Table of Contents
Algorithm
Leetcode 556: Next Greater Element III: https://leetcode.com/problems/next-greater-element-iii/
https://dreamume.medium.com/leetcode-556-next-greater-element-iii-e02aa583a882
Review
现代 C++ 编程实战 吴咏炜
如何在编译期遍历数据?
对于 tuple,标准 C++ 里提供了很多机制,允许你:
- 知道 tuple 的大小(数据成员数量)
- 通过一个编译期的索引值,知道某个数据成员的类型
- 通过一个编译期的索引值,对某个数据成员进行访问
利用这些信息,我们可以额外做很多事情,比如,用一个函数模板来输出所有 tuple 类型对象的内容。这些功能是普通结构体所没有的!
在 C++ 的静态反射到来之前,我们想在结构体里达到类似的功能,只能自己通过一些编程技巧来实现。本讲我们就会介绍一种手工实现静态反射的方法,能够让结构体在用起来跟原来没感觉有区别的情况下,额外提供类似 tuple 的功能,甚至还更多。毕竟,结构体里的字段是有名字的,可以产生更可读的代码。我们还能进一步利用编译期的字符串模板参数技巧,使用字段名称这一数据,让下面的代码能通过编译
DEFINE_STRUCT(
S1,
(int)v1,
(bool)v2,
(string)msg
);
DEFINE_STRUCT(
S2,
(long)v1,
(bool)v2
);
S1 s1{1, false, "test"};
S2 s2;
copy_same_name_fields(s1, s2);
这段代码做的事情正是你看名字可以想象的,把 s1 中跟 s2 同名的字段复制到 s2 里面去!(注意这不是 memcpy——两个结构体里同名字段的类型可以不同,它们也不需要相邻。)
静态反射的定义
静态反射的基本原理和实现手法,在罗能的博客文章中已经有了较详细的描述 [1]。建议你去读一下。我在这里将不再重复其中的一些技术细节,而是强调基本原理,以及我这边实现得不一样的地方
宏基础
文件 metamacro.h 中提供了一些基础的宏工具,这边我简单介绍一下其中主要的几个功能,对其实现细节就不进行展开了:
- GET_ARG_COUNT:获取宏参数的数量,如 GET_ARG_COUNT(a, b, c) 将得到 3
- STRING:把参数变成字符串,如 STRING(foo) 将得到 “foo”
- PASTE:把两个参数拼接起来,如 PASTE(Hello, World) 将得到 HelloWorld
- PAIR:把 (类型)字段名 这样的序列脱去第一层括号,如 PAIR((long)v1) 将得到 long v1
- STRIP:把 (类型)字段名 这样的序列的类型部分去掉,如 STRIP((long)v1) 将得到 v1
- REPEAT_ON:这是主要玩重复展开的地方,如 REPEAT_ON(func, a, b, c) 将得到 func(0, a) func(1, b) func(2, c)
我们对 DEFINE_STRUCT 的定义如下所示:
#define DEFINE_STRUCT(st, ...) \
struct st { \
template <typename, size_t> \
struct _field; \
static constexpr size_t _size = \
GET_ARG_COUNT(__VA_ARGS__); \
REPEAT_ON(FIELD, __VA_ARGS__) \
}
可以看到,宏展开后成了 struct st 的定义(st 是结构体名),里面有三部分:
- 首先,我们声明了一个叫 _field 的嵌套类模板,指定它具有两个参数,一个类型,一个是 size_t
- 然后,我们根据参数数量,算出字段数量,赋给静态 constexpr 变量 _size
- 最后,我们利用 REPEAT_ON 宏,有多少个字段就重复多少次,逐项产生字段的定义
以我们上面的 S2 为例,宏展开后的结果大致如下(已重新格式化;另注意分号是宏外面手工添加的):
struct S2 {
template <typename, size_t>
struct _field;
static constexpr size_t _size = 2;
FIELD(0, (long)v1)
FIELD(1, (bool)v2)
}
下面,我们主要就不再关心宏的问题,而是如何在给定索引值的情况下,合适地产生静态反射所需要的全部信息和方法
不过,先提醒一下,如果你把宏放到一个供别人使用的公共库的话,一般所有的宏名称都应该加上前缀,以免跟其他宏发生冲突——毕竟宏是没有作用域的,会污染全局名空间。比如,Boost.Test 里的测试宏叫 BOOST_CHECK 或类似的名字,而不是简单的 CHECK。我这边出于讲解上的简洁,基本不用名空间和前缀,但不等于你在项目里也应该这样做:像 PASTE、STRING 这样的宏还是非常容易产生冲突的
如果你使用 MSVC 的话,还有一个额外的问题是 MSVC 的传统预处理方式不符合 C++ 标准,无法正确处理这些宏。你需要启用命令行选项 /Zc:preprocessor 才行 [2]
字段的定义
给定了字段索引、字段类型和字段名称,我们通常需要生成下面这些信息,来方便通过索引使用它们:
- 字段名称
- 字段类型
- 字段值的访问
我们下面需要考虑的,就是(假设)给定了索引值 0、字段内容 (long)v1,如何来生成字段的定义
字段名称看起来最好办
template <typename T>
struct _field<T, 0> {
static constexpr auto name =
STRING(STRIP((long)v1));
…
};
对 (long)v1 进行 STRIP 后,我们得到 v1;再对其 STRING 处理,即得到字符串 “v1”
字段类型也不复杂。唯一的麻烦是我没找到宏处理的方法从 (long)v1 得到 long。当然,我们并不一定需要采用 (long)v1 这种写法,写成 (long, v1) 这样就没这种麻烦了。只不过,从可读性的角度,字段定义成 (long)v1 更接近 C/C++ 的现有语法,确实比 (long, v1) 看起来要直观得多,也能更自然地处理类型之中带逗号的情况(如 array)。我觉得罗能的这个选择非常棒
因此,我们这里采取绕弯的方式,定义为:
using type =
decltype(decay_t<T>::STRIP((long)v1));
换句话说:
using type = decltype(S2::v1);
为什么要把 T 作为参数传进来,还要使用 decay_t 呢?因为我们允许 T 是 S2&、const S2&、S2&& 等多种情况(顺便说一句,如果能用 C++20 的话,那 remove_cvref_t 是个更好的选择)。在字段值的访问时我们就需要用上这种灵活性了:
T&& obj_;
_field(T&& obj)
: obj_(forward<T>(obj)) {}
auto value() -> decltype(auto)
{
return (forward<T>(obj_).v1);
}
这里的另外一个小细节是,返回表达式上的括号是必需的。返回值类型为 decltype(auto),意味着我们使用 decltype(返回表达式) 作为返回值类型:使用 decltype(obj_.v1) 我们会得到 long,而使用 decltype((obj_.v1)) 我们才会得到 long&(或 const long& 之类),后者才是我们想要的
上一节结尾时的 FIELD 宏,就可以自动帮我们来生成这些定义。它本身被定义为:
#define FIELD(i, arg) \
PAIR(arg); \
template <typename T> \
struct _field<T, i> { \
_field(T&& obj) \
: obj_(forward<T>(obj)) {} \
static constexpr auto name = \
CTS_STRING(STRIP(arg)); \
using type = \
decltype(decay_t<T>::STRIP(arg)); \
auto value() -> decltype(auto) \
{ \
return (forward<T>(obj_).STRIP(arg)); \
} \
T&& obj_; \
};
编译期使用字段名称
上面的定义在初步使用时已经够用了,但等到你想在编译期对字段名称进行判断时,你就会发现麻烦来了。当然,利用上一讲我们讲述的编译期传参的技巧,我们可以解决问题。但与其如此,不如我们直接往前走一步,利用字符串模板参数,直接把字段名称从值变成类型:
static constexpr auto name = CTS_STRING(STRIP((long)v1));
这里我们只是简单地把 STRING 变成了 CTS_STRING。这个变化看起来很小,但它会导致下面这些用法上的大改变:
- 相等判断可以直接使用 is_same_v
- 输出的话需要使用宏 CTS_GET_VALUE
- 函数传参大大简化,不再需要 CARG、CARG_WRAP 那套东西
这样带来的一个小问题是:如果你使用 MSVC 的话,你必须启用 C++20 才行
静态反射的使用
-
识别对静态反射的支持
很多情况下,我们需要对处理的数据对象是否支持静态反射作分别的处理。使用类型特征很容易就能做到
template <typename T, typename = void> struct is_reflected : false_type {}; template <typename T> struct is_reflected< T, void_t<decltype(T::_size)>> : true_type {}; template <typename T> constexpr static bool is_reflected_v = is_reflected<T>::value; -
结构体的数据遍历:对象打印
对于一个支持静态反射的结构体,我们可以做的一个非常基本的操作,就是可以像 tuple 一样来进行简单的遍历。为了方便这个常见操作以及类似遍历操作的实现,我们定义下面的函数模板:
template <typename T, typename F, size_t... Is> constexpr void for_each_impl(T&& obj, F&& f, index_sequence<Is...>) { using DT = decay_t<T>; (void(forward<F>(f)( DT::template _field<T, Is>::name, typename DT::template _field<T, Is>( forward<T>(obj)) .value())), ...); } template <typename T, typename F> constexpr void for_each(T&& obj, F&& f) { using DT = decay_t<T>; for_each_impl( forward<T>(obj), forward<F>(f), make_index_sequence<DT::_size>{}); }跟之前一样,为了在推导出 T 是 S2& 等情况下访问 S2 的成员,我们需要使用 decay_t。从 for_each 到 for_each_impl 基本只是个转发,但加上了 index_sequence 参数,这也是我们讲编译期编程时一直在使用的技巧了
主要工作当然就在 for_each_impl 里。它本质上就是一个折叠表达式的展开,基本形式是:
(void(forward<F>(f)(…)), ...)也就是说,我们逐项调用函数 f(使用了完美转发),并抛弃返回值(使用 void)
我们再看一下每次调用函数 f 使用的参数:
- 第一项是 DT::template _field::name,表示字段的名称。这里你可能感到陌生的是对成员模板的 template 消歧义符 [3],其他就应该没啥特别的地方了。从阅读的角度,你基本上可以简单地忽略: 后面的 template 关键字
- 第二项是 typename DT::template _field(forward(obj)).value()。这个表达式有点长,其中,typename DT::template _field 指定了 _field 成员模板的类型,然后我们把 obj 完美转发到构造函数里,之后你就可以用 value() 来以合适的引用方式来访问字段了
所以,对于我们提供给 for_each 的函数,对它的要求也是能接受两个参数:第一个是结构体的字段名,第二个是字段的引用。使用这样一个函数,我们就能对一个结构体进行遍历了
只除了一点——我上面那句话不严格。由于字段名使用强类型,更由于每一个字段的类型都可能不同,一个普通函数无法工作。我们一般会使用泛型 lambda 表达式,本质上,它是一个具有 operator() 成员函数模板的函数对象
有了这个基本工具之后,我们已经可以像 print_tuple 一样方便地输出任何支持静态反射的结构体了。代码如下所示:
template <typename T> void dump_obj(const T& obj, ostream& os = cout, const char* field_name = "", int depth = 0) { auto indent = [&os, depth] { for (int i = 0; i < depth; ++i) { os << " "; } }; if constexpr (is_reflected_v<T>) { indent(); os << field_name << (*field_name ? ": {\n" : "{\n"); for_each( obj, [depth, &os](auto field_name, const auto& value) { dump_obj(value, os, CTS_GET_VALUE(field_name), depth + 1); }); indent(); os << "}" << (depth == 0 ? "\n" : ",\n"); } else { indent(); os << field_name << ": " << obj << ",\n"; } }仔细看一下,你会发现这个函数的实现相当简单。我们根据 T 类型是否支持静态反射,决定是遍历其所有字段,还是直接调用 « 运算符来将其输出。如果是遍历的话,我们就会调用 for_each,并在传递给 for_each 的泛型 lambda 里递归调用 dump_obj,把下面一层的值、字段名等信息传递过去
对于我们开头的那个 s2,dump_obj 可以给出下面这样的输出:
{ v1: 1, v2: false, } -
结构体的元数据遍历:对象字段查找
有时候我们并不希望遍历对象的实际数据,而只是遍历对象的数据类型。一种可能的场景就是,通过一个字段的名称,查找字段在结构体里的索引值
类似于刚才的 for_each,我们可以定义一个 for_each_meta。其实现如下:
template <typename T, typename F, size_t... Is> constexpr void for_each_meta_impl(F&& f, index_sequence<Is...>) { using DT = decay_t<T>; (void(forward<F>(f)( Is, DT::template _field<T, Is>::name)), ...); } template <typename T, typename F> constexpr void for_each_meta(F&& f) { for_each_meta_impl<T>( forward<F>(f), make_index_sequence<T::_size>{}); }使用这个 for_each_meta,我们就可以实现出刚才说的根据字段名称查找索引值的函数了
template <typename T, typename Name> constexpr size_t get_field_index(Name /*name*/) { auto result = SIZE_MAX; for_each_meta<T>([&result](size_t index, auto name) { if constexpr (is_same_v<decltype(name), Name>) { result = index; } }); return result; }这个函数要求传递一个“编译期字符串”的字段名称,然后就会找出这个字段名称对应的字段索引值。如果这个字段不存在的话,就会返回 SIZE_MAX
如对于开头的 S1,我们使用 get_field_index(CTS_STRING(msg)) 就能在编译期得到结果 2
-
两个结构体的同时遍历:对象拷贝
遍历一个结构体只能满足部分常见需求。对于像比较、复制这样的操作,我们需要同时遍历两个结构体。这个函数,依据一些业界的惯例,我命名为 zip
下面是 zip 的实现:
template <typename T, typename U, typename F, size_t... Is> constexpr void zip_impl(T&& obj1, U&& obj2, F&& f, index_sequence<Is...>) { using DT = decay_t<T>; using DU = decay_t<U>; static_assert(DT::_size == DU::_size); (void(forward<F>(f)( DT::template _field<T, Is>::name, DU::template _field<U, Is>::name, typename DT::template _field<T, Is>( forward<T>(obj1)) .value(), typename DU::template _field<U, Is>( forward<U>(obj2)) .value())), ...); } template <typename T, typename U, typename F> constexpr void zip(T&& obj1, U&& obj2, F&& f) { using DT = decay_t<T>; using DU = decay_t<U>; static_assert(DT::_size == DU::_size); zip_impl(forward<T>(obj1), forward<U>(obj2), forward<F>(f), make_index_sequence<DT::_size>{}); }它结构上也还是 for_each 的一个翻版,没有大的区别。此处,根据我这边的实际需求,我要求两个被遍历的结构体的字段数量必须完全一致。根据你的实际需要,你当然也可以实现成以较小的结构体为准;但按照我的实际项目经验,这种在动态大小场景下的常见做法,在编译期显得比较鸡肋,实际用处不大
有了 zip 这样的工具,我们现在可以实现一些较复杂的操作了,比如,可以支持异质同构结构体(成员必须一一对应,但类型可以不同)的逐成员复制。实现代码如下:
template <typename T, typename U> constexpr void copy(T&& src, U& dest) { if constexpr (is_reflected_v<decay_t<T>> && is_reflected_v<decay_t<U>>) { zip(forward<T>(src), dest, [](auto /*field_name1*/, auto /*field_name1*/, auto&& value1, auto& value2) { copy( forward<decltype(value1)>(value1), value2); }); } else { dest = forward<T>(src); } }为了处理移动,我们对源对象使用完美转发,允许它是一个右值。为了防止误用和简化代码,目标对象必须是一个左值。当两个对象都支持静态反射时,我们使用 zip 来进行逐字段的遍历,对每一项继续进行 copy 的动作;否则,我们尝试普通的赋值操作(不支持的话,即会导致编译失败)
对于同一类型结构体的复制,C++ 一般可以默认提供赋值运算符。但如果两个结构体类型不同,那默认的赋值运算符就不工作了。这时候,这个 copy 函数模板就能大显身手了。一种可能的使用场景是,我们可以利用它来实现网络字节序和主机字节序的自动转换。假设我们实现了数据类型 uint32s 和 uint16s,并且这些数据类型支持在跟 uint32_t 和 uint16_t 赋值的时候自动进行转换(这相当容易实现),那我们就可以定义出类似下面的数据结构:
DEFINE_STRUCT( msg_host_t, (uint16_t)tag, (uint16_t)length, (uint32_t)value ); DEFINE_STRUCT( msg_net_t, (uint16s)tag, (uint16s)length, (uint32s)value );从 msg_host_t 的一个对象 msg_host,转换到一个 msg_net_t 的对象 msg_net,我们现在可以一行代码搞定:
copy(msg_host, msg_net);不仅如此,这样的结构体可以嵌套。如果我们有下面的结构体定义:
DEFINE_STRUCT( data_host_t, (msg_host_t)msg, (array<byte, 8>)data ); DEFINE_STRUCT( data_net_t, (msg_net_t)msg, (array<byte, 8>)data );这两种类型的对象之间也可以用 copy 来进行复制,编译器会自动产生合适的转换代码
-
应用:拷贝同名字段
利用静态反射,我们可以自动化很多原本需要手工编码的操作。除了上面展示的那些,常用的场景还有序列化、反序列化等。由于序列化和反序列化跟实际应用场景关联比较紧密,代码也比较复杂,我最后就讲一下开头所展示的、按字段名复制结构体的实现
按字段名来复制结构体,我们首先需要回答下面两个问题:
- 我们按源结构体优先遍历,还是按目标结构体优先遍历
- 我们如何解决字段缺失的问题
在当前的解决方案里,我做出了下面的选择:
- 按目标结构体优先遍历(也就是为大结构体往小结构体拷贝而优化;反过来实现也不难、很相似)
- 严格指定目标结构体里有、源结构体里没有的字段数量(默认为零),不正确的话,直接编译失败
在实现 copy_same_name_fields 之前,我们需要一些辅助的工具函数模板。首先是 count_missing_fields,数一下源结构体里缺失的字段数量:
template <typename T, typename U> constexpr size_t count_missing_fields() { size_t result = 0; for_each_meta<U>([&result](size_t /*index*/, auto name) { if constexpr (get_field_index<T>(name) == SIZE_MAX) { ++result; } }); return result; }这里我们用到了前面描述过的 get_field_index,通过两重循环搜索字段名。所有的这些操作全部发生在编译时,所以我们可以不用太担心这个 O(m×n) 级别的性能开销
在实现 copy_same_name_fields 之前,我们还要做一个小小的处理,标记源结构体里缺失了多少个字段。显然,为了编译期检查,我们需要传递一个模板参数,但我们究竟该用什么类型呢?用 int?还是 size_t?
都不是,为了类型上更严格,也为了代码可读性更高,我选择使用强枚举类型:
enum class missing_fields : size_t {};它的底层是 size_t,但使用者必须显式地给出 missing_fields{1} 这样的方式来表达缺失了一个字段。我认为这样写更加合适、更加可读
现在我们可以最终实现 copy_same_name_fields 了:
template <missing_fields MissingFields = missing_fields{0}, typename T, typename U> constexpr void copy_same_name_fields(T&& src, U& dest) { constexpr size_t actual_missing_fields = count_missing_fields<decay_t<T>, U>(); static_assert(size_t(MissingFields) == actual_missing_fields); for_each(dest, [&src](auto field_name, auto& value) { using DT = decay_t<T>; constexpr auto field_index = get_field_index<DT>(field_name); if constexpr (field_index != SIZE_MAX) { copy(typename DT::template _field< T, field_index>( forward<T>(src)) .value(), value); } }); }我在这个函数里做了以下的事情:
- 检查指定的缺失字段数量是否和实际的缺失字段数量一致,不一致则静态断言失败
- 对目标对象进行逐字段遍历
- 对每个字段,根据字段名在源对象中查找是否存在对应的字段,存在的话,则 copy 过去
很简单吧?这里面的关键,跟上一讲的编译期字符串处理一样,是需要处处保持 constexpr 性。我现在应该已经提供了足够多的例子,让你看到该如何写出这种代码
对于开头给出的 copy_same_name_fields(s1, s2),编译器实际生成的 x86-64 的汇编代码是这样子:
movsx rax, DWORD PTR s1[rip] mov QWORD PTR s2[rip], rax movzx eax, BYTE PTR s1[rip+4] mov BYTE PTR s2[rip+8], alJava 之类的语言虽然有着更为强大的反射能力,但它们的反射机制就完全没有生成这样的高效代码的可能性!
一些实现细节
这一讲的代码有点小复杂,里面有很多容易搞错的小细节,因此我把一个完整的实现和测试放到了 GitHub 上的代码库里。同时,为了方便讲解,我上面给出的代码有一定的简化;而代码库中的实际代码更偏近工程化一些,相比文中的示例有如下的不同:
- 静态反射的工具函数模板放在了名空间 sr 中,跟标准库的同名函数模板可以清晰地区分
- 为了防止冲突,for_each 等函数加上了 enable_if 进行限制,要求操作的对象必须满足 is_reflected
- for_each_meta 在调用函数时增加了一个目前没有用到的参数——字段类型
- dump_obj 的实现方式有所变化
- 测试里添加了对 tuple 行为的模拟,允许某种程度上把结构体当成 tuple 来用
根据你的实际使用场景,这些代码可能还有进一步的优化空间。不过,作为一个基本的实现参考,我想它们已经很有用了
Tips
iOS 开发高手课 戴铭
项目大了人员多了,架构怎么设计更合理?
记得以前所在的团队,规模大了以后,客户端团队也被按照不同业务拆分到了不同的地方。当时,所有的代码都集中在一个仓库,团队里面一百多号人,只要有一个人提交错了,那么所有要更新代码的人都得等到修复后提交。这样一天下来,整个团队的沟通和互相等待都浪费了大量时间。同时,开发完成要进行测试时,由于代码相互耦合、归属不清,也影响到了问题排查的效率,并增加了沟通时间
后来,我们痛定思痛,花了很大力气去进行架构整治,将业务完全解耦,将通用功能下沉,每个业务都是一个独立的 Git 仓库,每个业务都能够生成一个 Pod 库,最后再集成到一起。这样经过架构整治以后,也就没再出现过先前的窘境,开发效率也得到了极大的提升。由此可见,合理的架构是多么得重要
其实,这并不是个例。当业务需求量和团队规模达到一定程度后,任何一款 App 都需要考虑架构设计的合理性
而谈到架构治理,就需要将老业务、老代码按照新的架构设计模式进行重构。所以,架构重构考虑得越晚,重构起来就越困难,快速迭代的需求开发和漫长的重构之间的矛盾,如同在飞行的飞机上换引擎。及早考虑架构设计就显得尤为重要
那么,如何设计一个能支持大规模 App 的架构呢?接下来,我就和你说说这个话题
苹果官方推荐的 App 开发模式是 MVC,随之衍生出其他很多类 MVC 的设计模式 MVP、MVVM、MVCS ,它们在不同程度上增强了视图、数据的通信方式,使得逻辑、视图、数据之间的通信更灵活、规整、易于扩展。在 App 浪潮初期,几乎所有 App 采用的都是这种类 MVC 的结构。原因在于,MVC 是很好的面向对象编程范式,非常适合个人开发或者小团队开发
但是,项目大了,人员多了以后,这种架构就扛不住了。因为,这时候功能的量级不一样了。一个大功能,会由多个功能合并而成,每个功能都成了一个独立的业务,团队成员也会按照业务分成不同的团队。此时,简单的逻辑、视图、数据划分再也无法满足 App 大规模工程化的需求
所以,接下来我们就不得不考虑模块粒度如何划分、如何分层,以及多团队如何协作这三个问题了。解决了这三个问题以后,我们就可以对模块内部做进一步优化了。模块久经考验后,就能成为通用功能对外部输出,方便更多的团队
总的来说,架构是需要演进的。如果项目规模大了还不演进,必然就会拖累业务的发展速度
简单架构向大型项目架构演进中,就需要解决三个问题,即:模块粒度应该如何划分?如何分层?多团队如何协作?而在这其中,模块粒度的划分是架构设计中非常关键的一步。同时,这也是一个细活,我们最好可以在不同阶段采用不同的粒度划分模块。现在,我们就带着这三个问题继续往下看吧
大项目、多人、多团队架构思考
接下来,我先和你说下模块粒度应该怎么划分的问题
首先,项目规模变大后,模块划分必须遵循一定的原则。如果模块划分规则不规范、不清晰,就会导致代码耦合严重的问题,并加大架构重构的难度。这些问题主要表现在:
- 业务需求不断,业务开发不能停。重新划分模块的工作量越大,成本越高,重构技改需求排上日程的难度也就越大
- 老业务代码年久失修,没有注释,修改起来需要重新梳理逻辑和关系,耗时长
其次,我们需要搞清楚模块的粒度采用什么标准进行划分,也就是要遵循的原则是什么
对于 iOS 这种面向对象编程的开发模式来说,我们应该遵循以下五个原则,即 SOLID 原则
- 单一功能原则:对象功能要单一,不要在一个对象里添加很多功能
- 开闭原则:扩展是开放的,修改是封闭的
- 里氏替换原则:子类对象是可以替代基类对象的
- 接口隔离原则:接口的用途要单一,不要在一个接口上根据不同入参实现多个功能
- 依赖反转原则:方法应该依赖抽象,不要依赖实例。iOS 开发就是高层业务方法依赖于协议
同时,遵守这五个原则是开发出容易维护和扩展的架构的基础
最后,我们需要选择合适的粒度。切记,大型项目的模块粒度过大或者过小都不合适
其中,组件可以认为是可组装的、独立的业务单元,具有高内聚,低耦合的特性,是一种比较适中的粒度。就像用乐高拼房子一样,每个对象就是一块小积木。一个组件就是由一块一块的小积木组成的有单一功能的组合,比如门、柱子、烟囱
在我看来,iOS 开发中的组件,不是 UI 的控件,也不是 ViewController 这种大 UI 和功能的集合。因为,UI 控件的粒度太小,而页面的粒度又太大。iOS 组件,应该是包含 UI 控件、相关多个小功能的合集,是一种粒度适中的模块
并且,采用组件的话,对于代码逻辑和模块间的通信方式的改动都不大,完成老代码切换也就相对容易些。我们可以先按照物理划分,也就是将多个相同功能的类移动到同一个文件夹下,然后做成 CocoaPods 的包进行管理
但是,仅做到这一步还不够,因为功能模块之间的耦合还是没有被解除。如果没有解除耦合关系的话,不同功能的开发还是没法独立开来,勉强开发完成后的影响范围评估也难以确定
所以接下来,我们就需要重新梳理组件之间的逻辑关系,进行改造
但是,组件解耦并不是说要求每个组件间都没有耦合,组件间也需要有上下层依赖的关系。组件间的上下层关系划分清楚了,就会容易维护和管理。而对于组件间如何分层这个问题,我认为层级最多不要超过三个,你可以这么设置:
- 底层可以是与业务无关的基础组件,比如网络和存储等
- 中间层一般是通用的业务组件,比如账号、埋点、支付、购物车等
- 最上层是迭代业务组件,更新频率最高
这样的三层结构,尤其有利于多个团队分别开发维护。比如,一开始有两个业务团队 A 和 B,他们在开发时既有通用的功能、账号、埋点、个人页等,也有专有的业务功能模块,每个功能都是一个组件
这样,新创建的业务团队 C,就能非常轻松地使用团队 A 和 B 开发出的通用组件。而且,如果两个业务团队有相同功能时,对相应的功能组件进行简单改造后,也能同时适用于两个业务团队
但是,我认为不用把所有的功能都做成组件,只有那些会被多个业务或者团队使用的功能模块才需要做成组件。因为,改造成组件也是需要时间成本的,很少有公司愿意完全停下业务去进行重构,而一旦决定某业务功能模块要改成组件,就要抓住机会,严格按照 SOLID 原则去改造组件,因为返工和再优化的机会可能不会再有
多团队之间如何分工?
在代码层面,我们通过组件化解决了大项目、多人、多团队架构的问题,但是架构问题还涉及到团队人员结构上的架构。当公司或者集团的 App 多了后,相应的团队也就多了,为了能够让产品快速迭代和稳定发展,也需要一个合理的团队结构。在我看来,这个合理的团队结构应该是这样的:
- 首先,需要一个专门的基建团队,负责业务无关的基础功能组件和业务相关通用业务组件的开发
- 然后,每个业务都由一个专门的团队来负责开发。业务可以按照功能耦合度来划分,耦合度高的业务可以划分成单独的业务团队
- 基建团队人员应该是流动的,从业务团队里来,再回到业务团队中去。这么设计是因为业务团队和基建团队的边界不应该非常明显,否则就会出现基建团队埋头苦干,结果可能是做得过多、做得不够,或着功能不好用的问题,造成严重的资源浪费
总结来讲,我想说的是团队分工要灵活,不要把人员隔离固化了,否则各干各的,做的东西相互都不用。核心上,团队分工还是要围绕着具体业务进行功能模块提炼,去解决重复建设的问题,在这个基础上把提炼出的模块做精做扎实。否则,拉一帮子人臆想出来的东西,无人问津,那就是把自己架空了
我心目中好的架构是什么样的?
现在,我们已经可以从代码内外来分析 App 开发的架构设计了,但也只是会分析了而已,脑海中并没有明确好的架构是什么样的,也不知道具体应该怎么设计。接下来,我们就带着这两个问题继续看下面的内容
组件化是解决项目大、人员多的一种很好的手段,这在任何公司或团队都是没有歧义的。组件间关系协调却没有固定的标准,协调的优劣,成为了衡量架构优劣的一个基本标准。所以在实践中,一般分为了协议式和中间者两种架构设计方案
协议式架构设计主要采用的是协议式编程的思路:在编译层面使用协议定义规范,实现可在不同地方,从而达到分布管理和维护组件的目的。这种方式也遵循了依赖反转原则,是一种很好的面向对象编程的实践
但是,这个方案的缺点也很明显,主要体现在以下两个方面:
- 由于协议式编程缺少统一调度层,导致难于集中管理,特别是项目规模变大、团队变多的情况下,架构管控就会显得越来越重要
- 协议式编程接口定义模式过于规范,从而使得架构的灵活性不够高。当需要引入一个新的设计模式来开发时,我们就会发现很难融入到当前架构中,缺乏架构的统一性
虽然协议式架构有这两方面的局限性,但由于其简单易用的特点依然被很多公司采用
另一种常用的架构形式是中间者架构。它采用中间者统一管理的方式,来控制 App 的整个生命周期中组件间的调用关系。同时,iOS 对于组件接口的设计也需要保持一致性,方便中间者统一调用
中间者架构如下图所示:

可以看到,拆分的组件都会依赖于中间者,但是组间之间就不存在相互依赖的关系了。由于其他组件都会依赖于这个中间者,相互间的通信都会通过中间者统一调度,所以组件间的通信也就更容易管理了。在中间者上也能够轻松添加新的设计模式,从而使得架构更容易扩展
在我看来,好的架构一定是健壮的、灵活的。中间者架构的易管控带来的架构更稳固,易扩展带来的灵活性,所以我认为中间者这种架构设计模式是非常值得推荐的。casatwy 以前设计了一个 CTMediator 就是按照中间者架构思路设计的。你可以在GitHub上看到它的内容
CTMediator 使用的是运行时解耦,接下来我就通过开源的 CTMediator 代码,和你分享下如何使用运行时技术来解耦。解耦核心方法如下所示:
- (id)performTarget:(NSString *)targetName
action:(NSString *)actionName
params:(NSDictionary *)params
shouldCacheTarget:(BOOL)shouldCacheTarget {
NSString *swiftModuleName = params[kCTMediatorParamsKeySwiftTargetModuleName];
// generate target
NSString *targetClassString = nil;
if (swiftModuleName.length > 0) {
targetClassString = [NSString stringWithFormat:@"%@.Target_%@", swiftModuleName, targetName];
} else {
targetClassString = [NSString stringWithFormat:@"Target_%@", targetName];
}
NSObject *target = self.cachedTarget[targetClassString];
if (target == nil) {
Class targetClass = NSClassFromString(targetClassString);
target = [[targetClass alloc] init];
}
// generate action
NSString *actionString = [NSString stringWithFormat:@"Action_%@:", actionName];
SEL action = NSSelectorFromString(actionString);
if (target == nil) {
// 这里是处理无响应请求的地方之一,这个demo做得比较简单,如果没有可以响应的target,就直接return了。实际开发过程中是可以事先给一个固定的target专门用于在这个时候顶上,然后处理这种请求的
[self NoTargetActionResponseWithTargetString:targetClassString selectorString:actionString originParams:params];
return nil;
}
if (shouldCacheTarget) {
self.cachedTarget[targetClassString] = target;
}
if ([target respondsToSelector:action]) {
return [self safePerformAction:action target:target params:params];
} else {
// 这里是处理无响应请求的地方,如果无响应,则尝试调用对应target的notFound方法统一处理
SEL action = NSSelectorFromString(@"notFound:");
if ([target respondsToSelector:action]) {
return [self safePerformAction:action target:target params:params];
} else {
// 这里也是处理无响应请求的地方,在notFound都没有的时候,这个demo是直接return了。实际开发过程中,可以用前面提到的固定的target顶上的。
[self NoTargetActionResponseWithTargetString:targetClassString selectorString:actionString originParams:params];
[self.cachedTarget removeObjectForKey:targetClassString];
return nil;
}
}
}
performTarget:action:params:shouldCacheTarget: 方法主要是对 targetName 和 actionName 进行容错处理,也就是对调用方法无响应的处理。这个方法封装了 safePerformAction:target:params 方法,入参 targetName 就是调用接口的对象,actionName 是调用的方法名,params 是参数
从代码中同时还能看出只有满足 Target_ 前缀的对象和 Action 的方法才能被 CTMediator 使用。这时,我们可以看出中间者架构的优势,也就是利于统一管理,可以轻松管控制定的规则
下面这段代码,是使用 CTMediator 如何调用一个弹窗显示方法的代码示范:
[self performTarget:kCTMediatorTargetA
action:kCTMediatorActionShowAlert
params:paramsToSend
shouldCacheTarget:NO];
可以看出,指定了对象名和调用方法名,把参数封装成字典传进去就能够直接调用该方法了
但是,这种运行时直接硬编码的调用方式也有些缺点,主要表现在两个方面:
- 直接硬编码的调用方式,参数是以 string 的方法保存在内存里,虽然和将参数保存在 Text 字段里占用的内存差不多,同时还可以避免.h 文件的耦合,但是其对代码编写效率的降低也比较明显
- 由于是在运行时才确定的调用方法,调用方式由 [obj method] 变成 [obj performSelector:@””]。这样的话,在调用时就缺少类型检查,是个很大的缺憾。因为,如果方法和参数比较多的时候,代码编写效率就会比较低
这篇文章发出后 CTMediator 的作者 casatwy 找到了我,指出文章中提到的 CTMediator 的硬编码和字典传参这两个缺点,实际上已经被完美解决了。下面是 casatwy 的原话,希望可以对你有所帮助
CTMediator 本质就是一个方法,用来接收 target、action、params。由于 target、action 都是字符串,params 是字典,对于调用者来说十分不友好,因为调用者要写字符串,而且调用的时候若是不看文档,他也不知道这个字典里该塞什么东西
所以实际情况中,调用者是不会直接调用 CTMediator 的方法的。那调用者怎么发起调用呢?通过响应者给 CTMediator 做的 category 或者 extension 发起调用
category 或 extension 以函数声明的方式,解决了参数的问题。调用者看这个函数长什么样子,就知道给哪些参数。在 category 或 extension 的方法实现中,把参数字典化,顺便把 target、action 这俩字符串写死在调用里
于是,对于调用者来说,他就不必查文档去看参数怎么给,也不必担心 target、action 字符串是什么了。这个 category 是一个独立的 Pod,由响应者业务的开发给到
所以,当一个工程师开发一个业务的时候,他会开发两个 Pod,一个是 category Pod,一个是自己本身的业务 Pod。这样就完美解决了 CTMediator 它自身的缺点
对于调用者来说,他不会直接依赖 CTMediator 去发起调用,而是直接依赖 category Pod 去发起调用的。这么一来,CTMediator 方案就完美了
然后还有一点可能需要强调:基于 CTMediator 方案的工程,每一个组件无所谓是 OC 还是 Swift,Pod 也无所谓是 category 还是 extension。也就是说,假设一个工程由 100 个组件组成,那可以是 50 个 OC、50 个 Swift。因为 CTMediator 抹去了不同语言的组件之间的隔阂,所以大家老的 OC 工程可以先应用 CTMediator,把组件拆出来。然后新的业务来了,用 Swift 写,等有空的时候再把老的 OC 改成 Swift,或者不改,都是没问题的
不过,解耦的精髓在于业务逻辑能够独立出来,并不是形式上的解除编译上的耦合(编译上解除耦合只能算是解耦的一种手段而已)。所以,在考虑架构设计时,我们更多的还是需要在功能逻辑和组件划分上做到同层级解耦,上下层依赖清晰,这样的结构才能够使得上层组件易插拔,下层组件更稳固。而中间者架构模式更容易维护这种结构,中间者的易管控和易扩展性,也使得整体架构能够长期保持稳健与活力。所以,中间者架构就是我心目中好的架构
案例分享
明确了中间者架构是我认为的好架构,那么如何体现其易管控和易扩展性呢?我通过一个案例来和你一起分析下
这个例子的代码,在 CTMediator 的基础上进行了扩展,完整代码请点击这个 GitHub
这个范例的主要组件类名和方法名,如下图所示:
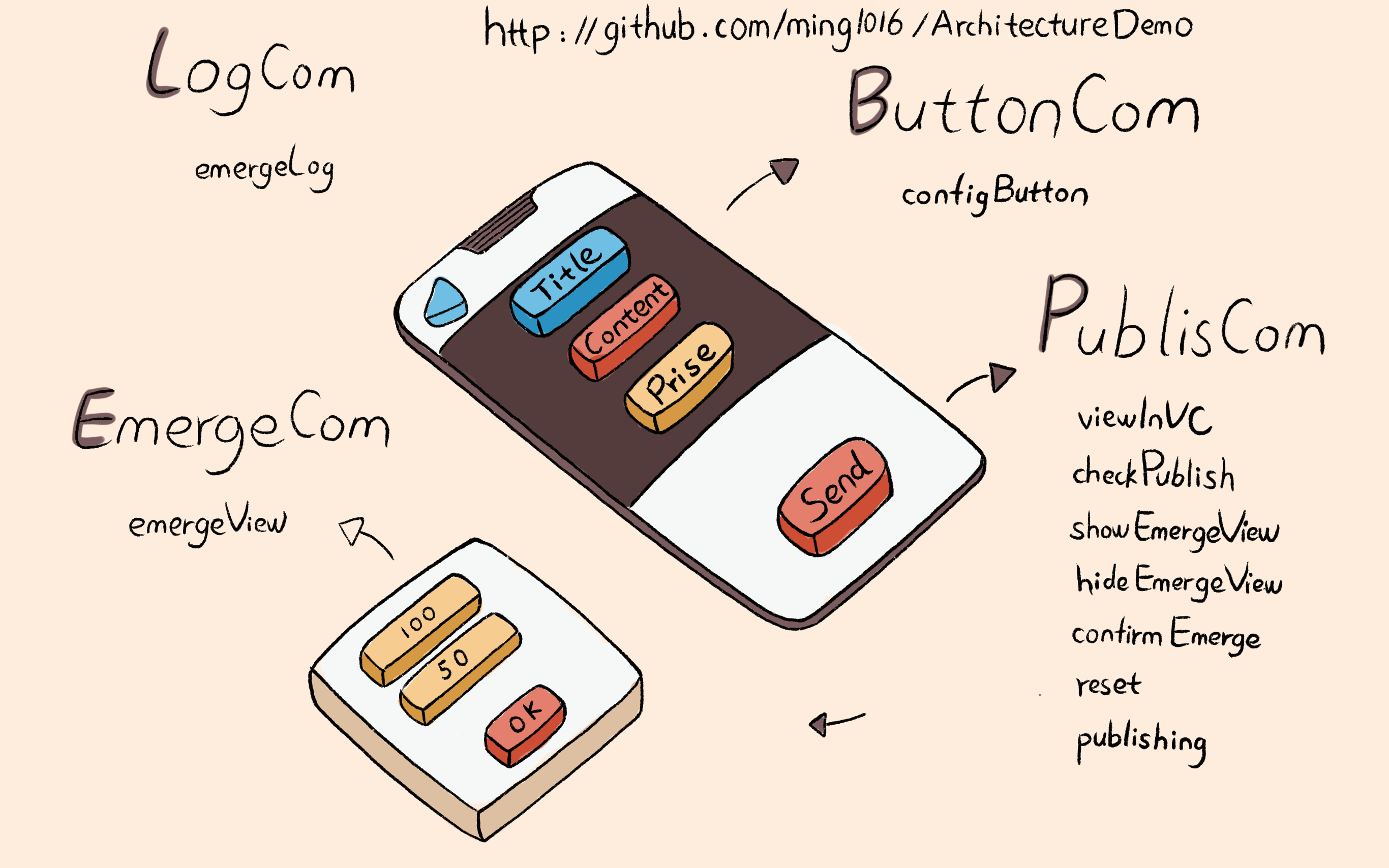
可以看出,这个范例在中间者架构的基础上增加了对中间件、状态机、观察者、工厂模式的支持。同时,这个案例也在使用上做了些优化,支持了链式调用,代码如下:
self.dispatch(CdntAction.cls(@"PublishCom").mtd(@"viewInVC").pa(dic));
代码中的 PublishCom 是组件类名,ViewInVC 是方法名
下面说下中间件模式。在添加中间件的时候,我们只需要链式调用 addMiddlewareAction 就可以在方法执行之前插入中间件。代码如下:
self.middleware(@"PublishCom showEmergeView").addMiddlewareAction(CdntAction.clsmtd(@"AopLogCom emergeLog").pa(Dic.create.key(@"actionState").val(@"show").done));
这行代码对字典参数也使用了链式方便参数的设置,使得字典设置更易于编写。改变状态使用 toSt 方法即可,状态的维护和管理都在内部实现。同一个方法不同状态的实现只需要在命名规则上做文章即可,这也是得易于中间者架构可以统一处理方法调用规则的特性。比如,confirmEmerge 方法在不同状态下的实现代码如下:
// 状态管理
- (void)confirmEmerge_state_focusTitle:(NSDictionary *)dic {
NSString *title = dic[@"title"];
[self.fromAddressBt setTitle:title forState:UIControlStateNormal];
self.fromAddressBt.tag = 1;
}
- (void)confirmEmerge_state_focusContent:(NSDictionary *)dic {
NSString *title = dic[@"title"];
[self.toAddressBt setTitle:title forState:UIControlStateNormal];
self.toAddressBt.tag = 1;
}
- (void)confirmEmerge_state_focusPrice:(NSDictionary *)dic {
NSString *title = dic[@"title"];
[self.peopleBt setTitle:title forState:UIControlStateNormal];
self.peopleBt.tag = 1;
}
可以看出,我们只需要在方法名后面加上“ _state _ 状态名”,就能够对不同状态进行不同实现了
对于观察者模式,使用起来也很简单清晰。比如,发布文章这个事件需要两个观察者,一个执行重置界面,一个检查是否能够发布,代码如下:
// 观察者管理 self.observerWithIdentifier(@"publishOk").addObserver(CdntAction.clsmtd(@"PublishCom reset")).addObserver(CdntAction.clsmtd(@"PublishCom checkPublish"));
这样的写法非常简单清晰。在发布时,我们只需要执行如下代码:
[self notifyObservers:@"publishOk"];
观察者方法添加后,也会记录在内部,它们的生命周期跟随中间者的生命周期
工厂模式的思路和状态机类似,状态机是对方法在不同状态下的实现,而工厂模式是对类在不同设置下的不同实现。由于有了中间者,我就可以在传入类名后对其进行类似状态机中方法名的处理,以便类的不同实现可以通过命名规则来完成。我们先看看中间者处理状态机的代码:
// State action 状态处理
if (![self.p_currentState isEqual:@"init"]) {
SEL stateMethod = NSSelectorFromString([NSString stringWithFormat:@"%@_state_%@:", sep[1], self.p_currentState]);
if ([obj respondsToSelector:stateMethod]) {
return [self executeMethod:stateMethod obj:obj parameters:parameters];
}
}
可以看出当前的状态会记录在 p_currentState 属性中,方法调用时方法名会和当前的状态的命名拼接成一个完整的实现方法名来调用。中间者处理工厂模式的思路也类似,代码如下:
// Factory
// 由于后面的执行都会用到 class 所以需要优先处理 class 的变形体
NSString *factory = [self.factories objectForKey:classStr];
if (factory) {
classStr = [NSString stringWithFormat:@"%@_factory_%@", classStr, factory];
classMethod = [NSString stringWithFormat:@"%@ %@", classStr, sep[1]];
}
可以看出,采用了中间者这种架构设计思想后,架构就具有了很高的扩展性和可管控性。所以,我推崇这种架构设计思路
Share
In All Probability
https://crypto.stanford.edu/~blynn/pr/
当我十多岁的时候,我有幸遇到 Tom Korner。他写了一本书《计数的乐趣》,是关于 John Snow 的一个故事
Snow 是一个 19 世纪英国物理学家,他非常细心地收集和分析大量数据来有说服力地证明霍乱是通过被污染的饮用水来传播的,而不是之前一直广泛确信地通过某种空气污染传播
这给了我一个有力的例子数学,特别是统计如何影响我们的生活。还有多少未征服的真相仍然被隐藏?
到现在,概率和统计似乎总是被认为是恶意的。统计比“该死的谎言“还要恶劣;它容易被“利用”;统计可用来证明任何事情除了真相;它们用来产生“来自可靠人物的不可信事实“
这是怎么发生的呢?我确定这些著名的引言主要是一些俏皮话,且也许来自不可靠的统计而不是事实统计。但这些,甚至数学本身似乎都有疑虑:
统计确实是一个麻烦的主题。它证明 R.A. Fisher 是有错的。Fisher 有一个悲剧的礼物和瑕疵的组合导致今天的错误的悖论统计。(尽管有如山般的证据,Fisher 依旧固执地拒绝相信吸烟导致肺癌。他的方法如何呢?)
我本科概率和统计入门课程跟随了 Fisher 的信条。结果,我感觉他们教我的方法更像黑魔法而不是数学。但我坚信讲师只是教得很简单因为我的理解不深,且我对之缺乏直观
多年后,为决定克服在这个领域我的弱项,我回到我的课本。和一些其他书籍。我发现一个震惊的真相:我的课本是错的。一个疯狂的阴谋理论为真且它们真的用它们的错误数学困扰了我们所有人
免责声明
我从 Fred Ross 听说这个链接发布到了 Hacker News。我想要提醒访问者这些笔记是作为我个人使用的;我很高兴如果其他人读到,但得明白我获得的材料我也很少阅读
Fred Ross 也提供如下总结包括对未来读者的建议:
正确的最常引用(贝叶斯、最小等)基本理论是决策理论,其是博弈理论的子集。Savage 关于统计基础的书有一个非常漂亮的讨论关于为什么是这样。我从 Kiefer 的书中学到了它,这是唯一一本我知道的从这个基本知识开始的书。Lehmann 或 Casella 之后也在他们的书中也提到了
p-值的解释实际上是 Neyman-Pearson 理论的假设测试。p-值是框架中的 alpha 的批评值。我写一些临床医生体验的解释性的文章如果你有兴趣的话
Jaynes 是一个很好的思考者,但得明白当你没有单个工具函数的时候大量合理地行为理论被违背。使用优先类(看 Berger 之后的材料)是对的,或在顺序决策问题(看心理学期望理论,其所有策略有单一的工具函数,但本地策略不能被描述)。这样在 20 世纪中期对自然的贝叶斯推理声明还没有很好把握