Table of Contents
- Algorithm
- Review
- Tips
- Share
Algorithm
Leetcode 546: Remove Boxes: https://leetcode.com/problems/remove-boxes/
https://dreamume.medium.com/leetcode-546-remove-boxes-fe3ac464d475
Review
音视频技术入门课 刘岐
FFmpeg 有哪些常见的应用场景
Remuxing
使用 avformat_open_input、avformat_find_stream_info 来打开输入文件,并根据输入文件中的音视频流信息建立音视频流,也就是 AVStreams
使用 avformat_alloc_output_context2、avformat_new_stream 和 avformat_write_header 来打开输出文件,并建立音视频流,输出文件会用到 AVOutputFormat,并建立封装格式操作的 AVFormatContext,作为操作上下文的结构体,并且会尝试写入输出文件的封装格式头部信息
从输入文件中读取音视频数据包,将音视频数据包写入输出文件会使用 av_read_frame 函数,从输入文件中读取 AVPacket 音视频数据包,还会使用 av_interleave_write_frame 函数,将读取到的音视频数据包写入输出文件
然后是关闭输出文件和输入文件,使用 av_write_trailer 函数,在关闭输出文件之前做写封装收尾工作。使用 avformat_free_context 函数关闭输出文件,并释放因操作输出文件封装格式申请的资源。最后使用 avformat_close_input 关闭输入文件并释放相关资源
当然,除了以上这些操作之外,还有一些 API 是我们可以根据自己的需要使用的。其实在日常操作时,做 remux 主要还是用于收录一些音视频内容的场景中,用得更多的还是编码或者转码的操作。因为音视频的编码数据格式比较多,需要统一转成相同的编码,换句话说,就是将输入的音视频内容转成统一规格输出的场景,比收录场景更常见
Transcoding
打开文件的操作,可以定义为 open_input_file,这样将输入文件操作相关的代码放在一个函数里面比较清晰
static int open_input_file(const char* filename) {
int ret;
unsigned int i;
ifmt_ctx = NULL;
if ((ret = avformat_open_input(&ifmt_ctx, filename, NULL, NULL)) < 0) {
av_log(NULL, AV_LOG_ERROR, "Cannot open input file\n");
return ret;
}
if ((ret = avformat_find_stream_info(ifmt_ctx, NULL)) < 0) {
av_log(NULL, AV_LOG_ERROR, "Cannot find stream information\n");
return ret;
}
stream_ctx = av_calloc(ifmt_ctx->nb_streams, sizeof(*stream_ctx));
if (!stream_ctx) return AVERROR(ENOMEM);
for (i = 0; i < ifmt_ctx->nb_streams; ++i) {
AVStream *stream = ifmt_ctx->streams[i];
const AVCodec *dec = avcodec_find_decoder(stream->codecpar->codec_id);
AVCodecContext *codec_ctx;
if (!dec) {
av_log(NULL, AV_LOG_ERROR, "Failed to find decoder for stream #%u\n", i);
return AVERROR_DECODER_NOT_FOUND;
}
codec_ctx = avcodec_alloc_context3(dec);
if (!codec_ctx) {
av_log(NULL, AV_LOG_ERROR, "Failed to allocate the decoder context for stream #%u\n", i);
return AVERROR(ENOMEM);
}
ret = avcodec_parameters_to_context(codec_ctx, stream->codecpar);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Failed to copy decoder parameters to input decoder context for stream #%u\n", i);
return ret;
}
/* Reencode video & audio and remux subtitles etc. */
if (codec_ctx->codec_type == AVMEDIA_TYPE_VIDEO ||
codec_ctx->codec_type == AVMEDIA_TYPE_AUDIO) {
if (codec_ctx->codec_type == AVMEDIA_TYPE_VIDEO)
codec_ctx->framerate = av_guess_frame_rate(ifmt_ctx, stream, NULL);
ret = avcodec_open2(codec_ctx, dec, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Failed to open decoder for stream #%u\n", i);
return ret;
}
}
stream_ctx[i].dec_ctx = codec_ctx;
stream_ctx[i].dec_frame = av_frame_alloc();
if (!stream_ctx[i].dec_frame) return AVERROR(ENOMEM);
}
av_dump_format(ifmt_ctx, 0, filename, 0);
return 0;
}
avcodec_alloc_context3 申请 AVCodecContext 上下文,用 avcodec_parameters_to_context 将解析到的 AVStream 流信息中的 AVCodecParameter 复制到 AVCodecContext 对应字段中,方便后面解码的时候用
使用 avcodec_open2 打开解码器,然后是打开输出文件
static int open_output_file(const char* filename) {
AVStream *out_stream;
AVStream *in_stream;
AVCodecContext *dec_ctx, *enc_ctx;
const AVCodec *encoder;
int ret;
unsigned int i;
ofmt_ctx = NULL;
avformat_alloc_output_context2(&ofmt_ctx, NULL, NULL, filename);
if (!ofmt_ctx) {
av_log(NULL, AV_LOG_ERROR, "Could not create output context\n");
return AVERROR_UNKNOWN;
}
for (i = 0; i < ifmt_ctx->nb_streams; ++i) {
out_stream = avformat_new_stream(ofmt_ctx, NULL);
if (!out_stream) {
av_log(NULL, AV_LOG_ERROR, "Failed allocating output stream\n");
return AVERROR_UNKNOWN;
}
in_stream = ifmt_ctx->streams[i];
dec_ctx = stream_ctx[i].dec_ctx;
if (dec_ctx->codec_type == AVMEDIA_TYPE_VIDEO ||
dec_ctx->codec_type == AVMEDIA_TYPE_AUDIO) {
/* in this example, we choose transcoding to same codec */
encoder = avcodec_find_encoder(dec_ctx->codec_id);
if (!encoder) {
av_log(NULL, AV_LOG_FATAL, "Necessary encoder not found\n");
return AVERROR_INVALIDDATA;
}
enc_ctx = avcodec_alloc_context3(encoder);
if (!enc_ctx) {
av_log(NULL, AV_LOG_FATAL, "Failed to allocate the encoder context\n");
return AVERROR(ENOMEM);
}
/* In this example, we transcode to same properties (picture size,
sample rate etc.). These properties can be changed for output
streams easily using filters */
if (dec_ctx->codec_type == AVMEDIA_TYPE_VIDEO) {
enc_ctx->height = dec_ctx->height;
enc_ctx->width = dec_ctx->width;
enc_ctx->sample_aspect_ratio = dec_ctx->sample_aspect_ratio;
/* take first format from list of supported formats */
if (encoder->pix_fmts)
enc_ctx->pix_fmts = encoder->pix_fmts[0];
else
enc_ctx->pix_fmts = dec_ctx->pix_fmt;
enc_ctx->time_base = av_inv_q(dec_ctx->framerate);
} else {
enc_ctx->sample_rate = dec_ctx->sample_rate;
ret = av_channel_layout_copy(&enc_ctx->ch_layout, &dec_ctx->ch_layout);
if (ret < 0) return ret;
enc_ctx->sample_fmt = encoder->sample_fmts[0];
enc_ctx->time_base = (AVRational){1, enc_ctx->sample_rate};
}
if (ofmt_ctx->oformat->flags & AVFMT_GLOBALHEADER)
enc_ctx->flags |= AV_CODEC_FLAG_GLOBAL_HEADER;
/* Third parameter can be used to pass settings to encoder */
ret = avcodec_open2(enc_ctx, encoder, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Cannot open video encoder for stream #%u\n", i);
return ret;
}
ret = avcodec_parameters_from_context(out_stream->codecpar, enc_ctx);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Failed to copy encoder parameters to output stream #%u\n", i);
return ret;
}
out_stream->time_base = enc_ctx->time_base;
stream_ctx[i].enc_ctx = enc_ctx;
} else if (dec_ctx->codec_type == AVMEDIA_TYPE_UNKNOWN) {
av_log(NULL, AV_LOG_FATAL, "Elementary stream #%d is of unknown type, cannot proceed\n", i);
return AVERROR_INVALIDDATA;
} else {
/* if this steam must be remuxed */
ret = avcodec_parameters_copy(out_stream->codepar, in_stream->codecpar);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Copying parameters for stream #%u failed\n", i);
return ret;
}
out_stream->time_base = in_stream->time_base;
}
}
av_dump_format(ofmt_ctx, 0, filename, 1);
if (!(ofmt_ctx->oformat->flags & AVFMT_NOFILE)) {
ret = avio_open(&ofmt_ctx->pb, filename, AVIO_FLAG_WRITE);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Cannot open output file '%s'\n", filename);
return ret;
}
}
/* init muxer, write output file header */
ret = avformat_write_header(ofmt_ctx, NULL);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Error occurred when opening output file\n");
return ret;
}
return 0;
}
设置原始数据操作相关的滤镜初始化,例如调色、调音色、放大、缩小等操作,这些操作可以在自己拿到解码后的数据后,用 OpenGL 等强大的库来完成,这里就不展开介绍了
接下来是循环操作:拿到 AVPacket、解码、取原始数据、编码,再拿到 AVPacket、再解码、再取原始数据、再编码,直到遇到退出相关的条件为止
static int encode_write_frame(unsigned int stream_index, int flush) {
StreamContext *stream = &stream_ctx[stream_index];
FilteringContext *filter = &filter_ctx[stream_index];
AVFrame *filt_frame = flush ? NULL : filter->filtered_frame;
AVPacket *enc_pkt = filter->enc_pkt;
int ret;
av_log(NULL, AV_LOG_INFO, "Encoding frame\n");
/* encode filtered frame */
av_packet_unref(enc_pkt);
ret = avcodec_send_frame(stream->enc_ctx, filt_frame);
if (ret < 0) return ret;
while (ret >= 0) {
ret = avcodec_receive_packet(stream->enc_ctx, enc_pkt);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF) return 0;
/* prepare packet for muxing */
enc_pkt->stream_index = stream_index;
av_packet_rescale_ts(enc_pkt,
stream->enc_ctx->time_base,
ofmt_ctx->streams[stream_index]->time_base);
av_log(NULL, AV_LOG_ERROR, "Muxing frame\n");
/* mux encoded frame */
ret = av_interleaved_write_frame(ofmt_ctx, enc_pkt);
}
return ret;
}
while (1) {
if ((ret = av_read_frame(ifmt_ctx, packet)) < 0) break;
stream_index = packet->stream_index;
av_log(NULL, AV_LOG_ERROR, "Demuxer gave frame of stream_index %u\n", stream_index);
if (filter_ctx[stream_index].filter_graph) {
StreamContext *stream = &stream_ctx[stream_index];
av_packet_rescale_ts(packet,
ifmt_ctx->streams[stream_index]->time_base,
stream->dec_ctx->time_base);
ret = avcodec_send_packet(stream->dec_ctx, packet);
if (ret < 0) {
av_log(NULL, AV_LOG_ERROR, "Decoding failed\n");
break;
}
while (ret >= 0) {
ret = avcodec_receive_frame(stream->dec_ctx, stream->dec_frame);
if (ret == AVERROR_EOF || ret == AVERROR(EAGAIN)) break;
else if (ret < 0) goto end;
stream->dec_frame->pts = stream->dec_frame->best_effort_timestamp;
ret = encode_write_frame(stream->dec_frame, stream_index);
if (ret < 0) goto end;
}
}
av_packet_unref(packet);
}
通过 av_read_frame 循环读取 AVPacket,然后调用 avcodec_send_packet 将 AVPacket 发送给解码器解码,通过 avcodec_receive_frame 拿到解码后的 AVFrame 数据,然后通过编码器给 AVFrame 的数据编码,再写到输出文件里。这时候,写编码后的 AVPacket 数据用的是交错的方式。最后千万被忘了收尾工作,不然内存就泄漏了
推流
前面两个例子涵盖了 API 大部分接口了,其实做推流的话也比较简单,可以任选 Remuxing 或 Transcoding 里的任何一个例子
设置输出文件的时候,有一个 avformat_alloc_output_context2 操作,从我们 Remuxing 例子中可以看到,最后一个字段是输出文件名,这里可以改成 RTMP 的 URL 地址
需要注意的是,因为是推 RTMP 的直播流,所以输出格式要设置成 FLV,否则会报错,报错内容是这样的
[NULL @ 0x3dc1900] Unable to find a suitable output format for 'rtmp://127.0.0.1/live/stream'
所以最后 avformat_alloc_output_context2 的第一个参数是输出的 AVFormatContext,第二个参数可以设置成 NULL 交给 FFmpeg 自动查找,第三个参数设置为 “flv” 字符串,第四个参数就是我们输出的 URL 地址
为了控制节奏,我们可以在循环 av_read_frame 操作的时候,在 av_read_frame 的下一句加上 usleep(40000) 来控制节奏,也就是 sleep 40 毫秒。最后,别忘了在头文件声明部分加上 #include
如何在 FFmpeg 中定制一个自己专属的模块
为 FFmpeg 添加自己的 AVFormat 模块
AVFormat 是各种音视频文件格式(包括网络文件格式)的封装模块,要添加一个自己专属的 AVFormat 模块,需要先“发明”一种自己的文件格式,然后用代码实现,这里为了简洁一点,我们使用固定的编解码格式
-
kwai 文件格式
我们把新“发明”的文件格式命名为 kwai,格式定义如下:
- 支持音视频,文件固定包含一个音频轨和一个视频轨
- 音频固定为 AAC,视频固定为 H264
- 音视频交错存储
- 音视频数据块的长度,32 位无符合整数,大端序,后面跟音视频数据
- 长度字段最高位,音频为 0,视频为 1
文件头定义如下:
- 4 字节文件魔数,固定为 kwai
- 4 字节版号,32 位无符号整数,大端序
- 4 字节采样率,32 位无符号整数,大端序
- 1 字节填充字符,无任何意义,固定为 0
- 1 字节音频声道数
- 2 字节视频宽度,32 位整数,大端序
- 2 字节视频高度,32 位整数,大端序
- 2 字节帧率分子,16 位整数,大端序
- 2 字节帧率分母,16 位整数,大端序
- 26 字节其他文本信息,最后一字节为 0,即 NULL 字符,主要是为了方便字符串处理
这样定制内容,主要是为了演示不同长度整数的处理,外加一个额外的填充字符,同时也是为了数据对齐,人眼看起来比较直观,后面我们会在文件头的 16 机制数据表示时感受到这种效果
-
添加文件
首先,我们在 libavformat 目录下创建两个文件:kwaienc.c 和 kwaidec.c
接下来在 libavformat/Makefile 中增加下面这段内容
OBJS-$(CONFIG_kwai_DEMUXER) += kwaidec.o OBJS-$(CONFIG_kwai_MUXER) += kwaienc.o接下来在 libavformat/allformats.c 中增加下面这段内容
extern const AVOutputFormat ff_kwai_muxer; extern const AVInputFormat ff_kwai_demuxer;执行命令 ./configure –list-muxers 和 ./configure –list-demuxers 可以列出所有的格式,如果能从输出结果中找到 kwai,就说明添加成功了
./configure --list-muxers ./configure --list-demuxers然后重新执行 configure
./configure --enable-muxer=kwai --enable-demuxer=kwai -
添加文件封装格式
文件封装(就是 AVOutputFormat)是一个输出格式,它的输入端也是一个 AVFormat(也就是 AVInputFormat)。下面,我们先注册我们的 kwai 封装文件格式,内容在 kwaienc.c 中。一般来说,分为这几步:
- 定义文件格式结构体
- 准备参数
- 定义一个类
- 向 FFmpeg 注册文件格式
- 实现回调函数
-
定义文件格式结构体
我们先定义一个结构体,用来描述和存储文件的各种参数。其中,这个结构体的第一个成员必须是一个 AVClass 类型的指针,不需要特别处理,FFmpeg 内部会用到。其他参数,你可以参考代码内的注释
typedef struct kwaiMuxContext { AVClass *class; /* AVClass 指针 */ uint32_t magic; /* 魔数 */ uint32_t version; /* 版本号,目前固定为 1 */ uint32_t sample_rate; /* 音频采样率,常用的 AAC 格式为 44100 */ uint8_t channels; /* 声道数 */ uint32_t width; /* 视频宽度 */ uint32_t height; /* 视频高度 */ AVRational fps; /* 帧率 */ char *info; /* 文件的其他描述信息,字符串 */ } kwaiMuxContext; -
准备参数
准备一个 AVOption 结构体数组,用来存放 kwai 文件格式的相关参数。比如,我们下面定义了一个字符串格式的 info 参数和一个整数格式的 version 参数,最后用了一个空(NULL)结构体元素结尾。这两个参数都可以在命令行上使用,后面我们会看到具体的用法
FFmpeg 会自动为这些参数申请存储空间。从下面的代码里我们可以看到,这些参数其实指向了我们上面定义的结构体,当在命令行上指定参数的时候,会修改相应的结构体指针
static const AVOption options[] = { {"info", "kwai info", offsetof(kwaiMuxContext, info), AV_OPT_TYPE_STRING, {.str = NULL}, INT_MIN, INT_MAX, AV_OPT_FLAG_ENCODING_PARAM, "kwaiflags"}, {"version", "kwai version", offsetof(kwaiMuxContext, version), AV_OPT_TYPE_INT, {.64 = 1}, 0, 9, AV_OPT_FLAG_ENCODING_PARAM, "kwaiflags" }, {NULL}, }; -
定义一个类
定义一个 AVClass 结构体,指定 kwai 文件格式的名称,关联上面定义的参数等
static const AVClass kwai_muxer_class = { .class_name = "kwai muxer", .item_name = av_default_item_name, .option = options, .version = LIBAVUTIL_VERSION_INT, }; -
向 FFmpeg 注册文件格式
有了上述内容,我们就可以向 FFmpeg 注册我们的 kwai 文件格式了。其中 ff_kwai_muxer 这个名字对应我们上面在 allformats.c 文件中添加的名字,这样 FFmpeg 在编译器中就可以找到我们定义的文件格式了
const AVOutputFormat ff_kwai_muxer = { .name = "kwai", /* 格式名称 */ .long_name = null_if_config_small("kwai / kwai"), /* 长名称 */ .extensions = "kwai", /* 文件扩展名 */ .priv_data_size = sizeof(kwaiMuxContext), /* 私有数据内存大小 */ .audio_codec = AV_CODEC_ID_AAC, /* 音频编码 */ .video_codec = AV_CODEC_ID_H264, /* 视频编码 */ .init = kwai_init, /* 初始化回调函数 */ .write_header = kwai_write_header, /* 写文件头回调 */ .write_packet = kwai_write_packet, /* 写文件内容回调 */ .write_trailer = kwai_write_trailer, /* 写文件尾回调 */ .deinit = kwai_free, /* 写文件结束后,释放内存回调 */ .flags = 0, /* 其他标志(略) */ .priv_class = &kwai_muxer_class, /* 私有的文件结构体,指向我们上一步定义的内容 */ }; -
实现回调函数

-
初始化函数
初始化函数在最初打开文件时调用,这个函数的输入参数是一个 AVFormatContext 结构体指针,由 FFmpeg 在打开文件时传入。这个结构体指针包含了文件的类型、流的数量(nb_streams)和各种参数。根据这些参数,我们就可以完成 kwai 封装器的初始化工作了
static int kwai_init(AVFormatContext *s) { AVStream *st; /* 音视频流,每一个 stream 代表一个类型,如音频流、视频流等 */ kwaiMuxContext* kwai = s->priv_data; /* 指向私有的结构体,已初始化为默认值 */ printf("init nb_streams: %d\n", s->nb_streams); if (s->nb_streams < 2) { /* 音视频流数量,我们只接受一个音频流和一个视频流的输入 */ return AVERROR_INVALIDDATA; /* 简单出错处理 */ } st = find_stream(s, AVMEDIA_TYPE_AUDIO); /* 查找音频流,该函数后面解释 */ if (!st) return AVERROR_INVALIDDATA; /* 简单出错处理,如果找不到音频流则返回 */ kwai->sample_rate = st->codecpar->sample_rate; /* 记住输入音频流的采样率 */ kwai->channels = st->codecpar->channels; /* 记住声道数 */ st = find_stream(s, AVMEDIA_TYPE_VIDEO); /* 查找视频流,该函数后面解释 */ if (!st) return AVERROR_INVALIDDATA; /* 简单出错处理,如果找不到音频流则返回 */ kwai->width = st->codecpar->width; kwai->height = st->codecpar->height; /* kwai->fps = st->codecpar->fps; */ kwai->fps = (AVRational){15, 1}; /* 记住帧率 */ return 0; } static AVStream *find_stream(AVFormatContext* s, enum AVMediaType type) { int i = 0; for (; i < s->nb_streams; ++i) { AVStream* stream = s->streams[i]; if (stream->codecpar->codec_type == type) return stream; } return NULL; } -
写头文件
初始化完成后,下一步就是写文件头,其实写文件头函数也是一个回调函数,都是由 FFmpeg 的核心逻辑回调的,所以我们只需要照着输入输出格式定义好文件就可以了
static int kwai_write_header(AVFormatContext *s) { kwaiMuxContext* kwai = s->priv_data; kwai->magic = MKTAG('K', 'W', 'A', 'I'); /* avio_wb32(s->pb, kwai->magic); */ avio_write(s->pb, (uint8_t *)&kwai->magic, 4); avio_wb32(s->pb, kwai->version); avio_wb32(s->pb, kwai->sample_rate); avio_wb8(s->pb, 0); avio_wb8(s->pb, kwai->channels); avio_wb16(s->pb, kwai->width); avio_wb16(s->pb, kwai->height); avio_wb16(s->pb, kwai->fps.num); /* 帧率分子 */ avio_wb16(s->pb, kwai->fps.den); /* 帧率分母 */ char info[16] = {0}; if (kwai->info) { strncpy(info, kwai->info, sizeof(info) - 1); } avio_write(s->pb, info, sizeof(info)); return 0; }info 字符串占 26 个字节(包括结尾的 NULL 字符),这主要是为了使文件头部分正好是 48 个字节,对人眼比较友好
-
写音视频数据
如果初始化和写文件头正常,FFmpeg 就开始写音视频数据了。其中,输入参数除了 AVFormatContext 结构体指针外,还有一个 AVPacket 结构体指针,里面存放了具体要求的音视频数据。音视频会交错存储,首先写入当前数据的时间戳(64 位的 pts 值),然后是以 32 位无符号整数表示的长度(其中视频的长度最高位置 1),接着写入实际的音视频数据
static int kwai_write_packet(AVFormatContext *s, AVPacket *pkt) { /* kwaiMuxContext* kwai = s->priv_data; */ if (!pkt) return 1; uint32_t size = pkt->size; /* 获取数据大小 */ AVStream *st = s->streams[pkt->stream_index]; if (st->codecpar->codec_type == AVMEDIA_TYPE_AUDIO) { printf("Audio: %04d pts: %lld\n", size, pkt->pts); /* 打印音频字节数和 pts */ } else if (st->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) { printf("Video: %04d pts: %lld\n", size, pkt->pts); /* 打印视频字节数和 pts */ size |= (1 << 31); /* 如果是视频,将长度的最高位置 1 */ } else { return 0; /* ignore any other types */ } avio_wb64(s->pb, pkt->pts); avio_wb32(s->pb, size); avio_write(s->pb, pkt->data, pkt->size); /* 实际的音视频数据 */ return 0; } -
文件结束处理
文件结束时,调用 write_trailer 回调写尾部数据,并调用 deinit 回调释放相应的内存,这里我们的封装器实现得比较简单,所以简单放两个空函数即可
static int kwai_write_trailer(AVFormatContext *s, AVPacket *pkt) { return 0; } static void kwai_free(AVFormatContext *s) { } -
编译运行
最后,直接执行 make 就可以编译了。不过,这时候由于我们没有实现解封装器,会提示 ff_kwai_demuxer 不存在。为了能“骗过”编译器,我们可以先在 kwaidec.c 里定义一下,临时代码如下
#include "avformat.h" const AVInputFormat ff_kwai_demuxer;编译通过后,我们就可以使用熟悉的命令行来生成一个 kwai 类型的文件了。先找一个标准的 MP4 文件(如 input.mp4)作为输入,命令行如下
./ffmpeg -i input.mp4 -bsf:v h264_mp4toannexb -info 'a simple test' out.kwai上述命令中,我们使用了 h264_mp4toannexb 这个 filter,它的主要作用是将 MP4 中的 H264 视频容器数据封装转换为传统的使用 startcode 分割的 annexb 比特流格式。因为大多数解码器只支持这种格式。此外,我们还使用 -info 参数增加了一些文本信息,输出文件名为 out.kwai
下面,我们先分析一下文件格式是否符合我们的预期。Windows 平台可以使用一些 16 进制编辑器打开文件查看,输出内容如下:
00000000: 6b77 6169 0000 0001 0000 ac44 0002 0280 kwai.......D.... 00000010: 01e0 000f 0001 6120 7369 6d70 6c65 2074 ......a simple t 00000020: 6573 7400 0000 0000 0000 0000 0000 0000 est............. 00000030: 0000 0000 0000 0000 0000 0017 de02 004c ...............L
-
如何参与到 FFmpeg 社区交流中
角色介绍
社区中主要有这么几类人
- 贡献者(contributor):主要指给开源项目贡献代码或文档的人,还有参与 code review 并且 review 意见被采纳的人
- 维护者(maintainer):主要指对代码或文档有提交和维护责任的人
- 委员会(committee):主要指负责社区日常运作、流程管理这一类工作的人
交流的工具
FFmpeg 开源社区主要是通过邮件列表和 IRC 聊天室沟通。IRC 聊天室比较即时,但是整体不如用邮件列表通用
邮件列表
通过 FFmpeg 官方网站 邮件列表页 我们可以看到,命令行用户是在 ffmpeg-user 列表里交流,API 用户是在 libav-user 列表里交流,FFmpeg 的开发者是在 ffmpeg-devel 列表里交流
libav-user 列表里问问题、交流,几乎没什么人回复,主要是因为 API 用户自己业务场景或自己使用的方式出现了一些问题,别人也不太愿意看你的代码,所以自己挖的坑还是需要自己仔细研究怎么填
ffmpeg-devel 列表里,主要是以 Patch 为沟通的基础,在这里提需求几乎没人理,反馈 Bug 也没人理,但是你修改了 FFmpeg 内部的代码的话,做成 patch 发到这个列表里,获得回应的概率会高一些
ffmpeg-user 里比较热闹,主要是命令行遇到问题,有些参数执行的效果有问题等。这里收到回复的概率更大,但需要注意一点,不要“top-posting“,这是 FFmpeg 社区邮件列表里沟通最基本的原,即回复邮件的时候不要在邮件内容的最上面回复,推荐的做法是想要回复哪一句就在哪一句的下面新起一行回复
如果对整个邮件都存在不同意见的话,可以在邮件的最下方回复。邮件列表是有每日归档的,归档时有统一的格式要求。所有的记录在 归档列表 里面都能找到。邮件列表使用方法是先使用邮箱注册到邮件列表,然后在自己邮箱里确认注册成功就可以了
IRC
聊天室主要是分为用户聊天室和开发者聊天室,用户主要是命令行用户和 API 用户,开发者是指 FFmpeg 内部代码开发者。用户聊天室人会多一些,活跃度高一些,开发者聊天室用户少,所以活跃度没有那么高,并且大多是关于开发内容的临时性沟通,主要沟通还是在邮件列表里面,所以通常大家不怎么用 IRC 交流,除非特别着急的时候。如果你有兴趣的话,可以看一下 IRC 相关的参考链接
成为 contributor 还需要给 FFmpeg 反馈 Bug、贡献代码。接下来我们一起看一下 FFmpeg 反馈 Bug 和贡献代码的渠道
Bug 反馈渠道

FFmpeg 是通过 trac 来管理 Bug 的。Bug 也分很多种,有需求类 Bug,也有阻塞型 Bug。提 Bug 的格式也需要注意,主要是需要说清楚自己的环境、FFmpeg 的版本和使用的参数,把 FFmpeg 执行命令的那一行到结束的所有的内容都贴到 Bug 说明里,不需要自己做内容剪切
自己提了 Bug 以后,不一定能够及时得到解决。如果我们自己分析并解决了 Bug,再把代码回馈给 FFmpeg 的话,是个参与 FFmpeg 开发不错的路径,而且还会降低使用风险。因为 FFmpeg 是 LGPL 的 License,如果不反馈修改过的代码的话,可能会涉及开源使用合规相关的法务问题,尽管 FFmpeg 目前不太追究法律问题了,但是还是要考虑一下合规性的
代码贡献渠道
当前,给 FFmpeg 贡献代码采用的是向邮件列表发送 patch 的方式,发送 patch 到邮件列表后,邮件列表里面的开发者和维护者们会通过回邮件的方式做 code review,可能会提一些 comments,他们做 code review 的时候,也是在邮件内容中对自己有意见的那一行或者那一部分做出回复,不会 top-posting
而 patch 是需要通过 git format-patch 来生成的,在发送 patch 之前,你需要自己验证一下代码格式是否符合标准,在源代码目录的 tools 目录下有一个 patcheck ,它可以辅助你检查代码是否符合 FFmpeg 的基本标准,在修改完代码之后,自己本地需要做一下 FFmpeg 自测,操作步骤如下:
- make fate-rsync SAMPLES=fate-suite/
- make fate SAMPLES=fate-suite/
也可以在做 configure 编译配置的时候指定 fate 测试样本
./configure --samples=fate-suite/
make fate-rsync
make fate
在配置(configure)的时候,添加一个 -samples=fate-suite 来指定测试样本下载的目录
在 make fate 通过以后,才能确保修改的代码对原有的 FFmpeg 代码和能力没有太大的影响。如果 make fate 不通过的话,说明代码修改得还是不够好,会影响一些我们没有看到的逻辑
发送 patch 到邮件列表的时候,我推荐你使用 git send-email 的方式来发送,这样可以按照标准格式将 patch 发送到邮件列表,如果打开文本复制粘贴到邮件里面的话,很容易出现乱码
FFmpeg 的邮件列表和其他工具基本上是联动的,如果我们发一个 patch 想确认是否正常的话,FFmpeg 还提供了个 patchwork 工具,在 patchwork 里也可以看到你的 patch 是否正常。因为 FFmpeg 支持的平台比较多,所以平台兼容性也在考虑范围之内
当然,我们在修改完代码以后,做 git commit 的时候提交信息需要尽量全面地描述修改的原因、你的思考以及背后的逻辑,这样别人才能知道你为什么这样修改代码
成为维护者
要成为维护者的话,首先需要达到几个关键的指标:
- 代码覆盖量达到一定的标准,就拿某个模块来说,如果这个模块代码有 5000 行,其中有超过 50% 的代码是你写的,那么你就有机会成为这个模块的维护者
- 在 FFmpeg 做 Bugfix 的 patch、完善功能的 patch 以及性能优化的 patch,达到一定数量以后,你就可以尝试申请成为 FFmpeg 的维护者。数量没有一个明确的量化值,但多多益善
搭建本地验证环境
当有人发 patch 到邮件列表里面的时候,patchwork 会自动将 patch 放到自己的队列里面。如果想要成为维护者,可以考虑自己在本地搭建一个环境,从 patchwork 队列里将自己维护的模块或相关的 patch 自动下载到本地的,合并到自己本地的代码库里自动地 make fate
如果你希望成为维护者,patch 的兼容性就是一个必要条件,所以在本地搭建自动化回测的各个系统环境是必不可少的,一些基本的可自动化验证的环境也是必不可少的。你可以参考以下几个环境
-
通过用 QEMU 模拟 MIPS + Linux 的环境
../configure --target-exec='.../qemu-mips -cpu 74Kf -L/usr/mips-linux-gnu/' --samples=... --enable-gpl --cross-prefix=/usr/mips-linux-gnu/bin/ --cc='ccache mips-linux-gnu-gcc-4.4' --arch=mips --target-os=linux --enable-cross-compile --disable-pthreads --disable-mipsfpu --disable-iconv -
通过 WINE 模拟 windows 环境
../configure --cc='ccache i686-w64-mingw32-gcc' --samples=... --arch=x86 --target-os=mingw32 --cross-prefix=i686-w64-mingw32- --enable-gpl --pkg-config=./pig-config --target_exec=wine -
X86 Linux 环境
-
X86 MacOS 环境
-
M1 MacOS 环境
本地验证代码
新增的 patch 对代码的修改是否会引起内存泄露,这也是不可缺少的一步。你可以尝试使用 AddressSanitizer 或 Valgrind 做代码修改的内存操作异常检测。比如我本地用的是 AddressSanitizer
--extra-ldflags=' -O0 -g3 -fsanitize=address -Wno-error -fPIC -I/usr/local/include' --cflags='-O0 -g3 -fsanitize=address -Wno-error -fPIC '
如果出现异常,比如内存操作不标准的话,执行 FFmpeg 做验证的时候会报错:
==58865==ERROR: AddressSanitizer: attempting free on address which was not malloc()-ed: 0x6130000013b8 in thread T0
#0 0x10cbf7639 in wrap_free+0xa9 (libclang_rt.asan_osx_dynamic.dylib:x86_64h+0x48639)
#1 0x10a4676f4 in av_free mem.c:251
#2 0x109433230 in mov_free movenc.c:6755
#3 0x109470296 in deinit_muxer mux.c:423
#4 0x109471671 in av_write_trailer mux.c:1281
#5 0x108e1eece in of_write_trailer ffmpeg_mux.c:533
#6 0x108e41c77 in transcode ffmpeg.c:4095
#7 0x108e410d2 in main ffmpeg.c:4242
#8 0x11069f51d in start+0x1cd (dyld:x86_64+0x551d)
0x6130000013b8 is located 56 bytes inside of 304-byte region [0x613000001380,0x6130000014b0)
allocated by thread T0 here:
#0 0x10cbf7c03 in wrap_posix_memalign+0xb3 (libclang_rt.asan_osx_dynamic.dylib:x86_64h+0x48c03)
#1 0x10a467536 in av_malloc mem.c:105
#2 0x10a4678a4 in av_mallocz mem.c:266
#3 0x10946f152 in avformat_alloc_output_context2 mux.c:122
#4 0x108e2272a in open_output_file ffmpeg_opt.c:2900
#5 0x108e20b4a in open_files ffmpeg_opt.c:3668
#6 0x108e20998 in ffmpeg_parse_options ffmpeg_opt.c:3724
#7 0x108e40ff7 in main ffmpeg.c:4225
#8 0x11069f51d in start+0x1cd (dyld:x86_64+0x551d)
SUMMARY: AddressSanitizer: bad-free (libclang_rt.asan_osx_dynamic.dylib:x86_64h+0x48639) in wrap_free+0xa9
==58865==ABORTING
本地验证 patch 代码风格
用 patcheck 检查代码风格
[root@onvideo-liuqi05-01 ffmpeg]# ./tools/patcheck 0001-avfilter-vsrc_ddagrab-add-options-for-more-control-o.patch
patCHeck 1e10.0
This tool is intended to help a human check/review patches. It is very far from
being free of false positives and negatives, and its output are just hints of what
may or may not be bad. When you use it and it misses something or detects
something wrong, fix it and send a patch to the ffmpeg-devel mailing list.
License: GPL, Author: Michael Niedermayer
possibly unused variables
possibly never written:allow_fallback
possibly constant :allow_fallback
possibly never written:force_fmt
possibly constant :force_fmt
Missing changelog entry (ignore if minor change)
[root@onvideo-liuqi05-01 ffmpeg]#
Tips
移动端音视频开发实战 展晓凯
播放器项目实践(三):让你的播放器跑起来
AVSync 模块的实现
AVSync 模块除了负责音视频的同步之外,还要维护一个解码线程,主要工作就是线程的创建、暂停、运行、销毁,就是我们架构图中 AVsynchronizer 这个类
这个类的实现分成两部分,第一部分是维护解码线程,第二部分就是音视频同步。主要接口与实现有以下四个
- 提供初始化接口,内部实现为:使用外界传递过来的 URI 去实例化解码器模块,实例化成功之后,创建音频队列与视频队列,并且创建解码线程,将音视频解码后的数据放入队列中
- 提供获取音频数据接口,内部实现为:如果音频队列中有音频就直接去返回,同时要记录下这个音频帧的时间戳,如果音频队列中没有音频就返回静音数据
- 提供获取视频帧接口,内部实现为:返回与当前播放的音频帧时间戳对齐的视频帧
- 提供销毁接口,内部实现为:先停掉解码线程,然后销毁解码器,最后再销毁音视频队列
维护解码线程
AVSync 模块创建的解码线程扮演了生产者的角色,生产出来的数据根据类型分别存放到音频队列和视频队列中。而 AVSync 模块向外暴露的获取音频数据和视频帧的方法,扮演了消费者的角色。消费者会从音视频队列里面获取数据,这是一个标准的生产者 - 消费者模型
由于是在 Native 层来维护线程,所以我们选用 Posix 线程模型来创建一个解码线程。创建成功后就让解码线程运行起来,解码音频帧和视频帧。解码出来的音视频帧封装为我们自定义的结构体 AudioFrame 和 VideoFrame,然后把它们分别放入音视频队列中。解码线程内部代码如下
while (isOnDecoding) {
isDecodingFrames = true;
decodeFrames();
isDecodingFrames = false;
pthread_mutex_lock(&videoDecoderLock);
pthread_cond_wait(&videoDecoderCondition, &videoDecoderLock);
pthread_mutex_unlock(&videoDecoderLock);
}
我们设置一个变量名字叫做 max_bufferDuration,值设置为 0.2s。每一次调用 decodeFrames 这个方法,都会将两个队列填充到 max_bufferDuration 的刻度之上,这个方法执行结束之后,解码线程就在 Wait 出等待 Signal 指令
我们设置一个变量名字叫做 min_bufferDuration,值设置为 0.1s。消费者每一次消费数据之后,我们要判断队列里面的音视频缓冲长度是否在 min_bufferDuration 刻度以下,如果在这个刻度以下,就发送 Signal 指令,让生产者线程继续生产数据
bool isBufferedDurationDecreasedToMin = bufferedDuration <= minBufferedDuration;
if (isBufferedDurationDecreasedToMin && !isDecodingFrames) {
int getLockCode = pthread_mutex_lock(&videoDecoderLock);
pthread_cond_signal(&videoDecoderCondition);
pthread_mutex_unlock(&videoDecoderLock);
}
当生产线程收到 Signal 指令之后,就会进入下一轮的解码。伴随着生产线程和消费者线程的协同工作,整个视频播放器也就运行起来了
还需要注意一点,在销毁这个模块的时候,需要先把 isOnDecoding 这个变量设置为 false,然后再发送一次 Signal 指令,让解码线程有机会结束。否则,解码线程就有可能一直在这里等待,成为一个僵尸线程
音视频同步
音视频同步的策略一般分为三种:音频向视频同步、视频向音频同步,以及音频视频统一向外部时钟同步,在使用 ffplay 播放视频文件的时候,所指定的对齐方式就是上面所说的三种方式
| 方式 | 对齐操作 | 缺点 |
|---|---|---|
| 音频向视频同步 | 画面流畅 | 音频丢帧/插入静音帧,用户易感知到 |
| 视频向音频同步 | 音频可以连续的播 | 视频有可能会跳帧,用户不易感知到 |
| 统一向外部时钟同步 | 最大程度地保证音视频都不跳帧 | 控制不好外部时钟,可能出现音频和视频都跳帧的情况 |
-
音频向视频同步
当我们向 AudioOutput 模块填充音频数据的时候,会和当前渲染的视频帧的时间戳进行比较。这个差值如果在阙值范围之内,就可以直接将这一阵音频帧填充给 AudioOutput 模块,让用户听到这个声音,如果不在阙值范围内,就需要做对齐操作
如果要填充的音频帧的时间戳比当前渲染的视频帧时间戳小,那就需要跳帧操作,具体的跳帧操作可以是加快播放速度,也可以是丢掉一部分音频帧的实现
如果音频帧的时间戳逼当前渲染的视频帧时间戳大,那么就需要等待,具体实现有两种,我们可以将音频的速度放慢,播放给用户听,也可以填充空数据给 AudioOutput 模块,进行播放。一旦视频的时间戳赶上了音频的时间戳,就可以将本帧音频帧的数据填充给 AudioOutput 模块了
这种方式优点是可以视频每一帧都播放给用户看,画面可以说是最流畅的。但音频就会有丢帧或者插入静音帧的情况。所以这种对齐方式也会有一个比较大的缺点,就是音频有可能会加速或跳变,也有可能会有静音数据或慢速播放。如果使用变速手段来实现,并且变速系数不太大的话,用户感知可能不太强,但是如果使用丢帧或者插入空数据来实现,用户的耳朵是可以明显感觉到卡顿的
-
视频向音频同步
由于不论是哪个平台播放音频的引擎,都可以保证播放音频是线性的,即播放音频的时间长度与实际这段音频所代表的时间长度是一致的。由于音频线性渲染这一特性,当客户端代码跟我们要视频帧的时候,就会先计算出当前视频队列头部视频帧元素和当前音频播放帧时间戳的差值
如果在阙值范围之内,就可以渲染这一帧视频帧;如果不在阙值范围内的话就要进行对齐操作。如果当前队列头部视频帧的时间戳小于当前播放音频帧的时间戳的话,就进行跳帧操作;如果大于当前播放音频帧的时间戳,就等待一会儿(重复渲染上一帧或者不进行重复渲染)。这种对齐方式的优点是音频可以连续播放,缺点就是视频有可能会跳帧,也有可能重复播放,不会那么流畅。但是用户的眼睛是不太容易分辨轻微的丢帧和跳帧的现象
-
统一向外部时钟同步
实现就是单独在外部维护一轨时钟,我们要保证这个外部时钟的更新是按照时间慢慢增加的,而我们获取音频数据和视频数据的时候,都要和这个外部时钟对齐。如果没有超过阙值,那么久直接渲染,如果超过阙值我们就进行对齐操作
具体的对齐操作就是使用上述两种方式里的对齐操作,用这些方式分别对齐音频和视频。优点是可以最大程度地保证音视频都不跳帧,缺点是如果控制不好外部时钟,极有可能出现音频和视频都跳帧的情况
由于人的耳朵比眼睛敏感,所以我们实现的播放器中就选用视频向音频对齐的方式
中控模块
中控模块就是架构类图中 VideoPlayerContrller 这个类,这个类就是上面提到的各个模块有序地组织起来,让单独运行的各个模块可以协同配合起来。由于每个模块都有各自的线程在运行,所以这个类需要维护好各个模块的生命周期,否则容易产生多线程的问题
-
初始化阶段
我们希望即使客户端代码没有提供渲染的 View,播放器也应该能够播放出声音,可以单独播放音频。在某些场景下是一个比较有用的功能,比如可以加速秒开,可以做一些画中画功能。要想达到这样的目标,我们需要把播放器的初始值和渲染界面的初始化分开。所以,初始化阶段可以分为两部分,一部分是播放器的初始化,另外一部分是渲染界面的初始化
首先我们来看播放器的初始化,因为在初始化的过程中需要和资源建立连接,并执行 I/O 操作,所以这里必须要开辟一个线程来做初始化操作,即利用 PThread 创建一个 InitThread 来执行。在这个线程中,先实例化 AVSynchronizer 这个对象,然后调用这个对象的 init 方法,来建立和媒体资源的连接通道
如果打开链接失败,那么回调客户端打开资源失败;如果打开连接成功,就拿出音频流信息(Channel、SampleRate、SampleFormat)来初始化 AudioOutput,并把这个对象注册给 AudioOutput,用来提供音频数据。AudioOutput 初始化成功后,就直接调用 AVSync 模块的 start 方法,以及 AudioOutput 的播放方法,并且将初始化成功回调给客户端,至此我们的播放器可以正常地播放音频了
接下来是渲染界面初始化的阶段,如果业务层在某个时机可以显示视频的画面了,那么就让 Surface(Texture) View 显示,按照 Surface(Texture)View 的生命周期,调用端会拿着 Surface 调用到 JNI 层,JNI 层会把 Surface 构建成 ANativeWindow,然后调用中控系统的 initVideoOutput 方法。这个方法内部用传递进来的 ANativeWindow 对象和界面的宽、高以及获取视频帧的回调函数来初始化 VideoOutput 对象
-
运行阶段
由于在初始化阶段,我们已经通过调用 AudioOutput 的 start 方法开启了音频输出模块,所以当 AudioOutput 模块将自己缓冲区里面的音频数据播放完毕之后,就会立马通过回调方法让我们的中控模块填充音频数据,那中控模块填充音频数据的方法是如何实现的呢?
这次我们从结果出发来看这个方法的实现
- 填充静音数据,当以下情况出现的时候,要填充静音数据给 AudioOutput 进行播放
-
播放器状态是暂停状态
-
AVSync 中的音频队列已经空了
-
AVSync 已经被销毁了或者解码完毕了
-
- 填充真实数据,当以上情况都不满足的情况下,就去 AVSync 模块中获取音频数据,等填充了音频数据之后,要做两件事
-
更新当前播放的时间戳,用于做后续的音画同步
-
给 VideoOutput(视频输出模块)发送一个指令,让 VideoOutput 模块更新视频帧
-
VideoOutput 模块接收到这个指令之后,就可以调用回调方法来获取一帧视频帧,由于在初始化的时候,已经把中控系统注册给 VideoOutput 用来获取视频帧了,所以这里会调用中控模块获取视频帧的方法。这个方法会调用 AVSync 模块,来获取一个与音频匹配的视频帧,然后返回给视频播放模块,将最新的一帧视频帧更新到画面中
运行阶段还有暂停和继续播放接口的实现,由于当前实现整个播放器是由音频播放模块来驱动的,所以只需要让音频播放模块暂停和继续就好了
销毁阶段要先停掉音频,首先调用 AudioOutput 对象的 stop 方法;然后要停掉 AVSync 模块,由于这个模块内部组合了输入模块,所以要把输入模块的连接给断开,输入模块中利用 FFmpeg 的超时设置可以快速断开连接,然后需要使用 pthread_join 这个排程的方法,等待解码线程运行结束,再把音频队列、视频队列以及解码器都给销毁掉
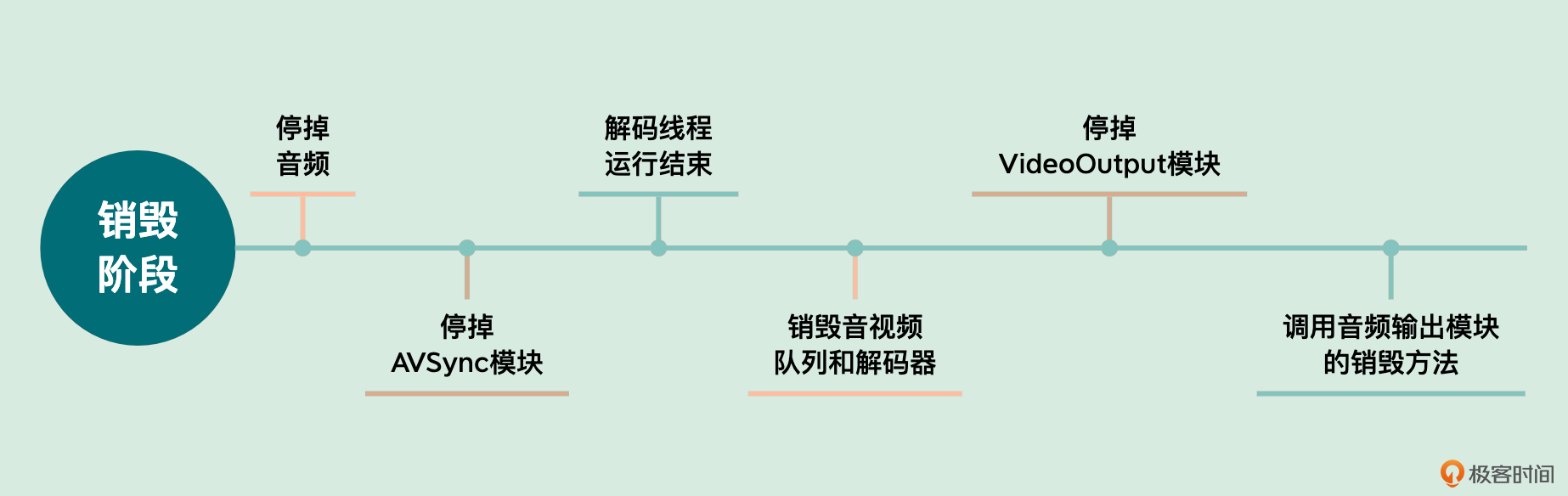
最后一步是停止 VideoOutput 模块,通过调用 VideoOutput 的销毁资源方法(里面会销毁 frameBuffer、renderBuffer、Program 等)来实现,最后再调用音频输出模块的销毁方法
- 填充静音数据,当以下情况出现的时候,要填充静音数据给 AudioOutput 进行播放
iOS 平台音频采集:如何使用 AudioQueue 和 AudioUnit 采集音频
设置 AVAudioSession
设置授权后,要开启一个音频会话,即设置对应的 AVAudioSession,代码如下
[[AVAudioSession sharedInstance] setPreferredIOBufferDuration:AUDIO_RECORD_BUFFER_DURATION
error:&error];
[[AVAudioSession sharedInstance] setPreferredSampleRate:48000 error:nil];
[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryPlayAndRecord error:nil];
[[AVAudioSession sharedInstance] setActive:YES error:nil];
第一行是设置缓冲区的大小,一般设置得越大延迟越高,但是性能越好。如果需要实时耳返的话,一般设置 5~8ms;不需要实时耳返的场景,设置 23ms 左右即可。目前的主流设备可以都设置成 48K 的采样率,兼容性是最好的;如果是不戴耳机或戴有线耳机的情况,根据上面的设置就可以,如果是蓝牙耳机想保留高音质采集,就需要这样设置
[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryPlayAndRecord
withOptions:AVAudioSessionCategoryOptionAllowBluetoothA2DP
error:nil];
这里的麦克风使用的是机身麦克风,如果想使用蓝牙本身的麦克风,设置代码如下
[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryPlayAndRecord
withOptions:AVAudioSessionCategoryOptionAllowBluetooth
error:nil];
如何使用 AudioQueue 采集音频
第一步是创建采集音频类型的 AudioQueue
AudioQueueNewInput(&dataformat, recoderCB, (__bridge void *)self, NULL, NULL, 0, &queueRef);
dataformat 代表期望 AudioQueue 采集音频之后返回给业务层的具体的音频格式,recoderCB 实现如下
static void recoderCB(void *aqData,
AudioQueueRef inAQ,
AudioQueueBufferRef inBuffer,
const AudioTimeStamp *timestamp,
UInt32 inNumPackets,
const AudioStreamPacketDescription *inPacketDesc) {
//1 inBuffer->mAudioData 处理 & IO
//2 重新入队
AudioQueueEnqueueBuffer(inAQ, inBuffer, 0, NULL);
}
当创建好一个 AudioQueue 之后,一般要为这个 AudioQueue 分配 3 个 buffer,然后依次入队
for (int i = 0; i < kNumberBuffers; i++) {
AudioQueueAllocateBuffer(queueRef, self.bufferBytesSize, &buffers[i]);
AudioQueueEnqueueBuffer(queueRef, buffers[i], 0, NULL);
}
bufferByteSize 代表每个 buffer 的数据大小,这个可以根据 dataFormat 与期望的数据长度(比如 50ms)来计算
最后调用 Start 方法启动 AudioQueue
AudioQueueStart(mQueue, NULL)
如何使用 AudioUnit 采集音频
激活 AVAudioSession 之后,就要构造一个 AUGraph,这里启用 RemoteIO 这个 AudioUnit 的 InputElement,代码如下
static UInt32 kInputBus = 1;
UInt32 flag = 1;
AudioUnitSetProperty(ioUnit,
kAudioOutputUnitProperty_EnableIO,
kAudioUnitScope_Input,
kInputBus,
&flag,
sizeof(flag));
RemoteIO 这个 AudioUnit 比较特殊,InputElement(kInputBus 值为 1)代表的是麦克风,而 OutputElement 代表的是扬声器
为了支持后续扩展 Mix 伴奏功能,我们需要额外在 AUGraph 中增加 MultiChannerMixer 这个 AudioUnit。由于每个 AudioUnit 的输入输出格式并不相同,所以这里还要使用 AudioConverter 这个 AudioUnit 来把输入的 AudioUnit 连接到 MixerUnit 上。最终让 MixerUnit 连接上 RemoteIO 的 OutputElement,将声音送到耳机或者扬声器上
这里需要注意,如果没有插耳机的情况下需要 Mute(消音)掉这一路,否则就会出现啸叫的现象。到这里我们就把 AUGraph 构建出来了,如下图所示
 如何把采集的音频存储成一个文件?
如何把采集的音频存储成一个文件?
我们可以在 RemoteIO 这个节点的 OutputElement 增加一个回调,然后在回调方法中来拉取预期节点的数据,同时也可以去写文件,首先给 RemoteIO 这个 AudioUnit 的 OutputElement 增加一个回调
AURenderCallbackStruct finalRenderProc;
finalRenderProc.inputProc = &renderCallback;
finalRenderProc.inputProcRefCon = (__bridge void *)self;
status = AUGraphSetNodeInputCallback(_auGraph, _ioNode, 0, &finalRenderProc);
然后在上述的回调方法的实现中,把它的前一级 MixerUnit 的数据渲染出来,同时写文件
static OSStatus renderCallback(void *inRefCon,
AudioUnitRenderActionFlags *ioActionFlags, const AudioTimeStamp
*inTimeStamp, UInt32 inBusNumber, UInt32 inNumberFrames, AudioBufferList
*ioData){
OSStatus result = noErr;
__unsafe_unretained AudioRecorder *THIS = (__bridge AudioRecorder *)inRefCon;
AudioUnitRender(THIS->_mixerUnit, ioActionFlags,
inTimeStamp, 0, inNumberFrames, ioData);
//Write To File
return result;
}
关于写文件,可使用 AudioToolbox 来给文件编码,但这里我们使用一个更高级的 API - ExtAudioFile 来写文件,其实这个 ExtAudioFile 内部封装了 AudioToolbox 里面的 AudioConverterReference。iOS 提供的这个 API 只需要我们设置好输入格式和输出格式以及输出文件路径和文件格式
AudioStreamBasicDescription destinationFormat;
CFURLRef destinationURL;
result = ExtAudioFileCreateWithURL(destinationURL, kAudioFileCAFType,
&destinationFormat, NULL, kAudioFileFlags_EraseFile, &audioFile);
result = ExtAudioFileSetProperty(audioFile,
kExtAudioFileProperty_ClientDataFormat, sizeof(clientFormat),
&clientFormat);
UInt32 codec = kAppleHardwareAudioCodecManufacturer;
result = ExtAudioFileSetProperty(audioFile,
kExtAudioFileProperty_CodecManufacturer, sizeof(codec), &codec);
在需要给文件编码时,就直接写入数据
ExtAudioFileWriteAsync(audioFile, inNumberFrames, ioData);
在停止写入的时候调用关闭方法即可
ExtAudioFileDispose(audioFile);
如何编码出一个 AAC 文件
常见的音频编码格式
-
WAV 格式
WAV 编码的一种实现(有多种实现,但是都不会进行压缩操作)就是在 PCM 数据格式的前面加上 44 字节,分别用来描述 PCM 的采样率、声道数、数据格式等信息
WAV 编码的特点是音质非常好,几乎可以被所有软件播放,适用于多媒体开发的中间文件、保存音乐和音乐素材
-
MP3 编码
MP3 具有不错的压缩比,使用 LAME 编码(最常使用的一种 MP3 编码器)的中高码率(320 Kbps 左右)的 MP3,听感上非常接近 WAV 源文件,当然在不同的应用场景下,我们自己应该调整合适的参数来达到最好的效果
MP3 编码的特点是音质在 128 Kbps 以上表现还不错,压缩比比较高,大量软件和硬件都支持,兼容性最好,适用于高比特率下对兼容性有要求的音乐欣赏
-
AAC 编码
AAC 是新一代的音频有损压缩技术,它通过一些附加的编码技术,如 SBR、PS 等,衍生出了 LC-AAC、HE-AAC、HE-AACv2 三种主要的编码规格(Profile)。LC-AAC 就是比较传统的 AAC,主要用在中高码率的场景编码(>= 80 Kbps);HE-AAC,相当于 AAC+SBR,主要用在中低码率场景编码(<= 80 Kbps);而 HE-AACv2,相当于 AAC+SBR+PS,主要用于双声道、低码率场景下的编码(<= 84 Kbps)
事实上,大部分 AAC 编码器的实现中,将码率设成小于等于 48 Kbps 会自动启用 PS 技术,而大于 48 Kbps 就不加 PS,就相当于普通的 HE-AAC
AAC 编码的特点是在小于 128 Kbps 的码率下,表现优异,当下应用广泛,多用于 128 Kbps 以下的音频编码、视频中音频轨的编码以及音乐场景下的编码
-
Opus 编码
Opus 集成了以语音编码为导向的 SILK 和低延迟编码为导向的 CELT,所以它同时具有这两者的优点,可以无缝调节高低码率。在较低码率时,使用线性预测编码,在高码率时使用变换编码
Opus 具有非常低的算法延迟,最低可以做到 5 ms 的延迟,默认为 22.5 ms,非常适合用在低延迟语音通话场景。与 MP3、AAC 等常见格式相比,在低码率(64 Kbps 及以下)场景下,Opus 具有更好的音质表现,同时也有更低的延迟表现。WebRTC 中采用的音频默认编码就是 Opus 编码,并且在 Opus 编码的协议中,开发者也可以加入自己的增强信息(类似于 H264 中的 SEI)用于一些场景功能的扩展
Opus 编码的特点是支持众多的帧长范围、码率范围、频率范围,内部有机制,来处理防止丢包策略,在低码率下依然能保持优质的音质。它主要适用于 VOIP 场景下的语音编码
AAC 编码的方式有两种,一种是软编码,另一种是 Android 和 iOS 平台的硬件编码。
AAC 编码格式详解
-
AAC 的编码规
AAC 编码器常用的编码规格有三种,分别是 LC-AAC、HE-AAC、HE-AACv2,这三种编码规格以及使用的消除冗余的技术手段如下图所示
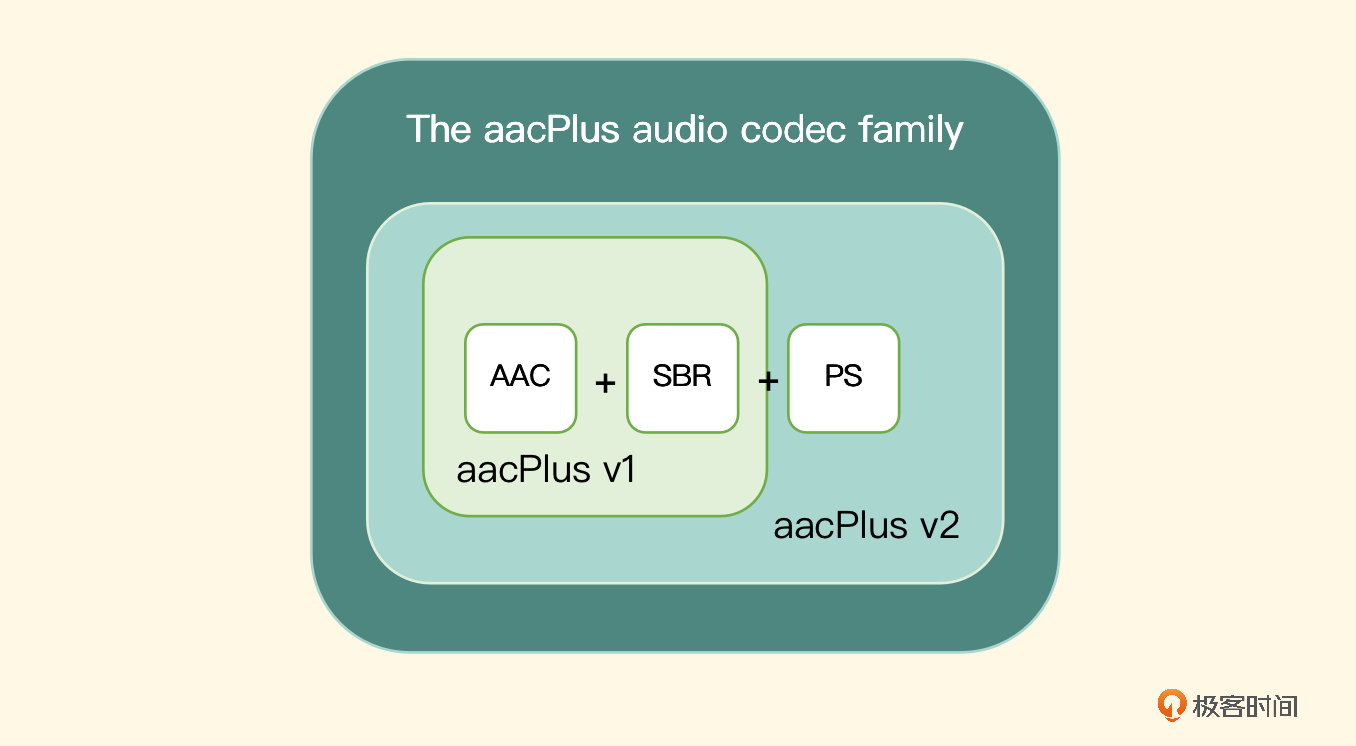 LC-AAC 的 Profile 是最基础的 AAC 的编码规格,它的复杂度最低,兼容性也是最好的,双声道音频在 128 Kbps 的码率下可以达到全频带(44.1 KHz)的覆盖
LC-AAC 的 Profile 是最基础的 AAC 的编码规格,它的复杂度最低,兼容性也是最好的,双声道音频在 128 Kbps 的码率下可以达到全频带(44.1 KHz)的覆盖在 LC-AAC 的基础上添加 SBR 技术,形成 HE-AAC 的编码规格,SBR 全称是 Spectral Band Replication,其实就是消除频域上的冗余信息,可以在降低码率的情况下保持音质。内部实现原理就是把频谱切割开,低频单独编码保存,来保留主要的频谱部分,高频单独放大编码以保留音质,这样就保证在降低码率的情况下,更大程度地保留了音质
在 HE-AAC 的基础上添加 PS 技术,就形成了 HE-AACv2 的编码规格,PS 全称是 Parametric Stereo,其实就是消除立体声中左右声道之间的冗余信息,所以使用这个编码规格编码的源文件必须是双声道的。内部实现原理就是存储了一个声道的全量信息,然后再花很少的字节用参数描述另一个声道和全量信息声道有差别的地方,这样就达到了在 HE-AAC 基础上进一步提高压缩比的效果
我们使用 FFmpeg 命令行,用不同的编码规格,来把同一个输入文件编码称为三个文件,然后使用可视化的音频分析软件 Praat 看一下它们的质量,我们先来看一下原始文件 source.wav(双声道、采样率为 44.1 kHz)导入到 Praat 中的频谱分布
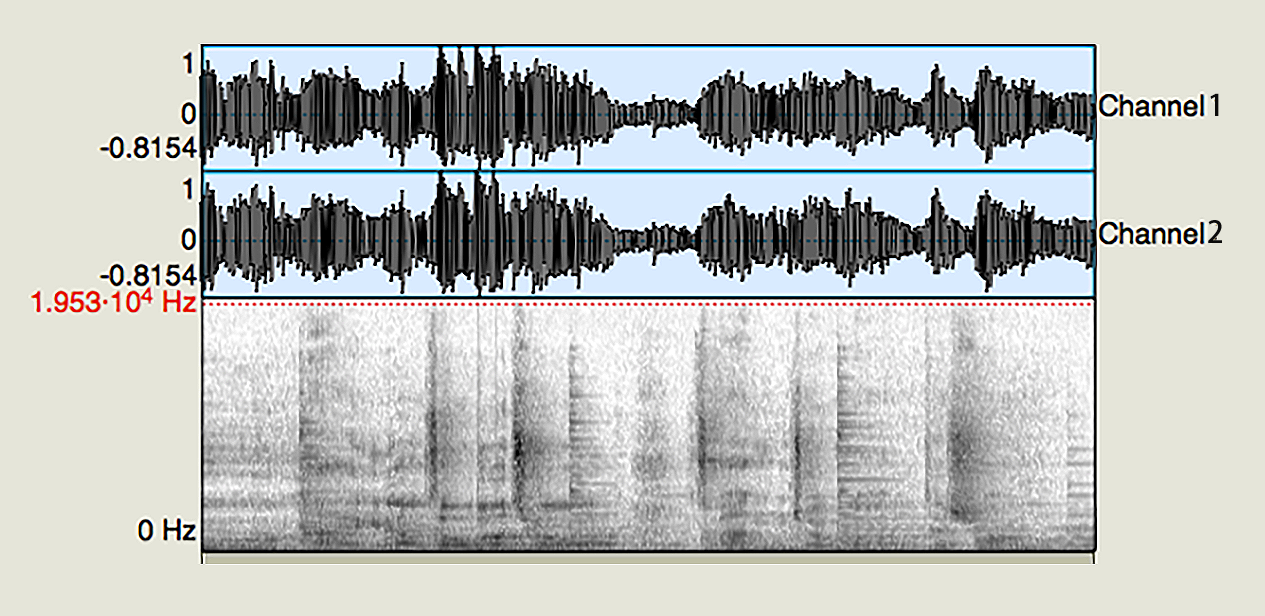 可以看到图片中高频的部分到了 22050,根据奈奎斯特采样定律,编码之后频带分布到 22050 就是全频带分布(原始格式 44.1 KHz),使用下面命令来编码文件
可以看到图片中高频的部分到了 22050,根据奈奎斯特采样定律,编码之后频带分布到 22050 就是全频带分布(原始格式 44.1 KHz),使用下面命令来编码文件ffmpeg -i source.wav -acodec libfdk_aac -b:a 48K lc_aac.m4a ffmpeg -i source.wav -acodec libfdk_aac -profile:a aac_he -b:a 48K he_aac.m4a ffmpeg -i source.wav -acodec libfdk_aac -profile:a aac_he_v2 -b:a 48K he_v2_aac.m4a这三行命令使用的都是 libfdk_aac 编码器,但是使用了不同编码器规格,编码出了三个 M4A 文件。接下来我们把三个文件放到 Praat 中,如下图
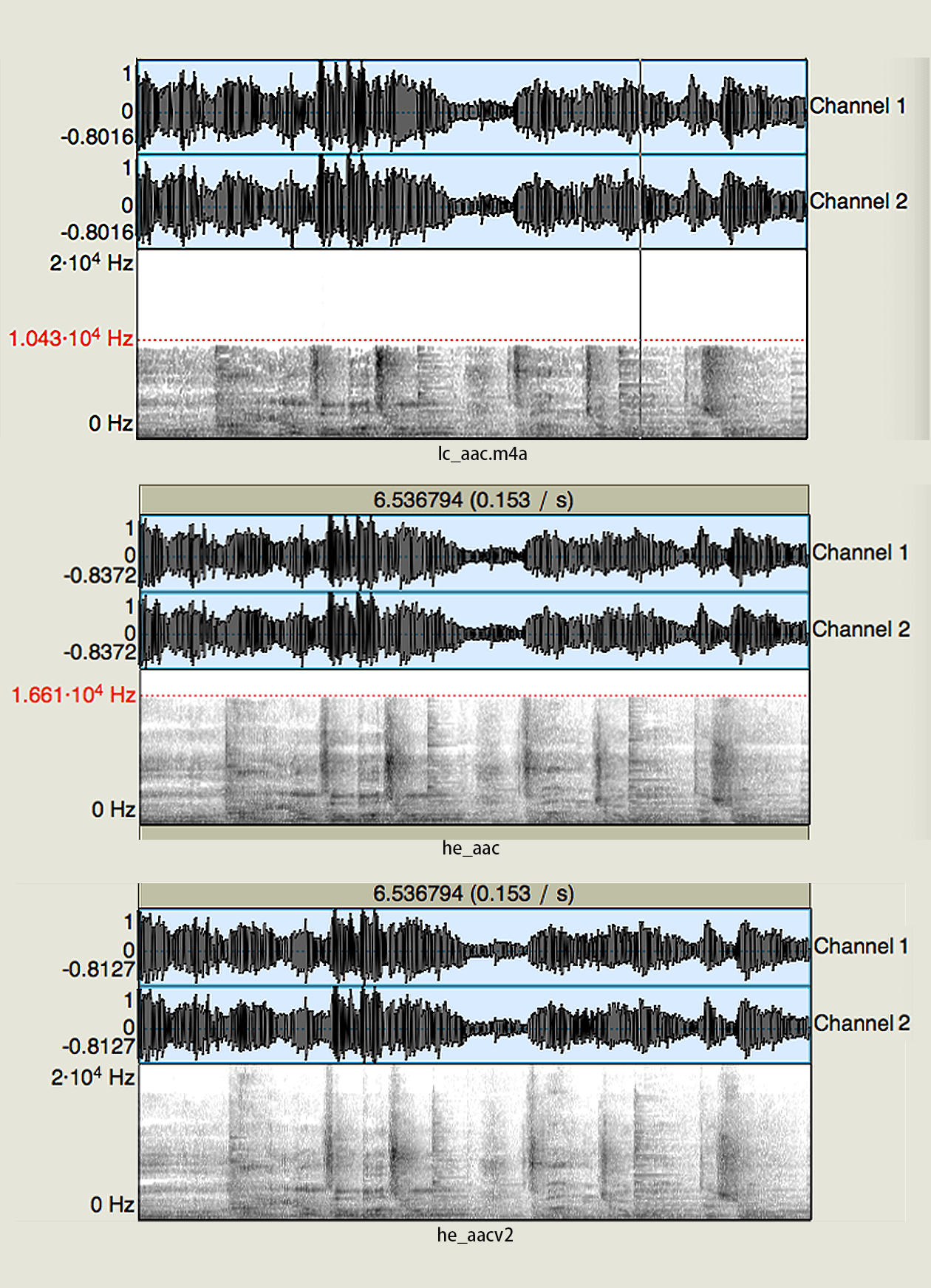 可以看到 lc_aac.m4a 的频带分布到了 10 KHz 就被截断了,对高频部分影响比较大;而 he_aac 这个文件的截止频率大约到了 16 KHz 以上,明显要比第一个好很多;再看第三个文件几乎达到了全频带覆盖,结合之前介绍的原理你就知道为什么这种编码规格可以达到全频带覆盖了
可以看到 lc_aac.m4a 的频带分布到了 10 KHz 就被截断了,对高频部分影响比较大;而 he_aac 这个文件的截止频率大约到了 16 KHz 以上,明显要比第一个好很多;再看第三个文件几乎达到了全频带覆盖,结合之前介绍的原理你就知道为什么这种编码规格可以达到全频带覆盖了 -
AAC 的封装格式
常见的 AAC 编码的封装格式有两种,一种是 ADTS 封装格式,可以简单理解为 AAC 为后缀的文件,另外一种是 ADIF 封装格式,可以简单地理解为以 M4A 为后缀名的文件
ADIF 全称是 Audio Data Interchange Format,是 AAC 定义在 MPEG 4 里面的格式,字面意思是交换格式,是将整个流的 Meta 信息(包含 AAC 流的声道、采样率、规格、时长)写到头部,解码器只有解析了头部信息之后才可以解码具体的音频帧,像 M4A 封装格式、FLV 封装格式、MP4 封装格式都是这样的
ADTS 全称是 Audio Data Transport Stream,是 AAC 定义在 MPEG 2 里面的格式,含义就是传输流格式,特点是从流中的任意帧位置都可以直接进行解码。这种格式实现的原理是在每一帧 AAC 原始数据块的前面都会加上一个头信息(ADTS+ES),形成一个音频帧,然后不断地写入文件中形成一个完整可播放的 AAC 文件
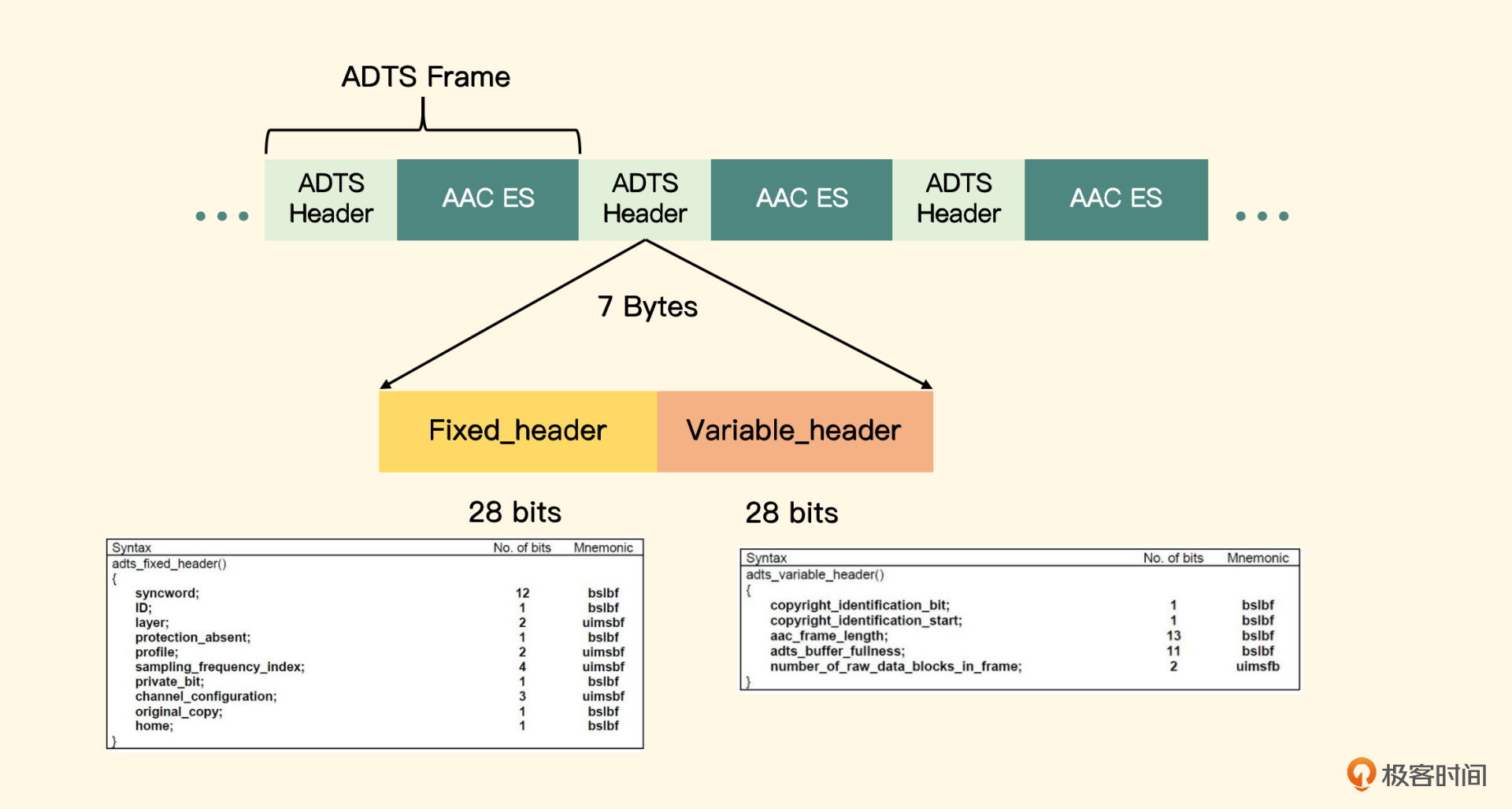 如图所示,ADTS 头分为固定头和可变头两部分,各自需要 28 位来表示,要构造一个 ADTS 头其实就是分配这 7 个字节,下面我们来分配一下这七个字节
如图所示,ADTS 头分为固定头和可变头两部分,各自需要 28 位来表示,要构造一个 ADTS 头其实就是分配这 7 个字节,下面我们来分配一下这七个字节int adtsLength = 7; char *packet = malloc(sizeof(char) * adtsLength); packet[0] = (char)0xFF; packet[1] = (char)0xF9;前 12 位表示同步字,固定为全 1,接下来的 4 位表示的是 ID,我们这里是 ADTS 的封装格式 ID,也就是 1;Layer 一般固定为 00,protection_absent 代表是否进行误码校验,这里我们填 1
后面的字节是编码规格、采样率下标(注意是下标、而不是采样率)、声道配置(注意是声道配置,而不是声道数)、数据长度的组合(注意 packetLen 是原始数据长度加上 ADTS 头的长度),最后一个字节一般也是固定的代码,如下
int profile = 2; // AAC LC int freqIdx = 4; // 44.1KHz int chanCfg = 2; // CPE packet[2] = (byte) (((profile - 1) << 6) + (freqIdx << 2) + (chanCfg >> 2)); packet[3] = (byte) (((chanCfg & 3) << 6) + (packetLen >> 11)); packet[4] = (byte) ((packetLen & 0x7FF) >> 3); packet[5] = (byte) (((packetLen & 7) << 5) + 0x1F); packet[6] = (char) 0xFC;这里具体的编码 Profile、采样率的下标以及声道数配置,可以点击 链接 查看相关的所有表示。一般编码器(Android 的 MediaCodec 或者 iOS 的 AudioToolbox)编码出来的 AAC 原始数据块我们成为 ES 流,需要在前面加上 ADTS 的头,才可以形成可播放的 AAC 文件。对于这种 ADTS 的压缩音频帧,也可以直接使用 FFmpeg 封装成 M4A 格式的文件
在 FFmpeg 中,有一个类型的 Filter 叫做 bit stream filter,主要是应用在一些编码格式的转封装行为中。对于 AAC 编码上述的两种封装格式,FFmpeg 提供了 aac_adtstoasc 类型的 bit stream filter,用来把 ADTS 格式的压缩包(AVPacket)转换成 ADIF 格式的压缩包(Packet)。使用这个 Filter 可以很方便地完成 AAC 到 M4A 封装格式的转换,不用重新进行解码编码的操作,FFmpeg 帮助开发者隐藏了实现细节,并且提供了更好的代码可读性
使用软件编码器编码 AAC
我们用 FFmpeg API 的原因,是我们以后想使用别的编码格式,只需要调整相应的编码器 ID 或者或者编码器 Name 就可以了
为同时运行在 Android 和 iOS 中,我们构建一个 C++ 类,叫 audio_encoder,向外暴露三个接口,分别是初始化、编码以及销毁方法(实现会根据 FFmpeg 版本不同稍有不同,FFmpeg 5.0 以上改动较大)
-
初始化
接口定义如下:
int init(int bitRate, int channels, int sampleRate, int bitsPerSample, const char* aacFilePath, const char * codec_name);对于双声道的音频,一般我们设置 128 Kb 就可以了
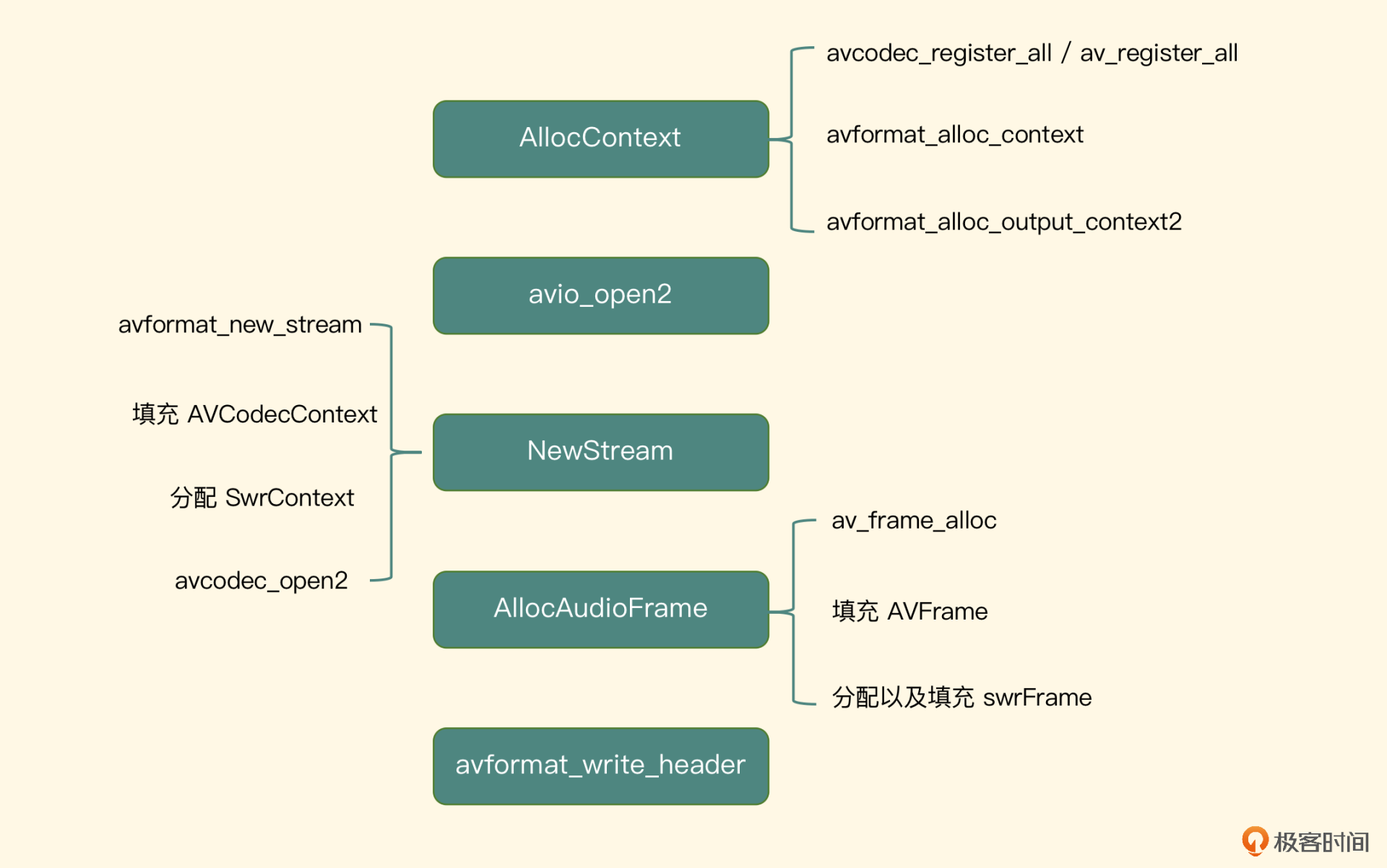 调用 avformat_alloc_context 方法分配出封装格式,然后调用 avformat_alloc_output_context2 传入输出文件格式,分配出上下文,即分配输出封装格式。之后调用 avio_open2 方法将 AAC 的编码路径传入,相当于打开文件连接通道。这样就可以确定 Muxer 与 Protocol 了
调用 avformat_alloc_context 方法分配出封装格式,然后调用 avformat_alloc_output_context2 传入输出文件格式,分配出上下文,即分配输出封装格式。之后调用 avio_open2 方法将 AAC 的编码路径传入,相当于打开文件连接通道。这样就可以确定 Muxer 与 Protocol 了有了容器之后,就应该向容器中添加音频轨了,调用 avformat_new_stream 传入刚才的 FormatContext 构建出一个音频流(AVStream),接着要为这个 Stream 分配一个编码器,编码器是一个 AVCodecContext 类型的结构体,先调用 avcodec_find_encoder_by_name 函数,根据编码器名称找出对应的编码器,接着根据编码器分配出编码器上下文,然后给编码器上下文填充以下几个属性
- 首先是 codec_type,赋值为 AVMEDIA_TYPE_AUDIO,代表音频类型
- 其次是 bit_rate、sample_rate、channels 等基本属性
- 然后是 channel_layout,可选值是两个常量 AV_CH_LAYOUT_MONO 代表单声道、AV_CH_LAYOUT_STEREO 代表立体声
- 最后也是最重要的 sample_fmt,代表采样格式,使用的是 AV_SAMPLE_FMT_S16,即用 2 个字节来表示一个采样点
这样,我们就把 AVCodecContext 这个结构体构造完成了,然后还可以设置 profile,这里可以设置 FF_PROFILE_AAC_LOW。最后调用 avcodec_open2 来打开这个编码器上下文,接下来为编码器指定 frame_size 的大小,一般指定 1024 作为一帧的大小,现在我们就把音频轨以及这个音频轨里面编码器部分给打开了
需要注意的是,某些编码器只允许特定格式的 PCM 作为输入源,比如对声道数、采样率、表示格式(比如 lame 编码器就不允许 SInt16 的表示格式)是有要求的。这时候就需要构造一个重采样器,来将 PCM 数据转换为可适配编码器输入的 PCM 数据,就是前面讲过的需要将输入的声道、采样率、表示格式和输出的声道、采样率、表示格式,传递给初始化方法,然后分配出重采样上下文 SwrContext
接下来还要分配一个 AVFrame 类型的 inputFrame,作为客户端代码输入的 PCM 数据存放的地方,这里需要知道 inputFrame 分配的 buffer 的大小,默认一帧大小是 1024,所以对应的 buffer(按照 uint8_t 类型作为一个元素来分配)大小就应该是
bufferSize = frame_size * sizeof(SInt16) * channels;也可以调用 FFmpeg 提供的方法 av_samples_get_buffer_size 来帮助开发者计算,其实这个方法内部的计算公式就是上面所列的公式。如果需要重采样的处理的话,也需要额外分配一个重采样之后的 AVFrame 类型的 swrFrame,作为最终得到结果的 AVFrame
在初始化方法的最后,需要调用 FFmpeg 提供的方法 avformat_write_header 将这个音频文件的 Header 部分写进去,然后记录一个标志 isWriteHeaderSuccess,使其为 true,因为后续在销毁资源的阶段,需要根据这个标志来判断是否调用 write trailer 方法写入文件尾部
-
编码方法
编码接口定义如下
void encode(byte* buffer, int size);传入的参数是 uint8_t 类型数组和它的长度,这个接口的职责就是将传递进来的 PCM 数据编码并写到文件中。接口内部实现就是将这个 buffer 填充入 inputFrame,因为前面我们已经知道每一帧 buffer 需要填充的大小是多少了,所以这里可以利用一个 while 循环来做数据的缓冲,一次性填充到 AVFrame 中去
调用 avcodec_send_frame,当返回值大于 0 的时候,再调用 avcodec_receive_packet 来得到编码后的数据 AVPacket,然后调用 av_interleave_write_frame 方法,就可以将这个 packet 写到最终的文件中去
-
销毁方法
接口定义如下:
void destroy();这个方法需要销毁前面分配的资源以及打开的连接通道。如果初始化了重采样器,那么就销毁重采样的数据缓冲区以及重采样上下文;然后销毁为输入 PCM 数据分配的 AVFrame 类型的 inputFrame,再判断标志 isWriteHeaderSuccess 变量,决定是否需要填充 duration 以及调用方法 av_write_trailer,然后关闭编码器和连接通道,最终释放 FormatContext
如何使用硬件编码器来编码 AAC?
iOS 平台可使用 Audiotoolbox 下面的 Audio Converter Services 来完成硬件编码,iOS 平台提供的这个服务,看名字就知道它是一个转换服务,那么它能够提供哪几方面的转换呢?
- PCM 到 PCM:可以转换位深度、采样率以及表示格式,也包括交错存储和平铺存储之间的转换,这与 FFmpeg 里的重采样器非常类似
- PCM 到压缩格式的转换:相当于一个编解码器,当然可以应用在编解码场景
iOS 平台在多媒体方面提供的 API 是非常强大的,并且兼容性也非常好
AudioToolbox 里编码出来的 AAC 数据也是裸数据,在写入文件之前也需要手动添加上 ADTS 头信息,最终写出的文件才可以被系统播放器播放,具体添加头信息的操作和 Android 平台的操作是一样的。这里也提供三个接口,分别完成初始化、编码数据和销毁编码器操作
我们先定义一个 Protocol,名称定为 FillDataDelegate,需要调用端来实现这个 Delegate,这里面定义了三个方法
第一个为:
- (UInt32)fillAudioData:(uint8_t *)sampleBuffer bufferSize:(UInt32)bufferSize;
当编码器(转换器)需要编码一段 PCM 数据的时候,就通过调用这个方法来实现这个 Delegate 的调用端来填充 PCM 数据
再看第二个方法的方法原型
- (void)outputAACPakcet:(NSData*)data
presentationTimeMills:(int64_t)presentationTimeMills
error:(NSError*)error;
待编码器成功编码出一帧 AAC 的 Packet 之后,我们先给这段数据添加 ADTS 头,然后通过调用上面这个方法来让调用端输出编码后的数据
最后一个方法原型
- (void)onCompletion;
待编码(转码)结束后,调用上面这个方法来让调用端做资源销毁和关闭 IO 等操作
初始化
首先需要分别配置一个 input 和一个 output 部分的 Description,用来描述编码前后的音频格式
首先是输入部分的 Description 配置
//构建InputABSD
AudioStreamBasicDescription inASBD = {0};
UInt32 bytesPerSample = sizeof (SInt16);
inASBD.mFormatID = kAudioFormatLinearPCM;
inASBD.mFormatFlags = kAudioFormatFlagIsSignedInteger | kAudioFormatFlagIsPacked;
inASBD.mBytesPerPacket = bytesPerSample * channels;
inASBD.mBytesPerFrame = bytesPerSample * channels;
inASBD.mChannelsPerFrame = channels;
inASBD.mFramesPerPacket = 1;
inASBD.mBitsPerChannel = 8 * channels;
inASBD.mSampleRate = inputSampleRate;
inASBD.mReserved = 0;
输出部分的 Description 配置
//构造OutputABSD
AudioStreamBasicDescription outASBD = {0};
outASBD.mSampleRate = inASBD.mSampleRate;
outASBD.mFormatID = kAudioFormatMPEG4AAC;
outASBD.mFormatFlags = kMPEG4Object_AAC_LC;
outASBD.mBytesPerPacket = 0;
outASBD.mFramesPerPacket = 1024;
outASBD.mBytesPerFrame = 0;
outASBD.mChannelsPerFrame = inASBD.mChannelsPerFrame;
outASBD.mBitsPerChannel = 0;
outASBD.mReserved = 0;
Profile 设置为低运算复杂度的规格(LC),因为这样兼容性最好。另外,配置一帧数据的地方需要填写 1024,这是 AAC 编码格式要求的帧大小
接下来需要构造一个编码器实例了,但是构造编码器实例也得从配置一个编码器描述开始。编码器的描述指定编码器类型是 kAudioFormatMPEG4AAC,编码的实现方式使用兼容性更好的软件编码方式 kAppleSoftwareAudioCodecManufacturer。通过这两个输入构造出一个编码器类的描述,它可以告诉 iOS 系统开发者到底想使用哪个编码器
有个这三个 Description,就可以构造一个 AudioConverterRef 实例了,代码如下
OSStatus status = AudioConverterNewSpecific(&inABSD, &outABSD, 1, codecDescription, &_audioConverter);
第三个参数 1 是指明要创建编码器的个数,最后一个参数是转码器实例对象
接下来对这个转码实例设置比特率
AudioConverterSetProperty(_audioConverter, kAudioConverterEncodeBitRate, sizeof(bitRate), &bitRate);
要获取编码之后输出的 AAC 的 Packet Size 最大值是多少,因为我们需要按照这个值来分配编码后数据的存储空间,从而让编码器输出到这个存储区域里面来,代码如下
UInt32 size = sizeof(_aacBufferSize);
AudioConverterGetProperty(_audioConverter, kAudioConverterPropertyMaximumOutputPacketSize, &size, &_aacBufferSize);
_aacBuffer = malloc(_aacBufferSize * sizeof(uint8_t));
memset(_aacBuffer, 0, _aacBufferSize);
编码
第一步构造一个 AudioBufferList 结构体,作为编码器输出 AAC 数据的存储容器,代码如下:
AudioBufferList outAudioBufferList = {0};
outAudioBufferList.mNumberBuffers = 1;
outAudioBufferList.mBuffers[0].mNumberChannels = _channels;
outAudioBufferList.mBuffers[0].mDataByteSize = _aacBufferSize;
outAudioBufferList.mBuffers[0].mData = _aacBuffer;
AudioToolbox 的设计是按照回调函数的方式获取数据源,而这个回调函数就设置在编码函数调用中,编码函数调用如下
UInt32 ioOutputDataPacketSize = 1;
OSStatus status =
AudioConverterFillComplexBuffer(_audioConverter, inInputDataProc, (__bridge void *)(self),
&ioOutputDataPacketSize, &outAudioBufferList, NULL);
最后一个参数是输出 AAC Packet 的 Description,一般填充为 NULL
回调函数的原型如下
OSStatus inInputDataProc(AudioConverterRef inAudioConverter, UInt32
*ioNumberDataPackets, AudioBufferList *ioData,
AudioStreamPacketDescription **outDataPacketDescription,
void *inUserData)
这里直接将 inUserData 强制转换成这个类型的实例对象,就可以调用这个对象的方法了,代码如下
AudioToolboxEncoder *encoder = (__bridge AudioToolboxEncoder *)(inUserData);
[encoder fillAudioRawData:ioData ioNumberDataPackets:ioNumberDataPackets];
接下来我们看这个方法的具体实现,首先根据需要填充的帧的数目、当前声道数以及表示格式,计算出需要填充的 uint8_t 类型的 buffer 大小
int bufferLength = ioNumberDataPackets * channels * sizeof(short);
根据公式算出来的 bufferLength 来分配出 pcmBuffer,然后调用 Delegate 里面的 fillAudioData:bufferSize: 方法来填充数据,最后将 Delegate 中填充好的 pcmBuffer 放入 ioData 容器中并返回,这样就完成了给编码器提供 PCM 数据的回调函数
编码函数执行结束之后,如果 status 是 noErr,那编码好的 AAC 数据就存放在前面定义好的 outAudioBufferList 这个结构体里
从这个结构体的属性 mBuffers[0].mData 中,拿出 AAC 的原始 Packet,添加上 ADTS 头信息,然后调用 Delegate 方法 outputAACPakcet,由 Delegate 输出 AAC 数据,这时候的 AAC 数据就是编码之后带有 ADTS 头信息的数据。最终如果输入数据为空,则代表结束,我们就可以调用 Delegate 的方法 onCompletion,让调用端做一些资源关闭以及销毁操作
销毁
销毁实现里我们先把分配的填充 PCM 数据的 pcmBuffer 释放掉,然后把分配得接收编码器输出的 aacBuffer 释放掉,最后释放掉编码器,代码如下
if(_pcmBuffer) {
free(_pcmBuffer);
_pcmBuffer = NULL;
}
if(_aacBuffer) {
free(_aacBuffer);
_aacBuffer = NULL;
}
AudioConverterDispose(_audioConverter);
最后我们看集成阶段,首先,调用需要实现这个类定义的 FillDataDelegate 类型的 Protocol,并且要重写里面的 fillAudioData 方法,以便给这个编码器类提供 PCM 数据。接着重写 outputAACPakcet 方法来输出 AAC 的码流数据,重写 onCompletion 方法来关闭自己读写文件等操作;然后实例化我们的编码器,开启一个线程(使用 GCD)来调用编码方法;最终编码结束之后,在 dealloc 方法中调用结束编码的方法
iOS 平台如何采集视频画面
视频框架 ELImage 架构设计
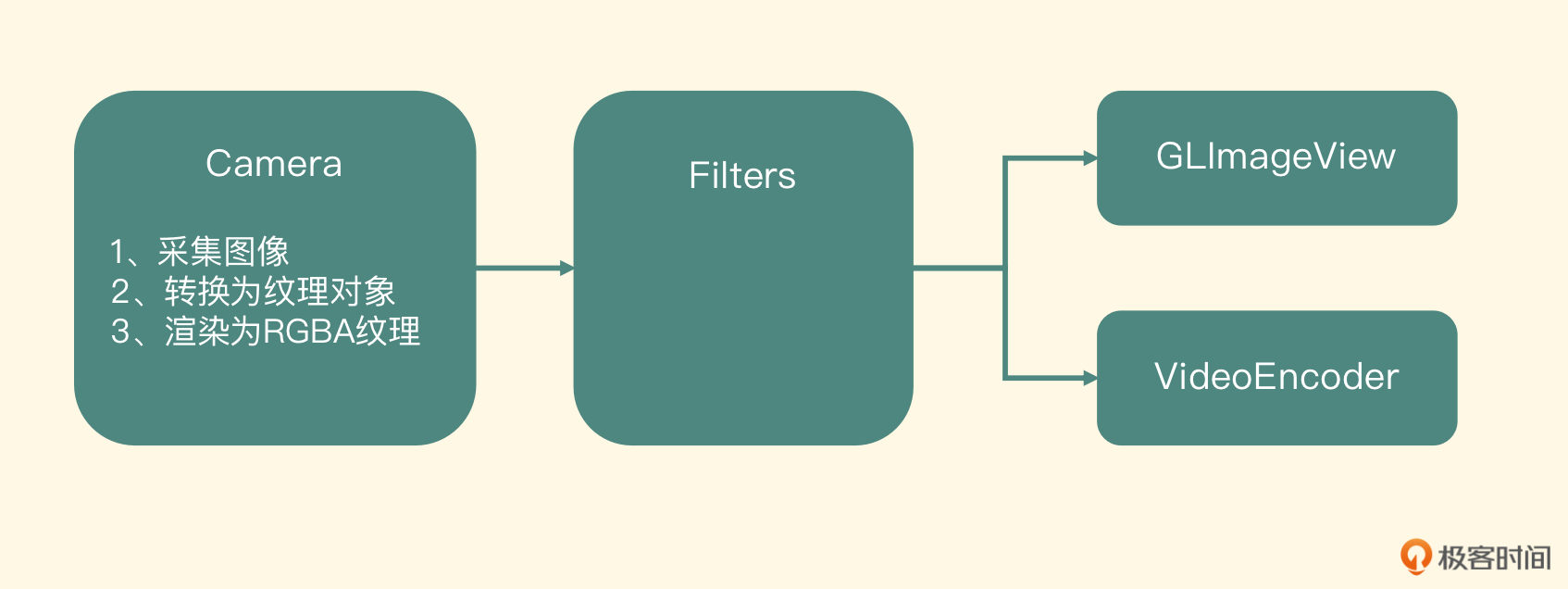
左边第一个节点是用系统提供的 Camera 接口,采集出一帧内存中的图像,然后将这个图像上传到显存中成为 YUV 的纹理对象,最后将这个 YUV 格式的纹理重新渲染到一个 RGBA 的纹理上。接着将这个 RGBA 类型的纹理对象传到中间的 Filters 节点,这个节点内部会使用 OpenGL ES 来处理这个对象,最后输出一个纹理对象到下面的节点
下一级节点是 GLImageView 或将来扩展出来的组件 VideoEncoder,拿到中间 Filters 节点输出之后,进行屏幕渲染或者编码操作。这样一帧图像就从采集、处理到最后预览让用户看到就完成了,并且可以满足我们之后做编码以及图像处理的需求
Camera 和 Filter 这些节点是可以输出纹理的,也就是它们的目标纹理对象要作为后一级节点的输入纹理对象;另外,Filter、GLImageView 以及 VideoEncoder 需要上一级节点提供输入纹理对象。于是有两个规则:
- 凡是需要输入纹理对象的,都是 Input 类型
-
凡是需要向后级节点输出纹理对象的,都是 Output 类型
-
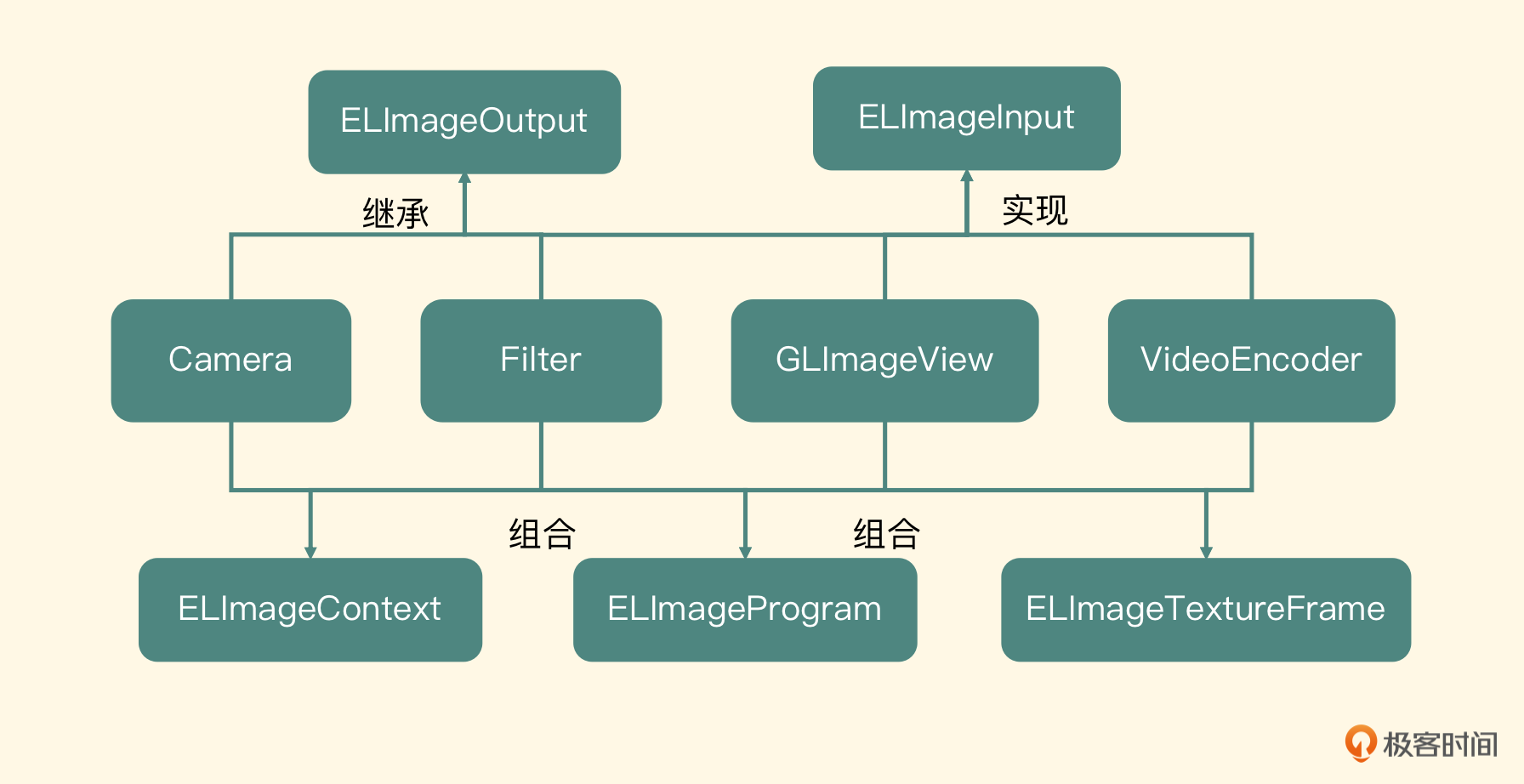
ELImageInput
基于规则一,我们可以定义出 ELImageInput 这样一个 Protocol,因为需要别的组件给它输入纹理对象,所以这个 Protocol 里面定义了两个方法,第一个方法是设置输入的纹理对象
- (void)setInputTexture:(ELImageTextureFrame *)textureFrame;节点中的 Filter、GLImageView 以及 VideoEncoder 都属于 ELImageInput 的类型,所以都应该实现这个方法,在这个方法的实现中应该将输入纹理对象保存为一个属性,等绘制的时候使用。此外,这些节点还有一个共同点,就是都需要做渲染操作,所以接下来第二个方法是执行渲染操作
- (void)newFrameReadyAtTime:(CMTime)frameTime timimgInfo:(CMSampleTimingInfo)timimgInfo;这是上一级节点(实际上是一个 Output 节点)处理完毕之后要调用的方法,在这个方法的实现中可以完成渲染操作
-
ELImageOutput
这个类可以向自己的后级节点输出目标纹理对象,其中 Camera、Filter 节点是需要继承自这个类。根据这个特点我们建立两个属性,一个是渲染目标的纹理对象,一个是后级节点列表,代码如下
ELImageTextureFrame *outputTexture; NSMutableArray *targets;增加和删除目标节点的方法
- (void)addTarget:(id<ELImageInput>)target; - (void)removeTarget:(id<ELImageInput>)target;每个继承这个类的节点,执行渲染过程结束之后,就会遍历 targets 里面所有的目标节点(即 ELImageInput)执行设置输出纹理对象的方法,然后执行下一个节点的渲染过程。代码如下
//Do Render Work for (id<ELImageInput> currentTarget in targets) { [currentTarget setInputTexture:outputTextureFrame]; [currentTarget newFrameReadyAtTime:frameTime timimgInfo:timimgInfo]; } -
ELImageProgram
每一个节点的处理都是一个 OpenGL 的渲染过程,所以每个节点都需要建立一个 GLProgram,我们不可能在每一个节点里面都去分别书写编译 Shader、链接 Program 等代码,所以要先抽取出一个类,取名为 ELImageProgram(EL 是整个项目的前缀),把 GLProgram 的构建、查找属性、使用等这些操作以面向对象的形式封装起来,每一个节点都会组合这个类
-
ELImageTextureFrame
每一个节点的输入都是一个纹理对象(实际上是一个纹理 ID),使用 GLProgram 将这个纹理对象渲染到一个目标纹理对象的时候,还需要建立一个帧缓存对象(FBO),并且要将这个目标纹理对象 Attach 到这个帧缓存对象上。所以这里我们抽取一个类,取名为 ELImageTextureFrame,将纹理对象和帧缓存对象的创建、绑定、销毁等操作,以面向对象的方法封装起来,让每一个节点使用起来都更加方便
-
ELImageContext
要想使用 OpenGL ES,必须有上下文以及关联的线程,iOS 平台为 OpenGL ES 提供了 EAGL 作为 OpenGL ES 的上下文。后面我们书写编码器组件的时候,因为不希望它阻塞预览线程,所以需要单独开辟一个编码线程,也需要一个额外的 OpenGL 上下文,并且需要和渲染线程共享 OpenGL 上下文。只有这样,在编码线程中才可以正确访问到预览线程中的纹理对象、帧缓存对象
所以我们抽取一个类,取名叫做 ELImageContext,来封装 EAGLContext 和渲染线程。因为可能多个对象都要在调用线程和 OpenGL ES 的线程之间进行切换,所以需要给这个类书写一个静态方法,获得渲染线程的 OpenGL 上下文,并且提供静态方法可以得到这个 dispatch_queue,让一些 OpenGL ES 的操作可以直接在这个线程中执行,具体的代码如下
+ (void)useImageProcessingContext { [[ELImageContext sharedImageProcessingContext] useAsCurrentContext]; } - (void)useAsCurrentContext { EAGLContext *imageProcessingContext = [self context]; if ([EAGLContext currentContext] != imageProcessingContext) { [EAGLContext setCurrentContext:imageProcessingContext]; } }基于以上分析,我们画出了对应的类图
摄像头配置
配置摄像头:
AVCaptureSession* captureSession;
captureSession = [[AVCaptureSession alloc] init];
然后需要配置出 AVCaptureDeviceInput,这个对象代表了我们要使用哪个摄像头,比如使用前置摄像头
AVCaptureDevice * captureDevice = nil;
NSArray *devices = [AVCaptureDevice devicesWithMediaType:AVMediaTypeVideo];
for (AVCaptureDevice *device in devices) {
if ([device position] == AVCaptureDevicePositionFront) {
captureDevice = device;
}
}
captureInput = [[AVCaptureDeviceInput alloc] initWithDevice:captureDevice error:nil];
接着要配置出 AVCaptureVideoDataOutput,这个对象用来处理摄像头采集到的数据
dispatch_queue_t dataCallbackQueue;
dataCallbackQueue = dispatch_queue_create("dataCallbackQueue",
DISPATCH_QUEUE_SERIAL);
captureOutput = [[AVCaptureVideoDataOutput alloc] init];
[_captureOutput setSampleBufferDelegate:self queue:dataCallbackQueue];
构造出 captureOutput 这个实例之后,要想获取摄像头采集的数据,就需要传入类型为 AVCaptureVideoDataOutputSampleBufferDelegate 的实例和一个 dispatch_queue
接下来,我们需要设置一个像素格式,默认使用 YUVFullRange 的表示格式,所谓的 FullRange,表示 YUV 的取值范围是 0 到 255;还有一种是 YUVVideoRange 的表示格式,为了防止溢出,我们把 YUV 的取值范围设置成 16 到 235。Range 的类型会决定 YUV 格式转换为 RGBA 格式时使用的矩阵,所以这里我们要根据支持的格式来设置,并且记录设置的格式,之后用来确定 YUV 到 RGBA 的转换矩阵
接着将 captureInput 实例和 captureOutput 实例配置到 CaptureSession 中
if ([self.captureSession canAddInput:self.captureInput]) {
[self.captureSession addInput:self.captureInput];
}
if ([self.captureSession canAddOutput:self.captureOutput]) {
[self.captureSession addOutput:self.captureOutput];
}
然后调用 captureSession 设置分辨率的方法,你可以看一下常见的分辨率以及设置代码
NSString* highResolution = AVCaptureSessionPreset1280x720;
NSString* lowResolution = AVCaptureSessionPreset640x480;
[_captureSession setSessionPreset:[NSString stringWithString: highResolution]];
接着调用 CaptureSession 的 beginConfiguration 方法,配置整个摄像头会话,最后取出 captureOutput 里面的 AVCaptureConnection,来配置摄像头输出的方向,这是非常重要的,如果不配置这个参数,摄像头默认输出横向的图片,我们使用代码把它设置成纵向图片输出
conn.videoOrientation = AVCaptureVideoOrientationPortrait;
当然,也可以给 CaptureInput 设置帧率等信息
摄像头采集数据处理
AVCaptureVideoDataOutputSampleBufferDelegate 协议,重写了接收摄像头采集数据的方法,签名如下:
-(void) captureOutput:(AVCaptureOutput*)captureOutput
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection*)connection
这个方法会把具体是哪一个 captureOutput 以及 connection 返回过来,但是最重要的其实是 CMSampleBuffer 类型的 sampleBuffer,这里面存储着摄像头采集到的图像。一个 CMSampleBuffer 由以下三部分组成:
- CMTime,代表这一帧图像的时间
- CMVideoFormatDescription,代表对这一帧图像格式的描述
- CVPixelBuffer,代表这一帧图像的具体数据
在这个回调函数里,我们需要完成从摄像头采集到图像渲染的全过程,而渲染部分会使用 OpenGL ES 来操作
iOS 平台不允许 App 进入后台的时候还执行 OpenGL 渲染,通用的处理方式就是之前在播放器中用到的方式,分别注册 applicationWillResignActive 和 applicationDidBecomeActive 通知,在这两个方法中将这个类中的 shouldEnableOpenGL 属性设置为 NO 和 YES。然后在回调函数中判断这个变量,决定是否可以执行 OpenGL 操作
-(void) captureOutput:(AVCaptureOutput*)captureOutput didOutputSampleBuffer:
(CMSampleBufferRef)sampleBuffer fromConnection:
(AVCaptureConnection*)connection {
if (self.shouldEnableOpenGL) {
if (dispatch_semaphore_wait(_frameRenderingSemaphore,
DISPATCH_TIME_NOW) != 0) {
return;
}
CFRetain(sampleBuffer);
runAsyncOnVideoProcessingQueue(^{
[self processVideoSampleBuffer:sampleBuffer];
CFRelease(sampleBuffer);
dispatch_semaphore_signal(_frameRenderingSemaphore);
});
}
}
代码显示,首先要判断这个布尔值,如果是 NO 的话,就不执行任何操作;如果是 YES 的话,要保证上一次渲染执行结束了(通过 dispatch_semaphore 的 wait 来确定)才可以执行本次渲染操作
执行渲染操作的时候首先要使用 CFRetain 锁定这个 sampleBuffer,因为真正使用 sampleBuffer 的地方是在 OpenGL ES 线程中,只有这里 Retain 住才能保证 sampleBuffer 不被污染,等这一次 OpenGL ES 的渲染操作结束之后,再使用 CFRelease 释放这个 sampleBuffer。最后给 semaphore 发一个 signal 指令
接下来我们看一下真正的渲染操作,也就是方法 processVideoSampleBuffer 的实现,这个方法需要将 sampleBuffer 对象渲染成为一个纹理对象,然后调用后续的 targets 节点进行渲染
我们先取出这个 sampleBuffer 中的图像数据,即它的属性 CVPixelBuffer,然后我们需要确定这个 CVPixelBuffer 里面 YUV 转换成 RGB 的矩阵。我们根据两方面的内容来确定这个矩阵
- 给摄像头配置的像素格式,是 YUVFullRange 还是 YUVVideoRange
- 取出 PixelBuffer 里面的 YUV 转换类型,我们判断这个类型是 ITU601 还是 ITU709 格式,ITU601 是 SDTV 的标准,而 ITU709 是 HDTV 的标准,因为标清与高清对应的 YUV 转换为 RGB 的矩阵是不同的
这两方面共同决定了 YUV 转换成 RGB 的矩阵,其中只有 ITU601 分为 YUVFullRange 和 YUVVideoRange 两种,而 ITU709 就只有一种,根据组合从以下三个矩阵中选出合适的矩阵
GLfloat colorConversion601Default[] = {
1.164, 1.164, 1.164,
0.0, -0.392, 2.017,
1.596, -0.813, 0.0,
};
GLfloat colorConversion601FullRangeDefault[] = {
1.0, 1.0, 1.0,
0.0, -0.343, 1.765,
1.4, -0.711, 0.0,
};
GLfloat colorConversion709Default[] = {
1.164, 1.164, 1.164,
0.0, -0.213, 2.112,
1.793, -0.533, 0.0,
};
准备工作完成之后,接下来就进入真正渲染过程
先绑定 OpenGL ES 的上下文,需要调用前面我们封装的 ELImageContext 绑定上下文的方法。然后创建这个节点的输出纹理对象,就是构建一个 ELImageTextureFrame 对象,并且激活这个纹理对象(代表这个渲染过程的目标就是这个纹理对象)
准备输入纹理,要将 CVPixelBuffer 中的 YUV 数据关联到两个纹理 ID 上。如果是在其他平台上,只能通过 OpenGL ES 提供的 glTexImage2D 方法,将内存中的数据上传到显卡的一个纹理 ID 上。但是这种内存和显存之间的数据交换效率是比较低的,在 iOS 平台的 CoreVideo framework 中提供了 CVOpenGLESTextureCreateTextureFromImage 方法,可以使整个交换过程更加高效
由于 CVPixelBuffer 内部数据是 YUV 数据格式的,所以可分配以下两个纹理对象分别存储 Y 和 UV 的数据
CVOpenGLESTextureRef luminanceTextureRef = NULL;
CVOpenGLESTextureRef chrominanceTextureRef = NULL;
需要在使用 CVPixelBuffer 这块内存区域之前,先锁定这个对象,使用完毕之后解锁。以下代码可锁定这个 PixelBuffer
CVPixelBufferLockBaseAddress(pixelBuffer, 0);
然后拿出这里面的 Y 通道部分的内容,上传到 luminanceTextureRef 里
CVOpenGLESTextureCacheCreateTextureFromImage(
kCFAllocatorDefault, coreVideoTextureCache, pixelBuffer,
NULL, GL_TEXTURE_2D, GL_LUMINANCE, bufferWidth,
bufferHeight, GL_LUMINANCE, GL_UNSIGNED_BYTE, 0,
&luminanceTextureRef);
代码中传入了 pixelBuffer 以及格式 GL_LUMINANCE,还需要传入宽和高。这样这个 API 内部就知道访问 pixelBuffer 的哪部分数据了,里面还有一个非常重要的参数,就是纹理缓存,而创建的纹理会从这个纹理缓存中拿出来,纹理缓存的创建代码如下
CVOpenGLESTextureCacheCreate(kCFAllocatorDefault, NULL, context, NULL, &coreVideoTextureCache)
可以看到,创建纹理缓存必须要传入 OpenGL 上下文,所以我们一般在 ELImageContext 中维护一个纹理缓存。使用 Y 通道的数据内容创建出来的纹理对象可以通过 CVOpenGLESTextureGetName 来获取出纹理 ID。以下代码可以把 UV 通道部分上传到 chrominanceTextureRef 里
CVOpenGLESTextureCacheCreateTextureFromImage(kCFAllocatorDefault, coreVideoTextureCache, pixelBuffer,
NULL, GL_TEXTURE_2D, GL_LUMINANCE_ALPHA, bufferWidth/2,
bufferHeight/2, GL_LUMINANCE_ALPHA, GL_UNSIGNED_BYTE, 1,
&chrominanceTextureRef)
YUV420P 格式规定,每四个像素会有一个 U 和一个 V,用 GL_LUMINANCE_ALPHA 来表示 UV 部分,即 U 放到 Luminance 部分,V 放到 Alpha 部分。理解这一点是非常重要的,因为这关乎后面在 FragmentShader 中如何拿到正确的 YUV 数据
接下来,就是实际的渲染了,在渲染过程中需要注意两点,一是确定物体坐标和纹理坐标;二是在 FragmentShader 中,怎么把 YUV 转换成 RGBA 的表示格式。我们先来看如何确定物体坐标和纹理坐标,物体坐标其实是固定的,物体坐标如下
GLfloat squareVertices[8] = {
-1.0, -1.0, //物体左下角
1.0, -1.0,//物体右下角
-1.0, 1.0, //物体左上角
1.0, 1.0 //物体右上角
};
而确定纹理坐标会麻烦一点,记得我们之前讲过,OpenGL 纹理坐标系和计算机坐标系是不同的吗?所以默认情况下,纹理坐标如下
GLfloat textureCoords[8] = {
0.0,1.0,
1.0,1.0,
0.0,0.0,
1.0,0.0
};
进行旋转以及镜像的时候,都是根据这个纹理坐标来实施的。左边第一张图是前置摄像头采集到的图像
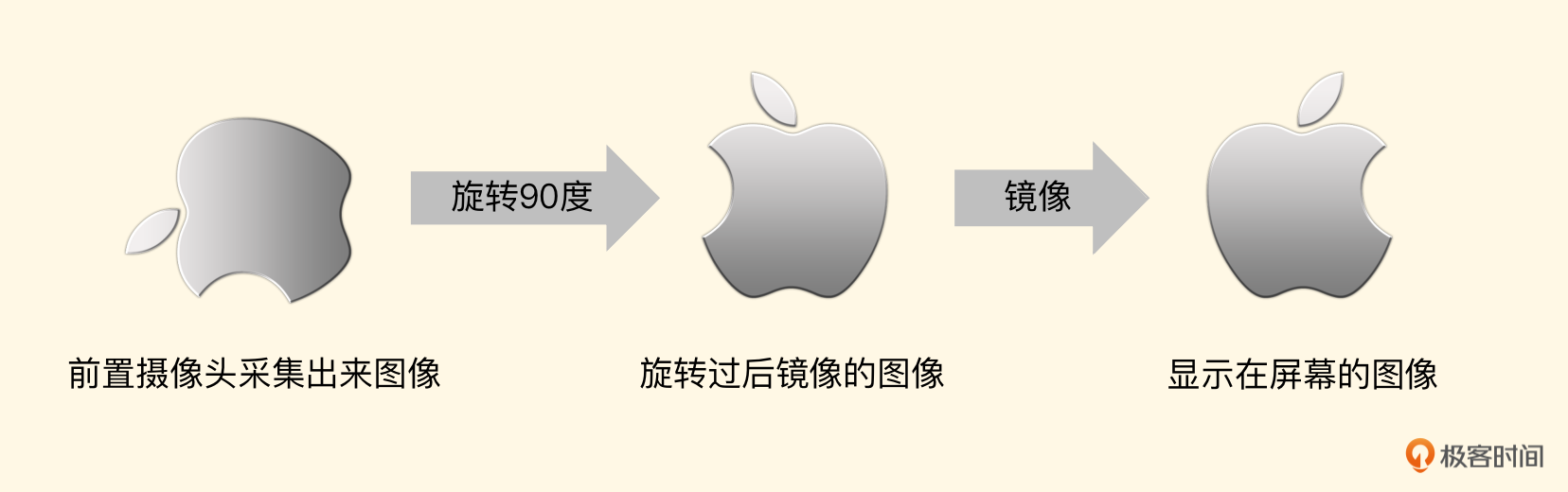 要想正确地显示,需要先按照顺时针旋转 90 度,由于是前置摄像头,还得做一个镜像处理,所以我们的纹理坐标如下:
要想正确地显示,需要先按照顺时针旋转 90 度,由于是前置摄像头,还得做一个镜像处理,所以我们的纹理坐标如下:
GLfloat textureCoords[8] = {
1.0,0.0,
1.0,1.0,
0.0,0.0,
0.0,1.0
};
如果是后置摄像头,那么我们应顺时针旋转 90 度
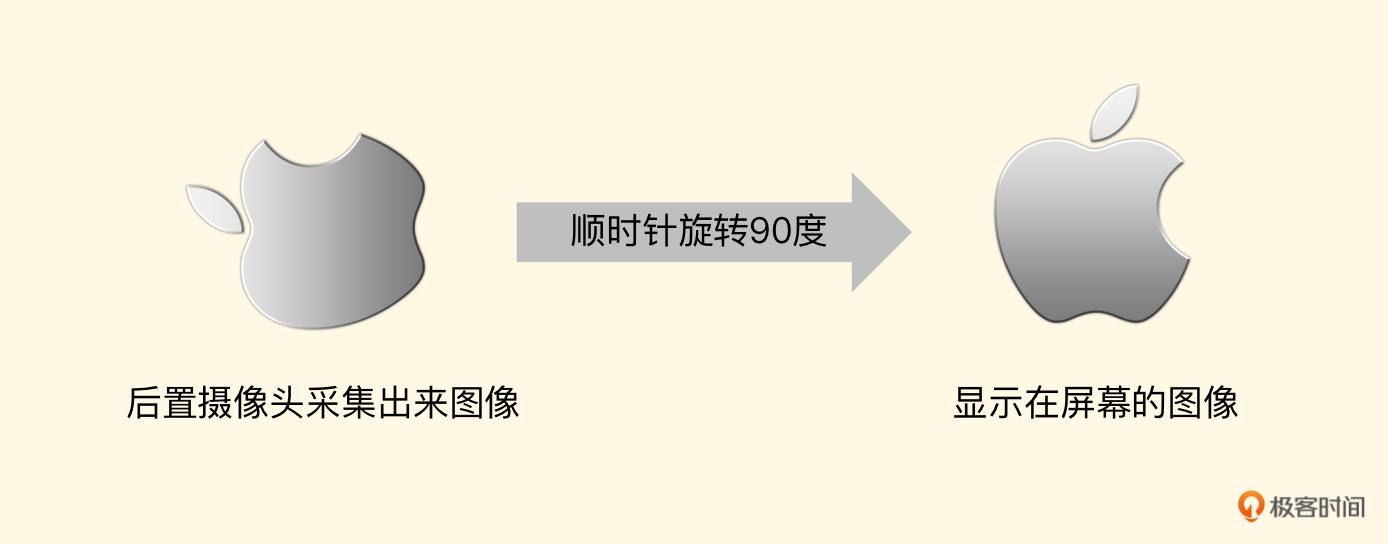 顺时针旋转 90 度的纹理坐标如下
顺时针旋转 90 度的纹理坐标如下
GLfloat textureCoords[8] = {
1.0,1.0,
1.0,0.0,
0.0,1.0,
0.0,0.0
};
这里有一点需要特别注意的是,由于把纹理做了 90 度的旋转,所以目标纹理对象宽高和输入纹理(CVPixelBuffer)的宽高需要对调一下
上述纹理坐标是默认摄像头给出的图像纹理坐标,但前面我们给摄像头做过一个特殊的设置,就是给 AVCaptureConnection 设置 videoOrientation 这个参数,摄像头默认是横向视频输出,当把这个参数设置为 Portrait 时,就要求摄像头安装竖直方向输出视频。这时候目标纹理对象的宽高和 CVPixelBuffer 的宽高一致了,那么后置摄像头采集出来的图像直接绘制即可
所对应的纹理坐标为
GLfloat textureCoords[8] = {
0.0,1.0,
1.0,1.0,
0.0,0.0,
1.0,0.0
};
而前置摄像头由于镜像的原因,所以绘制过程如下图所示:
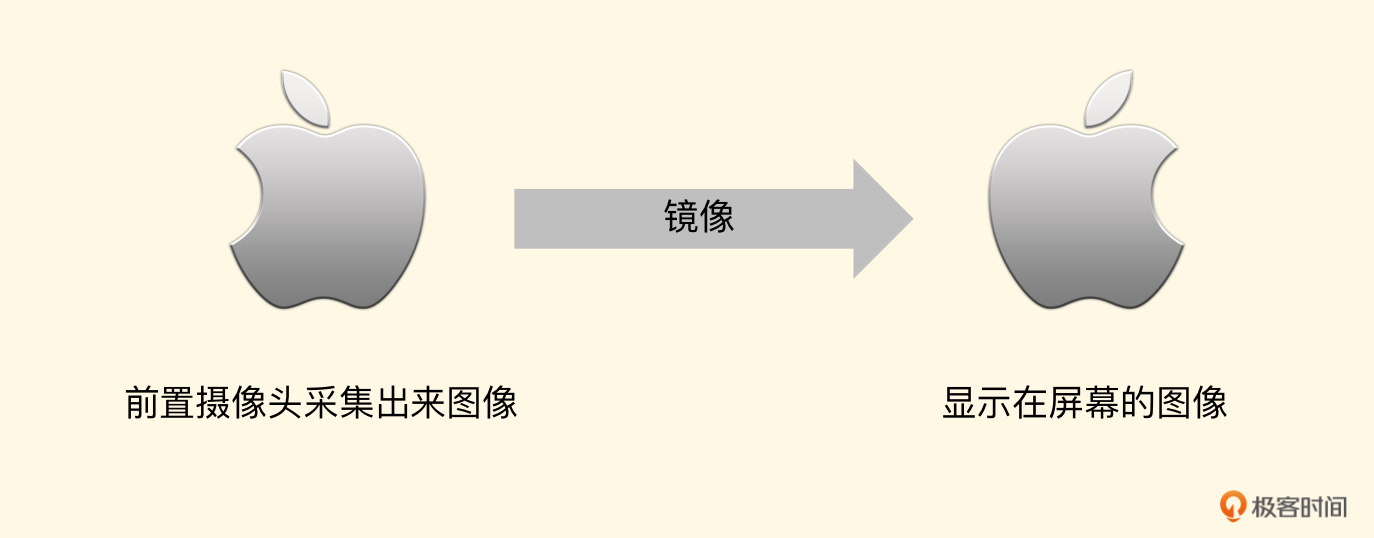 此时的纹理坐标正好和后置摄像头的每一个坐标的 X 点相反
此时的纹理坐标正好和后置摄像头的每一个坐标的 X 点相反
GLfloat textureCoords[8] = {
1.0,1.0,
0.0,1.0,
1.0,0.0,
0.0,0.0
};
确定物体坐标与纹理坐标之后,我们就来看一下如何在 FragmentShader 中,将 YUV 转换成 RGBA。注意:这里是一定要转换成 RGBA 的,因为在 OpenGL 中通用的渲染纹理格式都是 RGBA 的,包括纹理处理、渲染到屏幕上以及最终编码器,都是以 RGBA 格式为基础进行转换和处理的。在播放器的部分我们已经做过一次 YUV 转 RGBA 的操作,但是由于使用了 CoreVideo 这个 framework 下的快速上传,输入的纹理变得不一样了,所以我们来看下具体的 FragmentShader
varying highp vec2 textureCoordinate;
uniform sampler2D luminanceTexture;
uniform sampler2D chrominanceTexture;
uniform mediump mat3 colorConversionMatrix;
void main(){
mediump vec3 yuv;
lowp vec3 rgb;
yuv.x = texture2D(luminanceTexture, textureCoordinate).r;
yuv.yz = texture2D(chrominanceTexture, textureCoordinate).ra - vec2(0.5, 0.5);
rgb = colorConversionMatrix * yuv;
gl_FragColor = vec4(rgb, 1);
}
其中 textureCoordinate 是纹理坐标,而这两个 sampler2D 类型就是从 CVPixelBuffer 里面上传到显存中的纹理对象,3x3 的矩阵就是前面根据像素格式,以及是否为 FullRange 选择的变换矩阵。我们重点看一下如何取出 Y 和 UV
- 由于 luminanceTexture 使用的是 GL_LUMINANCE 格式上传上来的纹理,所以这里使用 texture2D 函数拿出像素点之后,访问元素 r 就可以拿到 Y 通道的值了
- 而 UV 通道使用的是 GL_LUMINANCE_ALPHA 格式,通过 texture2D 取出像素点之后,访问元素 r 得到 U 的值,访问元素 a 得到 V 的值。但为什么 UV 值要减去 0.5(换算为 0 - 255 就是减去 127)?这是因为 UV 是色彩分量,当整张图片是黑白的时候,UV 分量是默认值 127,所以这里要先减去 127,然后再转换成 RGB,否则会出现色彩不匹配的错误
最后使用传递进来的转换矩阵乘以 YUV,得到这个像素点的 RGBA 表示格式,并赋值给 gl_FragColor
最终这个节点会输出一个纹理 ID,这个纹理 ID 可以直接渲染到 ELImageView 中让用户看到摄像头预览的效果
视频编码的工作原理与 H.264 封装格式
编码标准介绍
我想你一定知道你 JPEG 格式的图片吧,其实它就是 ISO 制定的 JPEG 的图像编码标准。对于视频,ISO 同样也制定了标准,Motion JPEG 就是 MPEG,MPEG 算法是适用于动态视频的压缩算法,它除了可以对单幅图像进行编码外,还可以利用图像序列中的相关性原则,去掉冗余信息,这样就可以大大提高视频的压缩比
发展到现在,MPEG 也已经经历过了好多代,版本一直在不断更新中,主要有这几个版本:Mpeg1,VCD 用的就是它;Mpeg2,在 DVD 中使用;还有 Mpeg4 AVC,现在的流媒体中使用最多的就是它了
相较于 ISO 制定的 MPEG 的视频压缩标准,ITU-T 制定的 H.261、H.262、H.263、H.264 一系列视频编码标准是另外一套体系。其中 H.264 汲取了以往标准制定中积累的经验,采用简洁的设计,使用的范围越来越广
现在用得最多的就是 H.264 标准,H.264 创造了多参考帧、多块类型、整数变换、帧内预测等新的压缩技术,使用了更精细的分象素运动矢量(1/4、1/8)和新一代的环路滤波器,大大提高了压缩性能,系统更加完善。从 H.264 开始,它与 Mpeg 标准的 AVC 合并成为了一个,后续又衍生出了 H.265、H.266 等新一代的视频编码标准
除了上述两个组织制定的标准之外,还有 Google 制定的 VP 系列的视频编码和我们国家 AVS 工作组制定的 AVS 编码标准,整体的图示如下图所示
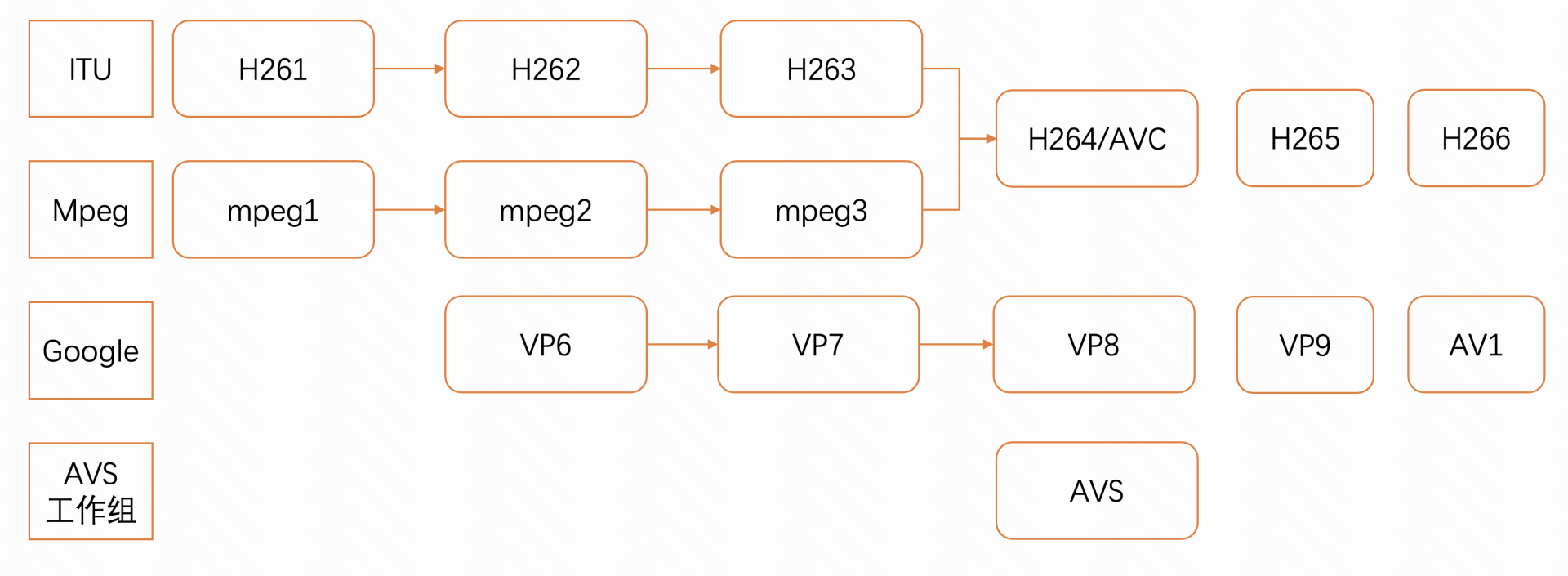
编码器的工作编码原理介绍
-
消除时间上的冗余信息
我们先来一起讨论一下如何消除视频帧在时间上的冗余信息,比较成熟的技术就是帧间预测技术(inter-frame prediction),先来看这两帧视频帧
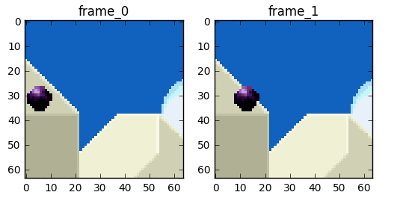
我们将去除掉时间上的冗余信息来达到使用更少的字节存储这两帧视频帧的目的,首先想到的就是这两帧视频帧相减,得到 Diff 值,就是我们要进行编码的东西,如下图所示
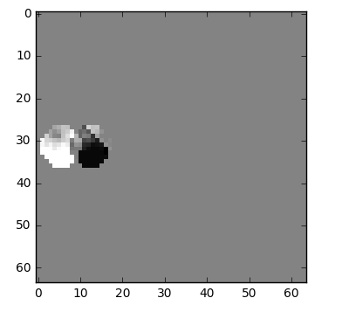
但其实还有一种更好的方法,可以使用更少的比特数来存储第二帧视频帧的内容,首先我们将每一帧视频帧(frame_0)分为很多个部分,然后将这两帧视频帧中的每一部分进行匹配,这种算法我们可以看作是运动估计,如下图所示
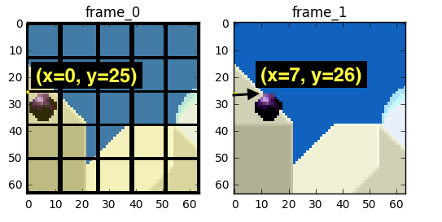
在第一帧变化到第二帧的过程中,我们可以估计第一帧视频帧中的黑色球从点(x=0, y=25)到点(x=7, y=26),而 x 和 y 组成的值的集合就叫做运动向量。我们可以更进一步来节省编码内容,即只对这两帧之间的运动矢量差进行编码,所以最终运动矢量是 x=6(6-0)) y=1(26-25)。当然在真实的编码过程中,图中的小球会再被划分为 N 个部分,前面把它当作一部分只是为了方便理解。所以我们可以看到,当应用了运动估算算法之后,编码的数据要比简单地计算 Diff 值进行编码的数据要少得多
我们可以使用 FFmpeg 工具来查看一个视频编码的运动矢量情况,命令如下
ffplay -flags2 +export_mvs -vf codecview=mv=pf+bf+bb input.flv到这里,时间冗余信息我们可以靠运动估计算法给消除掉了,而要想使用运动估计,就需要一个帧作为参考帧,一般称之为 I 帧
H264 的 NALU
NALU 的全称是 Network Abstract Layer Unit,即网络抽象层,在 H.264/AVC 视频编码标准中,整个系统框架被分成了两层,即视频编码层面(VCL)和网络抽象层面(NAL)。前者负责有效表示视频数据的内容,而后者负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。我们平时的每帧数据就是一个 NAL 单元,也就是我们常说的 NALU。一个完整的 NALU 由 Header 和 Payload 组成,其中 Header 部分占一个字节,每一位代表含义如下:
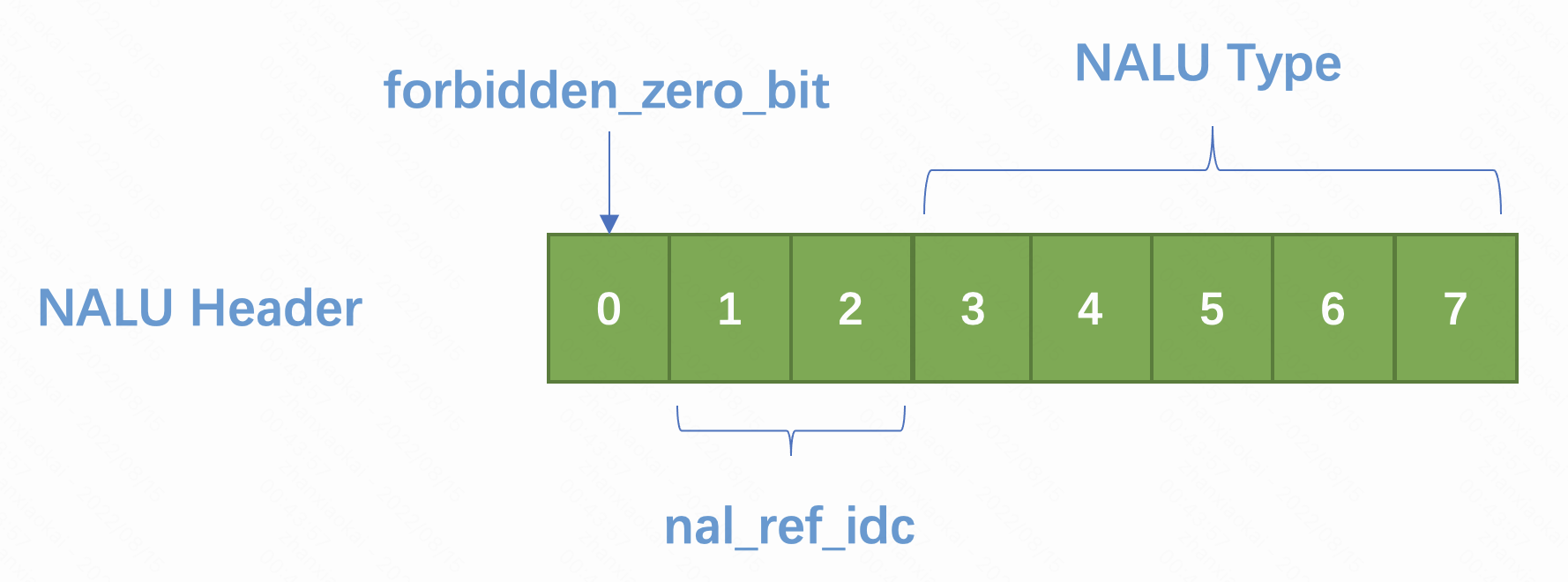 其中第一位固定为 0;第二位、第三位组成一个 nal_ref_idc 代表了这个 NAL 的重要性,取值范围是 0~3,值越大表示当前 NALU 越重要,需要优先受到保护,比如 IDR、SPS、PPS 类型的 NALU,这个值一定不是 0;最后 5 位共同组成 NALUType,判定规则就是“与”上 0x1f 得出的值再和下述数值做比较
其中第一位固定为 0;第二位、第三位组成一个 nal_ref_idc 代表了这个 NAL 的重要性,取值范围是 0~3,值越大表示当前 NALU 越重要,需要优先受到保护,比如 IDR、SPS、PPS 类型的 NALU,这个值一定不是 0;最后 5 位共同组成 NALUType,判定规则就是“与”上 0x1f 得出的值再和下述数值做比较
enum nal_unit_type_e {
NAL_UNKNOWN = 0,
NAL_SLICE = 1,
NAL_SLICE_DPA = 2,
NAL_SLICE_DPB = 3,
NAL_SLICE_DPC = 4,
NAL_SLICE_IDR = 5, /* ref_idc != 0 */
NAL_SEI = 6, /* ref_idc == 0 */
NAL_SPS = 7,
NAL_PPS = 8,
NAL_AUD = 9,
NAL_FILLER = 12,
};
SEI 帧代表视频增强信息的帧,像之前风靡一时的视频答题应用就使用这种类型的帧来承载题目以及答案,通常用法是把这个帧加入到每一个关键帧的前面
SPS 和 PPS 保存了一组编码视频序列的全局参数,每一帧编码后的数据所依赖的参数保存在图像参数集里,里面的信息至关重要,如果其中的数据丢失或出现错误,那么解码过程很可能会失败。一般情况下 SPS 和 PPS 的 NAL Unit 处于整个码流的起始位置,初始化解码器的时候需要将这两者设置给解码器。你从图中也可以看到像 SEI 帧它的 nal_ref_idc 就是等于 0 的,而像 IDR、SPS、PPS 类型的 nal_ref_idc 就不能为 0
H.264 的封装格式
H.264 的编码也有两种封装格式,一种是 AVCC 格式,一种是 Annex-B 格式
-
AVCC 格式
AVCC 格式也叫 AVC1 格式,是属于 MPEG-4 标准定义的格式,通常用于存储 MP4/FLV/MKV 等文件,也可以用于 RTMP 直播中,格式如图所示:
 最前面是 extraData 部分,这部分描述了整体编码的一些信息,主要部分是由 sps 和 pps 组成,后边跟的是许多个 NALU,但是每一个 NALU 前面一般会使用 4 个字节来表示这个 NALU 的长度,然后紧接着跟着这个 NALU
最前面是 extraData 部分,这部分描述了整体编码的一些信息,主要部分是由 sps 和 pps 组成,后边跟的是许多个 NALU,但是每一个 NALU 前面一般会使用 4 个字节来表示这个 NALU 的长度,然后紧接着跟着这个 NALU -
Annex-B 格式
Annex-B 格式也叫 MPEG-2 transport stream format 格式,是属于 MPEG-4 标准定义的格式,通常用于 ts 流以及视频会议中,格式如下图所示
 其中 startCode 有可能是三个字节或者四个字节,会用 0x001 或者 0x0001 来表示,这个格式会以它作为 NALU 的分界点,SPS 和 PPS 按照一个 NALU 的方式写在头部
其中 startCode 有可能是三个字节或者四个字节,会用 0x001 或者 0x0001 来表示,这个格式会以它作为 NALU 的分界点,SPS 和 PPS 按照一个 NALU 的方式写在头部在 FFmpeg 中提供了一个 bitstreamFilter 叫做 h264_mp4toannexb,在解码场景中可以方便地将 AVCC 格式的 H.264 转换为 Annexb 格式的 H.264。当然在编码场景中,如果需要逆方向的格式转换,你也可以自己将 startCode 部分替换为 NALULength
Share
Slither Link
https://crypto.stanford.edu/pbc/notes/zdd/slither.html
在一个练习中,Knuth 描述了如何在一个网格图中快速计算代表简单循环家族的 ZDD。这里,领域是所有边的集合,这样家族的每个成员是一个边的集合形成一个简单的循环
想象你完全不知道 ZDD 且被问在网格图中统计简单循环的个数。也许你可能用动态规划,但什么是合理的子问题?一个自然的接近是检查给定边的简单循环必须包含,且其他边必须排除
构建 ZDD 在相同过程中是必须的。我们从底向上构建 ZDD;更小的 ZDD 代表更小的子图
| n | n x n 网格图的循环 | 平均循环长度 | 标准偏差 |
|---|---|---|---|
| 2 | 2 | 2.000000 | 2.000000 |
| 3 | 14 | 5.714286 | 2.249717 |
| 4 | 214 | 10.710280 | 2.771717 |
| 5 | 9350 | 17.462246 | 3.152186 |
| 6 | 1222364 | 25.768157 | 3.724317 |
| 7 | 487150372 | 35.805114 | 4.284285 |
| 8 | 603841648932 | 47.479949 | 4.756736 |
| 9 | 2318527339461266 | 60.709770 | 5.221515 |
| 10 | 273592644067916806102 | 75.502314 | 5.707011 |
| 11 | 988808811046283595068100 | 91.876952 | 6.201849 |
| 12 | 109331355810135629946698361372 | 109.838303 | 6.697420 |
我们可对包含 n 条边中 4 个边的集合构建 ZDD。这样,对每个线索构建这样一个 ZDD 且用 ZDD 简单循环相交来得到解决方案
然而,如果我们首先构造 ZDD $ \mathbb{Z} $ 代表满足所有线索的集合,我们可更快解决迷宫,且根据构建简单循环 ZDD 的算法,除了我们呈现在 $ \mathbb{Z} $ 中表示的限制。事实上,对更大的迷宫计算简单循环 ZDD 太过昂贵,这个处理有时能更低成本地解决问题