上没有额外的成本
块大小
块大小是关键设计参数之一。我们选择 64 MB,其比典型的文件系统块大小更大。每个块复制节点在块服务器上作为一个普通 Linux 文件存储且按需扩展。延迟空间分配避免由于内部碎片化而浪费空间,也许这是对大块最大的阻碍因素
一个大块提供几个重要的优势。首先,它减少客户端跟主服务器交互的需要因为读写相同的块只需要一个初始化请求来定位块信息。该缩减对我们的工作负载作用明显因为应用程序大多数串行读写大文件。甚至对小的随机读,对多 TB 工作集客户端可舒适地缓存所有块位置信息。其次,因为一个大块,一个客户端更可能在一个给定块上执行多次操作,它可通过保持一个在扩展时期持久化的到块服务器的 TCP 连接缩减网络负载。第三,它缩减主服务器上 metadata 存储的大小,其带来的好处我们在之后的章节会提及
另一方面,一个大块及延迟空间分配,有它的缺点。一个小文件包含少量块,可能是一个。块服务器存储这些块可能成为蜜罐如果许多客户端访问相同的文件。实际上,蜜罐不是一个主要的问题因为我们的应用程序多数情况下顺序读多个大块文件
然而,蜜罐当 GFS 在批处理队列系统中首次使用时:一个执行作为一个单块文件写入 GFS 且然后同时在数百台机器上开始。一些块服务器存储这个执行被数百个同时发起的请求加载。我们修复这个问题通过存储这样的执行以更高的复制因子并使得批处理队列系统随机开始应用程序开始时间。一个潜在的长期解决方案是允许客户端在这种情况下从其他客户端读取数据
Metadata
主服务器存储三种主要的 metadata:文件和块命名空间,文件到块的映射和每个块复制节点的位置。所有的 metadata 在主服务器内存中。头两种类型(命名空间和文件到块映射)也通过操作日志记录修改持久化保存在主服务器磁盘和复制在远程机器。使用一个日志允许我们来简单可靠地升级主服务器状态且不需担心主服务器崩溃导致的不一致性风险。主服务器不持久化存储块位置信息。它在启动时询问每个块服务器及当一个块服务器加入簇时
-
内存数据结构
因为 metadata 在内存中存储,主服务器操作非常快。更进一步,它容易高效对主服务器在后台周期性扫描它的整个状态。这个周期性扫描用来实现块垃圾回收,当块服务器故障时重复制和块迁移来平衡负载和块服务器间磁盘空间限制
一个潜在的隐患是块数和整个系统被主服务器内存容量限制。实际上这不是一个严重的限制。主服务器每 64 MB 块维护一个少于 64 字节的 metadata。多数块是满的因为多数文件包含许多块,只有最后一个是部分满。相似地,文件命名空间数据对每个文件需要少于 64 字节因为它存储文件名使用前缀压缩
如果需要支持甚至更大的文件系统,添加额外的内存到主服务器的成本相对于得到的简化,可靠性,性能和灵活性来说是一个小的代价
-
块位置
主服务器不持久化块服务器的块记录。它在启动时询问块服务器这些信息。主服务器可保持更新因为它控制所有块的位置和用心跳消息监控块服务器状态
我们最开始尝试在主服务器上持久化保存块位置信息,但我们决定在启动时从块服务器查询数据更简单。这消除了主服务器和块服务器同步问题,块服务器加入离开簇,改变名字,故障,重启等等。在一个簇中有数百台服务器,这些事件经常发生
理解这个设计决定的另一个方式是意识到一个块服务器决定它有什么块。没有必要维护一个一致性信息在主服务器上因为块服务器会导致一个块突然消失或一个操作会重命名一个块服务器
-
操作日志
操作日志包含关键 metadata 改变的历史记录。它是 GFS 的核心。它不仅持久化 metadata 记录,也作为一个逻辑时间线定义并行操作的顺序。文件和块,及它们的版本,唯一并最终由当它们被创建时的逻辑时间确定
因为操作日志很重要,我们必须可靠存储并对使改变对客户端不可见直到 metadata 改变被持久化处理。否则,我们将丢失整个文件系统或最近的客户端操作甚至块服务器的存在。因此,我们在多个远程机器上复制它并只在刷新对应的日志记录到本地和远端磁盘之后才能响应客户端操作。主服务器在刷新前批量一些日志记录因此减少刷新和复制对整个系统吞吐的影响
主服务器通过重放操作日志来恢复它的文件系统状态。为最小化启动时间,我们必须使日志小。当日志增长超过某个大小主服务器检测点它的状态这样它可通过加载本地磁盘上最新的检查点来恢复并只重放检查点之后的日志。检查点是一个压缩 B 树可直接通过内存压缩和使用命名空间查找并不需要额外的分析。这进一步加速恢复和改进有效性
因为构建一个检查点需要花费一些时间,主服务器的内部状态是结构化的,一个新检查点可在不延迟输入修改的情况下创建。主服务器切换到一个新日志文件并在单独线程中创建新检查点。对一个有数百万个文件的簇它可在 1 分钟左右创建。当完成时,它写入本地和远端磁盘
恢复只需要最新完成的检查点和后续日志文件。老的检查点和日志文件可删除,虽然我们保存一些来保障一些灾难事件发生。检查点时发生的故障不影响正确性因为恢复代码检测并跳过不完整的检查点
一致性模型
GFS 有一个松弛的一致性模型支持我们的高分布式应用程序但实现依然简单有效。我们现在讨论 GFS 的保障和它们对应用程序意味着什么。我们也强调 GFS 如何维护这些保障
-
GFS 的保障
文件命名空间的修改(例如文件创建)是原子的。它们被主服务器处理:命名空间加锁保障原子性和正确性;主服务器的操作日志定义一个全局的操作总序
写 记录添加 顺序成功 已定义 定义多处的不一致 并行成功 一致但未定义 定义多处的不一致 故障 不一致 不一致 数据修改后文件范围状态依赖于修改类型,是否成功或失败,是否有并行修改。上表总结了结果。一个文件区域是一致的当所有的客户端将总是看到相同的数据,不管它们从哪个复制节点读取。一个区域在文件数据修改后是定义的当它是一致的且客户端将看到修改被完全写入。并行成功修改使得区域未定义但一致:所有客户端看到相同的结果,但它可能不能反应哪一个修改被写入。典型的,它包含多次修改的迁移碎片。一个失败的修改使得区域不一致(因此也未定义):不同的客户端可在不同的时间看到不同的结果。我们描述我们的应用程序如何区分定义的区域和未定义区域。应用程序不需要进一步区分未定义区域的不同类型
数据修改可为写入和记录添加。一个写入导致数据被写入到应用程序指定文件的偏移上。一个记录添加导致数据(记录)自动只添加一次即使有并发修改,GFS 选择的一个偏移。(相反,一个常规的添加只是在一个偏移写,客户端认为在文件的末尾)。偏移返回到客户端且标记包含记录的定义区域的开始。另外,GFS 可插入空白在记录之间
在一系列成功修改后,修改的文件区域保证为定义的且包含最近修改的数据。GFS 通过这些达到:(a)在所有复制节点上已相同的顺序修改块 (b) 使用块版本信息来检测复制节点是否变脏因为有些块服务器因为宕机丢失修改。脏复制节点向主服务器询问块位置。它们有最早的机会被垃圾收集
因为客户端缓存块信息,它们可在信息被刷新之前从一个脏复制节点读取。这个窗口被缓存条目的超时时间限制,且下一次打开文件,从文件缓存所有块信息。更进一步,因为多数文件为只添加,一个脏复制节点通常返回一个未成熟的块尾而不是脏数据。当一个读者重试且联系主服务器,它立即获得当前块位置
在一个成功修改的长时间后,组件故障可仍然破坏或毁坏数据。GFS 确定故障块服务器通过主服务器和所有块服务器的常规握手且通过 checksum 探测数据破坏。一旦一个问题出现,数据快速从有效的块服务器恢复。一个块不可避免的丢失仅当在 GFS 重处理之前所有它的复制块丢失,典型地在数分钟内。对这样的情况,它变得无效,不是破坏:应用程序接收到清除错误而不是数据破坏
-
应用程序关联
GFS 应用程序可基于为其他目的已实现的一些技术来提供松弛的一致性模型:依赖于添加而不是覆盖,检查点和写自我验证,自我确定记录
实际上所有我们的应用程序通过添加而不是覆盖的形式修改文件。在一个典型的使用中,一个写者产生一个文件从开始到结束。在写了所有数据之后它自动重命名文件到一个最终的文件名或周期性的检查点有多少已写入。检查点也可能包括应用程序级别的 checksum。读者只验证和处理到最新检查点的文件区域,其被称为已定义状态。不管一致性和同步问题,这个处理对我们来说很好。添加非常高效且对应用程序故障更有抵抗力而不是随机写。检查点允许写者重新递增且保持读者处理已成功写入但对应用程序来说尚未完成的文件数据
在另外的典型使用中,许多写者对已合并的结果或作为一个生产者消费者队列并行添加到文件。记录添加的添加至多一次语义保护每个写者的输出。读者处理偶然的 padding 和重复。每个记录被写者保护的额外信息比如检查点准备着这样它的有效性可验证。一个读者可使用 checksum 确定和丢弃额外 padding 和记录碎片。如果它不能容忍偶然的重复(例如,它们会触发非幂等的操作),它可使用记录中唯一的确认 ID 过滤,其经常需要命名响应应用程序条目比如 Web 文档。这些记录 I/O 功能(除了重复删除)在库代码中被我们的应用程序共享且应用到 Google 的其他文件接口实现。这样,相同的记录序列,加上少见的重复,总是转发到记录读者
系统相互作用
我们设计系统来最小化主服务器所有操作。在这个背景下,我们现在描述客户端,主服务器和块服务器如何交互来实现数据操作,原子记录添加和快照
租赁和修改顺序
一个修改是一个操作改变一个块的内容或 metadata 比如一个写入或一个添加操作。每个修改执行在所有块的复制节点上。我们使用租赁来维护一个跨复制节点的一致性修改顺序。主服务器允许一个块租赁到一个复制节点,我们称其为主复制节点。主复制节点对一个块的所有修改取得一个串行顺序。所有复制节点应该修改是跟随这个顺序。这样,一个全局修改顺序被主服务器租赁允许的顺序定义,且主复制节点在一个租赁中分配一个串行数
租赁机制设计用来在主服务器上最小化管理过载。一个租赁有 60 秒的初始超时时间。然而,当块被修改,主复制节点可请求和典型地从主服务器接收扩展。这些扩展请求和允许被优化在主服务器和所有块服务器间常规心跳消息上使用。主服务器可有时尝试在过期前撤回一个租赁(例如,当主服务器想要对正在重命名的文件上禁止修改)。甚至主服务器与一个主复制节点失去联系,它可安全地允许在一个老的租赁过期后给一个新的租赁到另一个复制节点
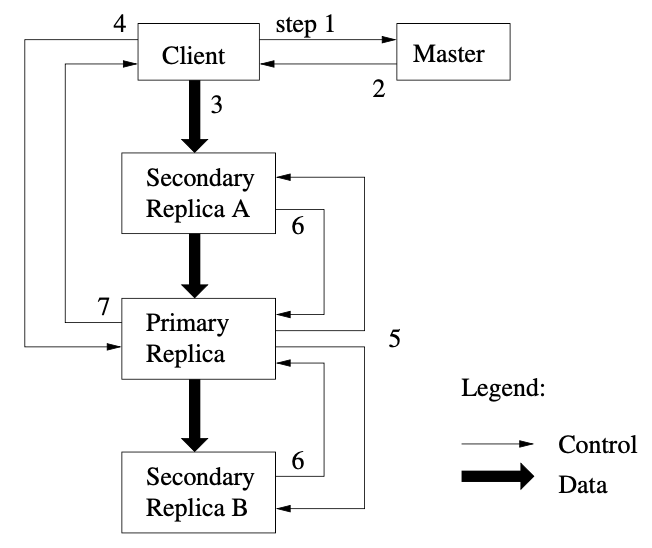
在上图中,我们展示通过如下步骤一个写的控制流程
- 客户端请求主服务器哪个块服务器持有块的当前租赁和其他复制节点的位置。如果还没有租赁,主服务器确保一个复制节点被选择
- 主服务器响应主复制节点的唯一标识和其他复制节点的位置。客户端缓存这个数据为将来修改使用。当主复制节点变得不可达或回复它不再持有租赁时需要再次联系主服务器
- 客户端推数据给所有复制节点。一个客户端可已任意顺序来做这个处理。每个块服务器将存储数据在内部 LRU 缓冲区中直到数据被使用或过期。通过从控制流分离数据流,我们可不关系是否是主复制节点基于网络拓扑来调度繁重的数据流来改进性能
- 一旦所有复制节点被通知到接收了数据,客户端发送一个写请求到主复制节点。请求确认数据已推给所有复制节点。主复制节点分配连续顺序号给它收到的所有修改,可能来自于多个客户端,提供必要的串行。它以串行数字顺序应用修改到它本地的磁盘
- 主复制节点转发写请求到所有复制节点。每个复制节点应用与主复制节点相同的修改顺序
- 所有复制节点响应给主复制节点它们已完成操作
- 主复制节点回复给客户端。发生在任意复制节点的错误统计会报告给客户端。在出现错误时,写操作可能在主复制节点和任意部分其他复制节点上已成功(如果它在主复制节点上失败,它不会分配一个写顺序及出现后续操作)。客户端请求考虑到有失败的情况,且修改区域变成不一致状态。我们的客户端代码处理这样的错误,重试失败的修改。它从写开始到失败重试前会在步骤(3) 到 (7) 做一些尝试
如果一个应用程序写很大或跨越一个块边界,GFS 客户端代码分割它为多次写操作。它们服从所有上述控制流但交替从其他客户端并行操作覆盖写。因此,共享的文件区域从不同的客户端包含碎片,虽然复制节点是确定性的因为独立操作在所有复制节点上以相同的顺序都完全成功了
数据流
我们高效的使用我们的网络分离数据流和控制流。当客户端控制流到主复制节点且所有其他复制节点,数据以流水线形式把块服务器链小心拾起并线性推出。我们的目的是有效利用每个机器的网络带宽,避免网络瓶颈和高延迟链接,且最小化延迟来推送所有数据
为利用每个机器网络带宽,数据沿着块服务器链线性推送而不是以某种其他拓扑(比如树)来分布式处理。这样,每个机器完全的输出带宽被用来尽快传输数据而不是在多个复制节点间被分割
为避免网络瓶颈且高延迟连接(例如,内部交换机链接),每个机器在网络拓扑中对没有接受到的复制节点转发数据到最近的复制节点。假设客户端推数据到块服务器 S1 到 S4。它发送数据到最近的块服务器,比如 S1。S1 转发到最近的块服务器,比如 S2。同样 S2 转发到比如 S3 等等。我们的网络拓扑足够简单距离可由 IP 地址精确估计
最后,我们通过基于 TCP 的流水线数据传输最小化延迟。一旦一个块服务器接收到一些数据,它开始立即转发。流水线对我们特别有用因为我们使用双分链接的交换网络。立即发送数据不缩短接收速度。由于没有网络冲突,传输 B 字节到 R 个复制节点的理想摆动时间是 B/T + RL 当 T 网络吞吐及 L 是两台机器间传输字节的延时。我们的网络链接典型的是 100 Mbps,且 L 远小于 1 毫秒。因此,1 MB 可在 80 毫秒内分发出去
原子记录添加
GFS 提供一个原子添加操作称为记录添加。在传统的写中,客户端指定写数据所在的 offset。并行写到相同的区域不是串行的。区域里可能存在多个客户端的数据碎片。在数据添加时,客户端只指定数据。GFS 原子性的添加数据最多一次(例如,一块连续的字节序)到 GFS 选中的 offset 上并返回 offset 给客户端。这跟 Unix 中以 O_APPEND 模式写文件相似,多个并行写没有竞技条件
记录添加被我们的分布式应用程序重度使用,许多客户端在不同的机器上同时添加数据到相同的文件。客户端需要额外的复杂高昂的同步操作,例如通过一个分布式锁管理器,如果它们用传统的写方式的话。在我们的工作负载中,这样的文件通常作为多写者/单读者队列或包含多个不同客户端的合并结果
记录添加是一种修改且遵循控制流,只是在主复制节点有一些额外的逻辑。客户端推数据到所有复制节点的文件末尾,它发送请求到主复制节点。主复制节点检查是否添加记录到当前块会导致块超出最大大小(64 MB)。如果是,它填充块到最大大小,告诉第二个复制节点且回复客户端操作将在下一个块重试。(记录添加被限制为最多四分之一最大块大小来在可接受范围内保持最坏的碎片情况)如果记录能在最大大小范围内,这是通常的情况,主复制节点添加数据到复制节点,告诉第二个复制节点在某个具体 offset 上写数据,且最终返回成功到客户端
如果一个记录在任意复制节点添加失败,客户端重试操作。结果,复制节点的相同块可能包含不同的数据当复制相同的记录时。GFS 不保证所有复制节点为字节确定的。它只保证数据作为原子操作只写一次。这个属性符合对操作成功报告的简单观测,数据必须写在复制节点某个块的相同 offset 上。进一步,所有复制节点至少在记录结尾且任意更进一步的记录将赋给一个更大的 offset 或不同的块即使一个不同的复制节点变成主复制节点。在我们的一致性保证下,记录添加成功操作的区域是已定义的(因此一致),而干涉的区域是不一致的。我们的应用程序可处理干涉区域,这将在后续章节讨论
快照
快照操作瞬时复制文件或目录树,最小化对修改的干涉。我们的用户使用快照快速创建大数据集的分支拷贝(及拷贝它的拷贝)或检查点查看当前的状态使得之后的提交或回退更容易
像 AFS 一样,我们使用标准写时拷贝技术来实现快照。当主服务器接收到一个快照请求,它首先吊销要快照的文件上块的未完成租赁。这确保任意子顺序对块的写将需要与主服务器一个交互来找到租赁持有者。这将给主服务器一个机会来创建新的块拷贝
在租赁被吊销或过期后,主服务器记录操作到日志。它然后应用这个日志记录它的内存状态,复制源文件或目录树的 metadata。新创建的快照文件指向相同块作为源文件
第一时间一个客户端想要写一个块 C 在快照操作之后,它发送一个请求到主服务器来找到当前租赁持有者。主服务器注意到对块 C 的引用大于 1。它延迟回复客户端请求且取一个新块处理 C。然后询问每个块服务器有一个 C 的当前复制节点创建了一个新块 C’。通过在相同的块服务器上创建新块作为源,我们确保数据可被本地拷贝,而不是网上(我们的磁盘三倍于我们的 100 MB 以太网带宽)。基于此,请求处理对任意块都不困难:主服务器允许一个复制节点在新块 C’ 上的一个租赁,且回复到客户端,客户端可正常写当前块,甚至不知道它是从一个现存的块上创建的
主服务器操作
主服务器执行所有命名空间操作。另外,它管理系统的块复制节点:它发出位置决定,创建新块且因此复制,和协调各种系统级活动来保持块被完整复制,平衡所有块服务器的负载,且回收利用未使用的存储
命名空间管理和加锁
许多主服务器操作需要很长的时间:例如,一个快照操作要吊销所有块服务器所有快照上块的租赁。我们不想要被快照延迟其他主服务器操作。因此,我们允许多个操作被激活且使用命名空间区域上的锁来确保合适的串行化
不像许多传统文件系统,GFS 没有一个每目录数据结构列出所有目录的文件。也不支持对文件或目录的别名(例如,Unix 系统中硬和软链接)。GFS 逻辑上呈现它的命名空间作为一个查找表映射所有路径名到 metadata。对前缀压缩,这个表可有效在内存中呈现。命名空间树上的每个节点(一个绝对路径文件名或一个绝对路径目录名)有一个读写锁
每个主服务器操作在它运行时请求一系列锁。典型的,如果它包含 d1/d2…/dn/leaf,它将在目录名 d1, /d1/d2, …, /d1/d2../dn/leaf 上获取读写锁。注意 leaf 可能为一个文件或目录
我们现在展示这个锁机制如何防止一个文件 /home/user/foo 被创建同时 /home/user 被快照到 /save/user。快照操作需要读锁在 /home 和 /save 上,和 /home/user 和 /save/user 上的写锁,及 /home/user/foo 的写锁。两个操作将被串行化因为它们试图获得 /home/user 的锁。文件创建不需要父目录的写锁,不需要保护数据结构的修改。读锁保护父目录不被删除
这个锁机制的一个好的属性是它允许在相同目录下并行修改。例如,多个文件创建可在相同目录下同时处理:每个请求一个目录名的读锁。读锁防止目录被删除、重命名或快照。文件的写锁防止对相同的文件名重复创建
因为命名空间有许多节点,读写锁对象延迟创建且不使用时只删除一次。锁需要一个一致总序来防止死锁:它们首先以命名空间层为序,相同层用字母序
复制节点位置
一个 GFS 簇高分布在更多的层。典型地有数百台块服务器扩散到许多机器支架。这些块服务器被从相同或不同支架上的数百个客户端访问。在不同支架上的两台机器通信可能跨越一个或多个交换机。另外,进出支架的带宽可能小于支架上所有机器聚合的带宽。多层分布对分布式数据唯一的挑战扩展性,可靠性和有效性
块复制节点位置策略服务两个目的:最大化数据可靠性和有效性,和最大化网络带宽使用。这两点不足够跨机器扩散复制节点,只保证防止磁盘或机器故障和完全利用每个机器的带宽。我们也必须跨支架扩散块复制节点。这确保块的一些复制节点在整个支架被破坏或下线(例如,由于共享资源故障比如一个网络交换机或电力)。它也意味着流量,特别是读,对一个块可以利用多支架的聚合带宽。另一方面,写流量会到多个支架
创建,重复制和重平衡
块复制节点创建有三个原因:块创建,重复制和重平衡
当主服务器创建 1 个块,它选择把初始化的复制放的位置。它包含几个因素:(1)我们想要放置在块服务器的一个新复制节点上来平均一般化磁盘空间利用。在一段时间后这将使跨块服务器平均利用磁盘空间。(2)我们想要限制在每个块服务器上最新创建的数量。虽然创建本身很廉价,它可靠地预测马上会出现的重度写流量因为块被写需求创建,且在我们的添加一次多次读工作负载上一旦它们被完全写入会变成只读(3)如上面讨论的,我们想要跨支架扩展块复制节点
当有效的复制节点数量在用户指定的目标之下时主服务器重复制一个块。有几个原因会导致发生:一个块服务器变成无效,它报道它的复制节点可能崩溃,由于错误导致它的磁盘被禁止或复制节点目标增长。每个块基于几个因素需要被优先重复制。一个是它距它的复制目标的差距。例如,我们给出一个更高的优先级到一个丢失了两个复制节点的块,丢失了一个复制节点的块优先级会比它低。另外,我们更喜欢重复制活跃文件的块而不是最近删除文件的块。最后,为最小化故障对运行程序的影响,我们优先处理那些会阻碍客户端程序的块
主服务器拾起最高优先级块且克隆它,指导一些块服务器从一个现存有效的复制节点拷贝块数据。新的复制节点的位置对那些创建来说相似:平衡磁盘空间利用,限制在任意单块服务器上有效的拷贝数且跨支架扩散复制节点。为保持克隆流量影响客户端流量,主服务器限制对簇和每个块服务器限制活动的克隆操作数量。另外,每个块服务器通过射线读请求到源块服务器来限制每个克隆操作对带宽的使用
最后,主服务器定期重平衡复制节点:检查当前复制节点分布和让磁盘空间和保持平衡来移动复制节点。通过这个处理,主服务器逐渐填充一个新块服务器而不是让块服务器有大量的新块和大的写流量。对新复制节点的位置规则相似。另外,主服务器也选择删除哪些复制节点。一般情况下,它更愿意选择移除低于平均水平空闲磁盘空间的块服务器这样来平均磁盘空间使用
垃圾收集
在文件被删除后,GFS 不立即重申有效的物理空间。它只延迟在常规文件和块层垃圾收集处理之后。我们发现这样使得系统更简单和更可靠
-
机制
当一个文件被应用程序删除,主服务器立即记录删除操作。然而不会立即重申资源,文件重命名为一个隐藏文件名包含删除时间戳。在主服务器对文件系统命名空间的常规扫描时,它删除任意这样的隐藏文件如果存在超过三天(内部配置)。然后,文件还能在新文件名下被读取且被取消删除通过重命名到正常文件名。当一个隐藏文件从命名空间中删除,它的 metadata 被移除
在一个相似的块命名空间常规扫描中,主服务器确定孤儿块(例如,没跟任意文件关联的)和删除这些块的 metadata。在一个对主服务器的常规心跳消息中,每个块服务器报道块的一个子集,且主服务器用已不在主服务器的 metadata 的块回复。块服务器自由地删除这样的块的复制
-
讨论
虽然分布式垃圾收集是一个困难的问题需要复杂的解决方案,在我们的例子中它很简单。我们可轻松地确定所有块的引用:它们在主服务器中维持了文件到块的映射。我们也可轻松确定所有块复制:它们是每个块服务器上特定目录下的 Linux 文件。任意这样的复制对于不知道的主服务器来说是垃圾
垃圾收集处理相对积极删除对存储重声明有几个优势。首先,它在组件故障常见的大扩展分布式系统场景下简单且可靠。块创建可能在一些块服务器上成功,主服务器不需要知道其存在。复制节点删除消息可能被丢失,且主服务器必须记住并在跨故障时重新发送,包括它自己的和块服务器的。垃圾收集提供一个统一且可依赖的方式来清理不知道是否有用的复制节点。其次,它合并存储重声明到主服务器的常规后台活动,比如命名空间的常规扫描和块服务器的握手。这样,它被批处理的方式完成且成本被摊还。更进一步,它只在主服务器相对清闲时处理。主服务器可更多地响应客户端请求。第三,重声明存储的延迟提供一个事故,不可逆转删除的安全网
在我们的经验中,主要的缺点是延迟在存储紧张时有些妨碍用户效果。应用程序重复地创建和删除临时文件不能立刻重新使用这些存储。我们通过利用如果一个删除文件是再次直接删除则存储重声明来处理这个问题。我们也允许用户应用不同的复制节点和重声明策略到不同的命名空间部分。例如,用户可指定一些目录树的文件中所有块为没有复制节点的存储,且任意删除文件将从文件系统状态中不可逆地删除
脏复制节点检测
块复制节点可能变脏因为一个块服务器故障和当它宕机时丢失了对块的修改。对每个块,主服务器维护一个块版本号来区分更新和脏复制节点
当主服务器允许一个块上新的租赁,它增加块版本号且通知更新复制节点。主服务器和这些复制节点所有记录新版本号到它们的持久化状态。这发生在任意客户端被通知且因此在它们写块之前。如果另一个复制节点当前无效,它的块版本号将会落后。主服务器将探测到这个块服务器有一个脏复制节点当块服务器重启且报道它的块集合及其版本号时。如果主服务器看到一个版本号大于记录的版本号,主服务器假设它已故障当允许租赁时且用高版本的进行覆盖
主服务器在它的常规垃圾收集时移除脏复制节点。在那之前,它高效地考虑一个脏复制节点并不存在当它回复客户端块信息请求时。作为另一个安全保障,主服务器当它通知客户端哪个块服务器持有块的租赁或当它指导一个块服务器在克隆操作中从另一个块服务器读取块时包含块版本号。客户端或块服务器在执行操作时检测版本号这样确保总是访问的最新的数据
容错和诊断
我们的主要挑战之一是设计系统处理频繁地组件故障。组件的数量和质量使得问题比异常更常见:我们不能完全相信机器,或我们不能完全相信磁盘。组件故障可导致一个无效的系统或有问题的数据。我们讨论如何应对这些挑战和我们构建的系统工具在问题发生时诊断问题
高有效性
在一个 GFS 簇中的数百个服务器中,一些在任意时间可能变得无效。我们保持整个系统的高有效通过两个简单有效的策略:快速恢复和复制
-
快速恢复
主服务器和块服务器被设计为能恢复它们的状态及无论它们如何宕机都能在数秒内启动。事实上,我们不区分正常和异常宕机;服务器通过杀死进程经常关机。客户端和其他服务器体验为一个小打嗝当请求超时,重连来重启服务器和重试时
-
块复制
每个块在不同的支架的多个块服务器上复制。用户可对不同的文件命名空间部分指定不同的复制水平。缺省是 3。主服务器克隆现有的复制节点在块服务器下线或 checksum 检测到冲突时确保每个块完整被复制。虽然复制节点服务得很好,我们也探索其他跨服务器冗余的方式比如对我们增加的只读存储请求进行条带或擦除代码。我们期望在我们非常松散的系统中实现这些更多的复杂冗余方案是挑战且可管理的,因为我们的流量主要由添加和读组成而不是随机写
-
主服务器复制
主服务器状态为可靠性要求是可复制的。它的操作日志和检查点在多个机器上被复制。一个状态修改被考虑为在它的日志记录被刷新到本地磁盘和所有主复制节点后才能提交。为简单化,一个主进程负责所有修改如同一个后台活动比如垃圾回收在内部改变系统。当它故障时,它可重启。如果它的机器或磁盘故障,GFS 之外的监控基础设施开始一个新的主进程带复制操作日志。客户端只使用主服务器的别名(例如,gfs-test),其是一个 DNS 别名可在主服务器重定位到另一台机器时改变
更进一步,影子主服务器提供对文件系统的只读访问甚至当主服务器宕机时。它们是影子,不是镜像,它们可直接落后主服务器,典型的数秒时间。它们加强了对文件的读有效性使得有效的修改或应用程序对脏数据不敏感的场合。事实上,因为文件内容是从块服务器上读的,应用程序不监控脏文件内容。其可以是文件 metadata 变脏,如果目录内容或访问控制信息
为确保它被通知,一个影子主服务器读取增长操作日志的复制和作为主服务器一样应用相同序列的改变到数据结构。和主服务器一样,它在启动时推块服务器(不频繁)来定位块复制节点和互相间交互频繁的握手消息来监控它们的状态。它只依赖主服务器来从主服务器的决定对复制位置更新结果来创建和删除复制节点
数据集成
每个块服务器使用 checksum 来检测存储数据的冲突。给定一个 GFS 簇有数千个磁盘在数百台机器上,它会遭遇磁盘故障导致数据冲突和读和写路径丢失。我们可使用其他复制块来恢复冲突,但通过跨块服务器比较复制来检测冲突是不现实的。更进一步,有分歧的复制节点是合逻辑的:GFS 的修改语义,如之前讨论的原子添加,不保证确定性的复制。因此,每个块服务器必须通过维护 checksum 独立验证它自己的拷贝集成
一个块分成 64 KB 的小块。每个小块有一个 32 位 checksum。像其他 metadata 一样,checksum 保存在内存中且独立于数据持久化存储在日志中
对读,块服务器验证覆盖读的数据块的 checksum 在返回数据到请求者之前,请求者可以是一个客户端或一个块服务器。因此块服务器将不会广播冲突到其他机器。如果一个小块不匹配记录的 checksum,块服务器返回一个错误到请求者且报道不匹配给主服务器。在响应中,请求者将从其他复制节点读,同时主服务器将从其他复制节点克隆块。之后一个有效的新复制节点定位后,主服务器指导块服务器报道一个不匹配来删除它的复制
checksum 对读性能的影响很小。因为大多数我们的读只扩展到几个块,我们需要读或 checksum 相对小数量的额外数据。GFS 客户端代码进一步通过在 checksum 块边界对齐读来缩减这个过载。在块服务器上 checksum 的查找和比较没有任何 I/O 操作,且 checksum 计算可被 I/O 覆盖
checksum 计算被高度优化添加到块的最后因为它占据我们的工作负载。我们只增加更新最后部分 checksum 块的 checksum,且对添加的新 checksum 块计算一个 checksum。甚至最后部分的 checksum 块已冲突且我们尚未检测到,新的 checksum 值不匹配存储数据,且冲突将在下次读时被检测
相反地,如果一个写覆盖块的现存区域,我们必须先读和验证被覆盖区域,然后执行写,最后计算记录新的 checksum。如果我们不先验证,新的 checksum 将隐藏冲突
在空闲期间,块服务器可扫描和验证未激活块的内容。这允许我们检测很少被读的块的冲突。一旦冲突被检测,主服务器可创建一个新非冲突复制节点且删除冲突节点。这防止一个非激活但有冲突的块复制节点愚弄主服务器,认为它有足够有效的块复制节点
断工具
扩展和详细的诊断日志帮助对不可度量的问题隔离,调试和性能分析,且只付出很小的代价。没有日志,就难以理解机器间临时的,非可重复的交互。GFS 服务器产生诊断日志记录许多重大事件(比如块服务器上线下线)和所有 RPC 请求和回复。这些诊断日志可自由删除不影响系统的正确性。然而,我们在空间允许的情况下尽量保留这些日志
RPC 日志包含精确的请求和响应,除了文件数据的读写。通过匹配请求和响应和验证不同机器上的 RPC 记录,我们可重构整个交互历史来诊断一个问题。日志也用于在本地测试和性能分析中的追踪
日志的性能影响很小(相比与收益)因为这些日志串行并异步写。最近的事件也保留在内存中且对连续在线监控有效
测量
在本节中,我们展现一些微观评测来阐述 GFS 架构和实现的瓶颈和 Google 中实际使用的簇的一些数字
微观评测
我们在一个 GFS 上度量性能包含一个主服务器,两个主复制节点,16 个块服务器和 16 个客户端。注意这个配置是为了易于测试。典型的簇有数百个块服务器和数百个客户端
所有机器配置为 dual 1.4 GHz PIII 处理器,2 GB 内存,两个 80 GB 5400 rpm 磁盘和一个 100 Mbps 双工以太网连接到一个 HP 2524 交换机。所有 19 个 GFS 服务器机器连接到一个交换机,且所有 16 个客户端机器连接到另一个交换机。两个交换机有一个 1 Gbps 连接相连
-
读
N 个客户端同时从文件系统中读取。每个客户端读取从一个 320 GB 的文件集合随机读取选择的 4 MB 范围。重复 250 次这样每次读取 1 GB 的数据。块服务器一共有 32 GB 内存,这样我们期望最多在 Linux 缓冲区缓存中最多有 10% 的命中率
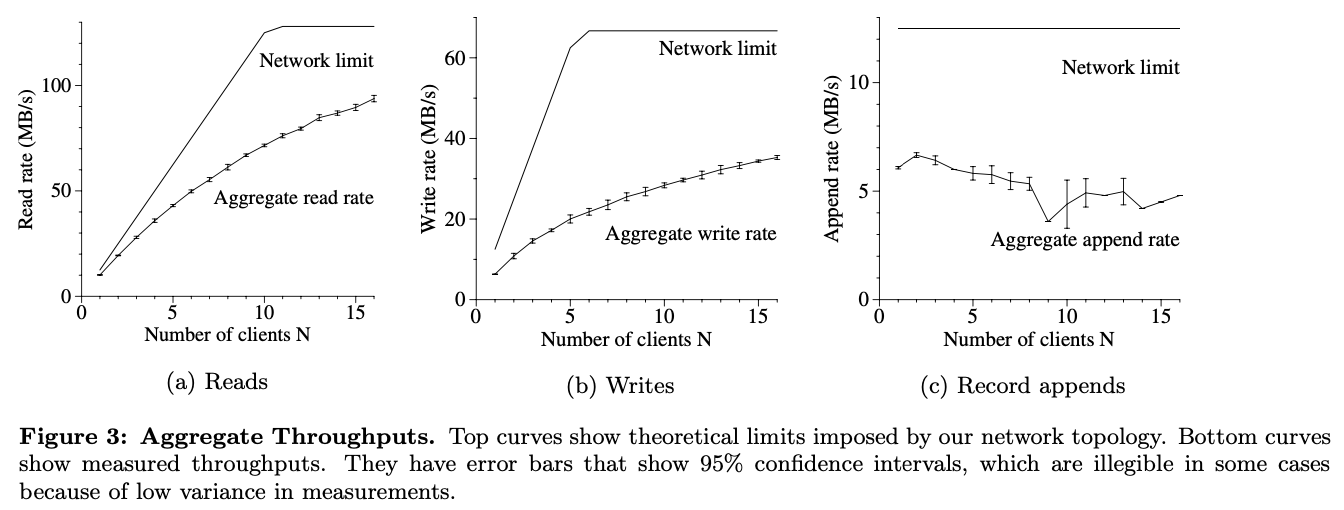
上图(a)显示了对 N 个客户端聚集读速度和它的理论限制。在 1 Gbps 的交换机间链接中限制高峰在 125 MS/s,或当它的 100 Mbps 网络接口完了时为每客户端 12.5 MB/s。观测到读速度是 10 MB/s,或 80% 的每客户端限制,当客户端在读时。聚集读速度达到 94 MB/s,大约 75% 的 125 MB/s 的链接限制,对 16 个读者,大约每个客户端 6 MB/s。效率从 80% 降到 75% 因为读者数量的增加,这样降低多个读者从相同的块服务器同时读的概率
-
写
N 个客户端同时写到 N 个不同的文件。每个客户端以一系列 1 MB 的写写 1 GB 数据到新文件。聚合写速度和它的理论限制在上图(b)中。速度稳定在 67 MB/s 因为我们需要写每个字节到 16 个块服务器中的 3 个,每个输入连接在 12.5 MB/s
一个客户端的写速度是 6.3 MB/s,大概是限制的一半。主要的问题在我们的网络栈。它没有很好的与我们用来推数据到块复制节点的流水线方案交互。从一个复制节点广播数据的延迟到另一个复制节点减少了整个写速度
16 个客户端聚集写速度能达到 35 MB/s,是理论值的一半。在读的情况下,当客户端数量增加时,它变成多个客户端同时写到相同的块服务器。更进一步,16 个写者的冲突比 16 个读者的要大得多,因为每个写包含三个不同的复制节点
写比我们想象的要慢。实际上这不是一个主要的问题因为虽然看起来它增加了单个客户端的延迟,它对系统给大量客户端的聚集写带宽转发没有太大的影响
-
记录添加
上图(3)显示了记录添加性能。N 个客户端同时添加到一个文件。性能被块服务器存储文件最新块的网络带宽限制,独立于客户端数量。它开始时对一个客户端是 6.0 MB/s 且对 16 个客户端降到 4.8 MB/s,大多是由于冲突和不同客户端的网络传输速度的方差
我们的应用程序趋于并行产生多个这样的文件。即 N 个客户端同时添加到 M 个共享文件,N 和 M 都是数十个或数百个。因此,块服务器网络冲突在我们的实验中实际上不是个显著的问题因为一个客户端在写一个文件时可获得进展当块服务器对另一个文件忙碌时
真实世界中的簇
我们现在检测使用在 Google 中的两个簇作为代表。簇 A 用来做对一百个工程师的常规研究和发展。一个典型的任务是由一个人初始化并运行数小时。它读取数 MB 或 TB 的数据,转换或分析,且写结果到簇中。簇 B 主要用来处理生产环境数据。任务长时连续产生且处理数 TB 数据集而很少有人工干预。在这两个事例中,一个任务包含许多机器多个处理器同时读写许多文件
-
存储
簇 A B 块服务器 342 227 有效磁盘空间 72 TB 180 TB 已使用磁盘空间 55 TB 155 TB 文件数 735 k 737 k 死亡文件数 22 k 232 k 块数 992 k 1550 k 块服务器上的 Metadata 13 GB 21 GB 主服务器上的 Metadata 48 MB 60 MB 如上表前 5 项条目所示,两个簇都有数百个块服务器,支持 TB 级磁盘空间,且没有完全满。已使用空间包含所有的块复制节点。所有的文件复制三次。因此,簇分别存储 18 TB 和 52 TB 的数据
两个簇有相似的文件数,B 有更大比例的死亡文件数,即文件已删除或被其存储还没有被重声明的一个新版本替代。它也有更多的块因为它的文件更大
-
Metadata
聚集的块服务器有数十 GB 的 metadata,64 KB 用户数据块的 checksum。在块服务器上保存的唯一其他 metadata 是块版本号
保存在主服务器上的 metadata 更小,只有 MB 级别,平均每文件 100 字节。这允许我们假设主服务器的内存大小在实际上不会限制系统的容量。多数每文件 metadata 是以前缀压缩形式存储的文件名。其他 metadata 包含文件拥有者关系和权限,映射文件到块,且每个块的当前版本。另外,对每个块我们存储当前复制位置和一个引用统计来实现写拷贝
每个独立的服务器,块服务器和主服务器,只有 50 - 100 MB 的 metadata。因此恢复很快:它只花费数秒钟来从磁盘读 metadata 在服务器能够响应查询前。然而,主服务器有时卡顿一段时间 - 典型的 30 到 60 秒 - 直到它获取了所有块服务器上的块位置信息
-
读写速度
簇 A B 读速度(最近一分钟) 583 MB/s 380 MB/s 读速度(最近一小时) 562 MB/s 384 MB/s 读速度(从启动开始算) 589 MB/s 49 MB/s 写速度(最近一分钟) 1 MB/s 101 MB/s 写速度(最近一小时) 2 MB/s 117 MB/s 写速度(从启动开始算) 25 MB/s 12 MB/s 主服务器操作数(最近一分钟) 325 次/s 533 次/s 主服务器操作数(最近一小时) 381 次/s 518 次/s 主服务器操作数(从启动开始算) 202 次/s 347 次/s 上表显示各种时间周期的读写速度。两个簇都被测量了一周(簇最近被重启来升级到 GFS 的新版本)
平均写速度小于 30 MB/s 因为重启的缘故。当我们使用这些测量,B 在写活动爆发时产生大约 100 MB/s 的数据,产生一个 100 MB/s 的网络负载因为写广播到三个复制节点
读速度比写速度高很多。总的工作负载包含更多的读。两个簇都在重读活动中。特别的,A 维持一个持续一周的 580 MB/s 的读速度。它的网络配置可支持 750 MB/s,这样它能有效利用它的资源。簇 B 可支持 1300 MB/s 的读峰值,但它的应用程序只使用 380 MB/s
-
主服务器负载
上表也显示了发送到主服务器操作的速度大概在每秒 200 到 500 操作数。主服务器很容易保存这个速度,且因此对这些工作负载不会成为瓶颈
在 GFS 的早期版本中,主服务器对某些工作负载偶尔会成为瓶颈。它花费大部分时间顺序扫描大目录(包含数百数千个文件)来查找特定文件。我们因此改变主服务器数据结构来有效地在命名空间中二分查找。现在也容易支持每秒数千个文件。如果需要,我们可通过在命名空间数据结构之前放名字查找缓存来加速
-
恢复时间
在一个块服务器故障之后,一些块将变得缺少复制且必须克隆到恢复它们复制的水平。恢复所有这样的块需要的时间依赖于资源总数。在我们的实验中,我们杀死 B 簇中一个块服务器。这个块服务器有大约 15000 个块包含 600 GB 的数据。为限制对运行中应用程序的影响且提供误差来调度决定,我们缺省的参数限制这个簇到 91 个并行克隆(块服务器数量的 40%)每个克隆操作允许消耗最多 6.25 MB/s(50 Mbps)。所有块在 23.2 分钟内恢复,有效的复制速度为 440 MB/s
另一个实验中,我们杀死两个块服务器,每个服务器有大约 16000 块和 600 GB 的数据。这两个故障缩减了 266 块只有一份复制。这 266 块已一个更高的优先级被克隆,且所有在 2 分钟内以至少两倍的速度复制恢复,这样使簇可容忍另一台块服务器故障而不导致数据丢失
工作负载分解
本章节中,我们呈现一个在前面章节没提及的两个 GFS 簇间比较的详细工作负载分解。X 簇用来研究和开发,Y 簇用来生产数据处理
-
方法和警告
这些结果只包含客户端引发的请求这样反映我们的应用程序对文件系统产生的工作负载。它们不包括服务器间请求携带的客户端请求或内部后台活动,比如转发写或重平衡
I/O 操作的统计基于记录在 GFS 服务器上的事实 RPC 请求地启发式重构。例如,GFS 客户端代码可分解一个读为多个 RPC 来增加并行性。因为我们的访问范型高度规格化,我们期望任何错误都被注意到。通过应用程序直接日志可提供更精确地数据,但它不可能重编译且重启数千个运行的客户端来这么做且笨拙地从这些机器上收集结果
需小心不能从我们的工作负载中推广。因为 Google 完全控制 GFS 和它的应用程序,应用程序趋于协同 GFS,且 GFS 是为这些应用程序设计的。这样的相互影响在一般应用程序和文件系统之间也存在,但在我们的例子中影响更大
-
块服务器工作负载
操作 读 写 记录添加 簇 X Y X Y X Y 0K 0.4 2.6 0 0 0 0 1B..1K 0.1 4.1 6.6 4.9 0.2 9.2 1K..8K 65.2 38.5 0.4 1.0 18.9 15.2 8K..64K 29.9 45.1 17.8 43.0 78.0 2.8 64K..128K 0.1 0.7 2.3 1.9 < .1 4.3 128K..256K 0.2 0.3 31.6 0.4 < .1 10.6 256K..512K 0.1 0.1 4.2 7.7 < .1 31.2 512K..1M 3.9 6.9 35.5 28.7 2.2 25.5 1M..inf 0.1 1.8 1.5 12.3 0.7 2.2 上表显示操作大小的分布。读大小显示为一个两模型分布。小型的读操作(64 KB 以下)来自于查找敏感的客户端在大文件中查找小块数据。大读(超过 512 KB)是对整个文件长顺序读取
在簇 Y 中一个显著数量的读返回空数据。我们的应用程序,特别是那些生产系统,经常使用文件作为生产者消费者对列。生产者并行添加到一个文件,消费者读文件末尾。偶然地,当消费者的速度超过生产者时没有数据返回。簇 X 显示这种情况较少,因为它通常用于短期数据分析任务而不是长期分布式应用程序
写大小也展示为一个两模型分布。大型写(超过 256 KB)典型地返回写者的缓存结果。写者缓存较少数据,更多检查点或同步,或小型写(小于 64 KB)的数据
对记录添加,簇 Y 看到一个比簇 X 的大记录添加的一个更大的百分比,因为我们的生产系统簇 Y,对 GFS 更激进
操作 读 写 记录添加 簇 X Y X Y X Y 1B..1K < .1 < .1 < .1 < .1 < .1 < .1 < .1 < .1 1K..8K 13.8 13.9 < .1 < .1 < .1 0.1 8K..64K 11.4 9.3 2.4 5.9 2.3 0.3 64K..128K 0.3 0.7 0.3 0.3 22.7 1.2 128K..256K 0.8 0.6 16.5 0.2 < .1 5.8 256K..512K 1.4 0.3 3.4 7.7 < .1 38.4 512K..1M 65.9 55.1 74.1 58.0 .1 46.8 1M..inf 6.4 30.1 3.3 28.0 53.9 7.4 上表显示在各种大小的操作中数据传输的总数。对所有类型的操作,更大的操作(超过 256 KB)一般占据主要的数据传输。小读(小于 64 KB)传输小但有个显著的比例因为随机查找工作负载
-
添加与写
记录添加在我们的生产系统中重度使用。对簇 X,写和记录添加的字节传输比例是 108:1,操作数比例是 8:1。对簇 Y,分别为 3.7:1 和 2.5:1。更进一步,这些比例建议对这两个簇记录添加都比写占比更大。对簇 X,然而,在测量阶段记录添加的使用是非常低的且结果倾向于特殊缓存大小选择的一个或两个应用程序
如期望的,我们的数据修改负载是记录添加占统治地位。我们度量主复制节点上数据写的总数。这次估计情况是一个客户端故意覆盖写之前的写数据而不是添加新数据。对簇 X,写的字节占比在 0.0001% 以下,操作数占比在 0.003% 以下。对簇 Y,两个比例都是 0.05%。虽然很小,但依然比我们期望的要高。多数这些覆盖写来源于客户端重试,由于错误或超时
-
主服务器工作负载
簇 X Y 打开 26.1 16.3 删除 0.7 1.5 找定位 64.3 65.8 找租赁持有者 7.8 13.4 找匹配的文件 0.6 2.2 所有其他的组合 0.5 0.8 上表显示主服务器请求类型的分割。多数请求为块定位读和租赁持有者信息
簇 X 和 Y 有明显不同的删除请求数因为 Y 存储生产数据集会重生成和用新版本替代。部分这些不同进一步隐藏在打开请求的不同因为一个老版本的文件可能被写打开而间接删除
找匹配的文件是一种支持 “ls” 和相似文件系统操作的范型。不像主服务器的其他请求,它可处理命名空间的大部分且变得开销大。簇 Y 更多因为自动数据处理任务趋于检查文件系统部分来理解全局应用程序状态。相反地,簇 X 的应用程序被用户更多直接控制且通常知道所有需要的文件名
经验
在构建和开发 GFS 中,我们有各种问题的经验,一些是操作上的一些是技术上的
最初,GFS 在我们的生产系统中构思为一个后台文件系统。随着时间推移,其使用包含了研究和开发任务。它开始于仅支持权限和配额但现在包含这些基本的形式。当生产系统被训练和控制,用户有时候却没有。更多的基础设施需要用户间的交互
一些我们最大的问题是磁盘和 Linux 相关的。我们的许多磁盘声称 Linux 驱动支持一系列 IDE 协议版本但事实上只支持较新的。因为协议版本相似,这些驱动多数能工作,但偶尔会不匹配导致驱动和内核对驱动的状态不一致。这导致数据在内核中崩溃。这个问题激起我们使用 checksum 来检测数据正确性,同时并行地我们修改处理这些协议的不匹配
更早期我们对 Linux 2.2 内核的 fsync() 成本有一些问题。它的成本跟文件的大小成比例而不是修改部分的大小。这对我们大的操作日志特别是在我们实现检查点之前是一个问题。我们对此一段时间使用同步写并最终迁移到 Linux 2.4
另一个 Linux 问题是一个读写锁任意线程在地址空间中当从磁盘(读锁)到页面或在 mmap() 调用(写锁)修改地址空间时必须持有。我们看到在资源瓶颈或零星地硬件故障引起的在我们的系统轻负载时短暂地超时现象。最终,我们发现当磁盘线程在之前页面缓存映射数据时这个单锁阻塞主网络线程映射新数据到内存。因为我们主要限制为网络接口而不是内存拷贝带宽,我们通过替换 mmap() 为 pread() 以一个额外拷贝的代价解决这个问题
尽管有些偶发问题,Linux 代码的有效性帮助我们节省了时间并探索理解了系统行为。当合适时,我们改进内核和在开源社区分享这些改变
相关工作
和其他大型分布式文件系统比如 AFS 一样,GFS 提供一个位置独立命名空间可以让数据因负载平衡或容错而暂时移动。不像 AFS,GFS 为了转发聚集性能和增加容错而扩展文件数据到多个存储服务器,这有些像 xFS 和 Swift
因为磁盘相对便宜且复制比复杂的 RADI 处理简单,GFS 当前只对冗余使用复制且比 xFS 和 Swift 消耗更多的存储
跟 AFS,xFS,Frangipani 和 Intermezzo 不同的是,GFS 不提供任何文件系统接口下的缓存。我们的目标工作负载在单个应用程序运行时很少重使用因为它们要么为一个大型数据集流或随机搜索且每次读少量数据
一些分布式文件系统比如 Frangipani,xFS,Minnesota 的 GFS 和 GPFS 去掉了中心服务器且依靠分布式算法来实现一致性和管理。我们使用中心化处理来简化设计,增加它的可靠性和获得灵活性。特别地,一个中心化主服务器使得实现复杂块位置和复制策略因主服务器有大多数相关信息和控制如何改变而更容易。我们通过保持主服务器状态下小和在其他机器上完全复制来处理容错。扩展性和高有效性(对读)通过我们的影子主服务器机制提供。更新主服务器状态通过添加到一个写追加文件来持久化。因此我们可适配一个主拷贝方案比如 Harp 来提供带强一致性保证的高有效性
我们处理了一个跟 Lustre 相似的问题,转发聚集性能到大量客户端。然而,我们显著简化了问题,聚焦在我们应用程序的需求上而不是构建一个 POSIX 兼容的文件系统。另外,GFS 假设大量不可靠组件和容错是我们设计的核心
GFS 跟 NASD 架构很像。NASD 架构基于网络磁盘驱动,GFS 使用商业机器作为块服务器,以 NASD 作为原型。不像 NASD 的是,我们的块服务器使用懒分配固定大小块而不是变长对象。另外,GFS 实现生产环境下的特性比如重平衡,复制和恢复
不像 Minnesota 的 GFS 和 NASD,我们不查找修改存储设备的模型。我们聚焦于在现存商业组件上处理每日在复杂分布式系统下的数据处理需求
生产者消费者对列在处理一个相似问题时作为一个分布式对列出现在 River 上,现在作为原子记录添加而启动。River 使用基于内存的对列跨机器分布且小心控制数据流,GFS 使用一个持久化文件由许多生产者并行添加。River 模型支持 m 到 n 的分布式对列但缺少对持久化存储的容错,但 GFS 只支持 m 到 1 的高效对列。多个消费者可读同一个文件,但它们必须协调分区输入负载
总结
GFS 展示了在商业硬件上支持大规模可扩展数据处理工作负载。一些设计决定特别针对我们独有的设置,许多应用到有相似大规模和成本意识的数据处理任务上
我们开始基于我们当前参与的应用程序工作负载和技术环境的假设下来重新检查传统的文件系统。我们观察到在设计空间上激进的不同点。我们处理组件故障为正常情况而不是异常,对添加的大文件(可能并行)和读取(通常串行)进行优化,且扩展和释放标准文件系统接口来改进系统
我们的系统通过常态地观察提供容错,复制关键数据且快速自动恢复。块复制允许我们对块服务器容错。这些故障频率激活一个小说在线修复机制常规且透明地修复损伤和快速对丢失的复制节点进行妥协折中。另外,我们使用 checksum 在磁盘和 IDE 子系统水平上来检测数据冲突,这变成在系统中给定一定数量磁盘后的常态
我们的设计转发高聚合到多并行读者和写者执行不同的任务。我们通过分离文件系统控制来实现,其通过主服务器,直接在块服务器和客户端之间直接数据传输。主服务器包含已最小化的大块大小和块租赁的常规操作,在数据修改时代理权限给主复制节点。这使得一个简单中心化的主服务器不会变成瓶颈。我们相信在网络栈中的改进将能够承受被一个独立客户端看到写穿透时当前的限制
GFS 成功地满足了我们的存储需求且作为存储平台在 Google 内部研究和发展和生产环境数据处理中使用。它是重要的工具使得我们能够继续革新和处理在整个网络扩展中的问题