Table of Contents
Algorithm
Leetcode 352: https://leetcode.com/problems/data-stream-as-disjoint-intervals/
https://dreamume.medium.com/leetcode-352-data-stream-as-disjoint-intervals-75e178107288
Review
Lightweight Causal and Atomic Group Multicast
ISIS toolkit是分布式编程环境基于虚拟同步进程组和组通讯。我们呈现一族新的协议支持该模型。我们的处理最主要关注于原始多播,称为CBCAST,实现了容错,关系序消息转发。CBCAST可被直接使用,或扩展到原始总序多播,称为ABCAST。它在接收到之后正常立即转发消息,且强制一个空间超过发送者所属的组大小的一定比例,通常为一个小数字。协议都实现作为ISIS最近版本的一部分且我们讨论一些编程问题及性能。我们的工作使我们包含进程组和组通讯可达成性能和扩展比较消息传输层 - 找到矛盾广泛关心于分布式计算的这种风格可能不可接受
简介
ISIS toolkit
ISIS toolkit提供各种工具在一个松耦合分布式环境下构建软件。系统成功地处理分布式一致性、协同分布式算法和容错问题。在本文写作时,Toolkit 2.1版本被使用在数百个地方
ISIS的两个方面是它的关键:
- 虚拟同步进程组的实现。这样的一个组包含一系列进程合作执行一个分布式算法,复制数据,提供一个服务容错或利用分布式
- 一系列可靠多播协议,进程和组成员跟组交互。ISIS可靠性包含故障原子性,转发顺序保障和一个组处理原子性形式,其成员改变通过组通讯同步
虽然ISIS支持大范围的多播协议,一个协议称为CBCAST称为系统通讯的多数。事实上,许多ISIS工具只是原始地调用该通讯。例如,ISIS复制数据工具使用单个(异步)CBCAST来执行每个更新和加锁操作;读不需要通讯。一个结论是CBCAST的开销代表ISIS系统的性能瓶颈
原始ISIS CBCAST协议的开销部分为结构原因,部分因为协议的使用。实现用一个协议服务器,因此所有CBCAST通讯经由一个间接路径。独立于协议本身的开销,该间接路径是昂贵的。更进一步,协议服务器证明扩展比较困难,限制初始ISIS版本为网络上几百个节点。对于协议使用,我们的初始化实现更喜欢一般化而不是特化因此允许特别灵活地目标地址。它使用其他的算法达成CBCAST顺序属性但需要定期的垃圾收集
地址灵活性在现在看来很弱,ISIS经验使我们关注于系统如何使用,允许我们聚焦核心功能。本文中描述协议支持高并发应用程序,扩展系统为巨量覆盖进程组和边界为过载的信息跟发送者消息所属的进程组大小成比例。虽然没有早期版本那么一般化,新的协议能够支持ISIS toolkit和所有我们熟悉的ISIS应用程序。该一般化化略的好处是使我们的系统在性能和扩张性上有显著地增长。事实上,新的协议套装没有对它支持的系统扩展有明显地限制。在应用程序本地化、爆发的通讯、多数多播将携带只是一个必要的小开销而不管使用的组的数量和大小这样的通常情况下,一个消息被延迟仅当它为乱序时。
本文的结构如下。第2节讨论被ISIS支持的进程组类型和在当前的ISIS应用程序中观察到的组使用和通讯的范型。第3节调查多播工作。第4节形式化虚拟同步多播问题和CBCAST和ABCAST协议必须满足的属性。第5节介绍在单进程组中我们的新技术;多播组在第6节。第7节考虑一些ISIS特别地实现问题。第8节中有一个我们初始化实现的性能讨论
ISIS用户经验
我们开始审查在现存的ISIS应用程序中的组类型和组使用范型
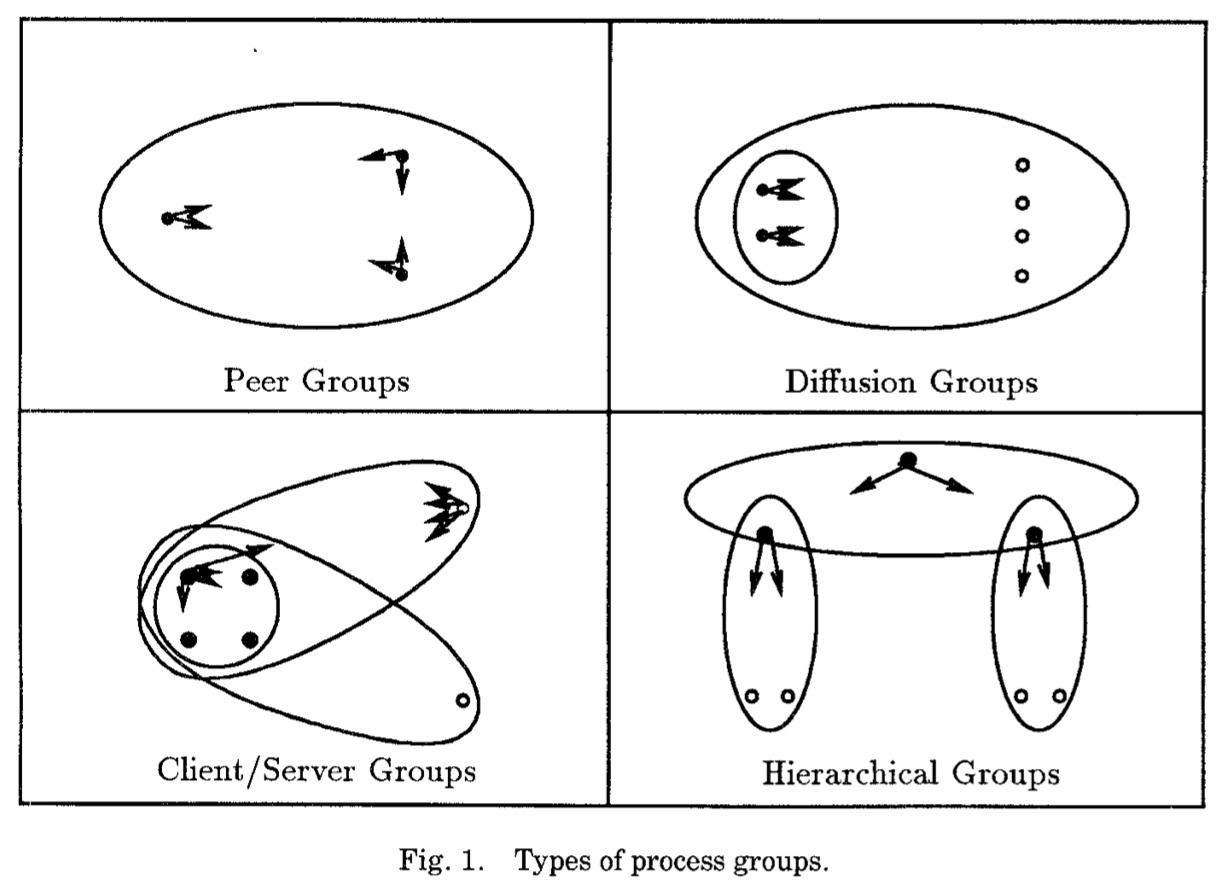
ISIS支持四种组类型,如上图所示。最简单的记为配对组。在配对组中,进程合作作为对等的顺序使任务完成。它们可管理复制数据,子分割任务,监控另一个的状态或结合为一个紧密的协作分布行为。另一个常见的结构为客服端/服务器组。进程配对组作为服务器服务大量客户端。客户端与服务器以请求/回复风格交互,要么通过一个喜欢的服务器且通过向它发起RPC调用,或通过多播到整个服务器组。在后一种情况,服务器将通常多播它们的回复给对应的客户端和另一个服务器。一个扩展组是一类客户端-服务器组,服务器多播消息到服务器全集和客户端。客户端是被动的,只是简单地接收消息。扩散组出现在任意广播信息到大量站点的应用程序中,例如在经纪交易大厅。最后,分层组结构出现在分布式系统需要更大的服务器组的时候。分层组为组的树结构集合。一个根组映射初始连接请求到一个适合的分组,且应用程序只交互这个分组。数据在子组间被分区,且虽然一个大组通讯机制是有效的,但很少需要
许多ISIS应用程序使用多个结构,当混杂功能使用时使用覆盖组。例如,一个扩散组用来扩散股票信息被一个客户端/服务器组通过经纪人程序注册它们的股票兴趣信息覆盖。尽管,现存的ISIS应用程序很少使用大量的组。组不频繁改变成员,且一般包含足够成员来容错或负载共享(例如,3-5个进程)。另一方面,一个客户端/服务器或扩展组的客户端数量可能很大
虽然ISIS用户的学习我们已概括这些范型部分是ISIS演化的人为方式。在这里讨论之前的ISIS版本中,组有相当重量的条目。应用程序只能通过确保到一个组的通讯比组成员变动更频繁来获得可接受的性能。未来,我们期望我们的系统继续支持这四种组类型。我们也期望组仍然较小(除了客户端-服务器或扩散组的客户端集合)。然而,当我们如协议描述那样重建ISIS且移动关键模块到操作系统的更底层,组和组通讯期望有更低成本。这些开销似乎为一个决定性因素防止ISIS用户使用一个巨量的组,特别地在进程组自然建模某些应用程序级别数据类型或对象的时候。结果,我们期望对某些应用程序,组将远超进程数。更进一步,组将变成更加动态,因为加入或离开一个组的开销可极大减少使用本文发展的协议
为说明这些观点,我们考虑某些应用程序有这些特征。一个科学的模拟使用一个n维网格可能使用一个进程组来呈现每个网格元素的邻居。一个网络信息服务运行在数百个站点可能使用小进程组复制个人数据项;结果将为一个大组包含许多小的数据复制域,可能移动数据对应访问范型。相似地,一个进程组可能使用在一个模块化应用程序中导入许多这样的对象来实现复制数据。在每个例子中,进程组的数量可能巨大且在组扩展之间覆盖
想要支持应用程序像这些研究报告中呈现一个主要动机。早期的ISIS协议已证明扩展不灵活且困难;它似乎不能用来支持高动态,大扩展应用程序。这里报告的协议能响应这些需求,支持这些问题开发如同支持并行处理,使用多播通讯硬件和强制实时时间期限和消息优先级
关于组通讯协议之前的工作
我们的通讯协议从Schiper发展的关系消息转发协议演变而来,且基于Fidge和Mattern的工作。在单个进程组的情况下,算法被Ladin和Peterson发展的协议影响。然而,我们的工作在以下方面一般化协议:
- 其他多播协议只在单个进程组的情况下处理因果关系。我们的解决方案能处理多组,覆盖组。我们讨论一个多播协议在异步时必须遵循因果序(不阻塞发送者直到远端转发发生)。异步通讯在组结构分布式应用程序中是高性能的关键且是ISIS的核心特性
- ISIS架构处理客户端/服务器组和扩散组为覆盖组集合,且在这种情况下优化因果序信息的管理。客户端和服务器可直接多播和容错客户端/服务器组的子组。Peterson的协议不执行这些组风格。Ladin协议支持客户端/服务器交互,但不支持扩散组,且不允许客户端直接多播到服务器组
- Ladin协议使用稳定存储作为容错办法的一部分,我们的协议使用一个消息稳定的记号不需要额外存储
我们的CBCAST协议可扩展提供一个总消息转发序,该扩展支持我们主要贡献的多组。然而,我们的ABCAST协议也使用一个转发序跟因果序一致,允许它异步使用。一个转发序可能是总的但不是因果的,且一些协议指出不提供该保证
执行模型
我们现在形式化模型和要解决的问题
-
基本系统模型
系统由不相交内存空间的进程 $ P = \{ p_ {1}, p_ {2}, \ldots, p_ {n} \} $组成。我们假设这个集合是静态的且已知;之后,我们放松该假设。通过崩溃检测到的进程故障(一个故障停止假设);由一个故障检测机制提供一个通知。当多个进程需要协作,例如,管理复制数据,分割一个计算,监控另一个状态等等,它们可被结构化为进程组。这种组的集合被记为 $ G = \{g_ {1}, g_ {2} \cdots \} $
每个进程组有一个名字和一系列进程成员。成员动态地加入和离开;一个故障使一个进程离开其所属的所有组。进程组成员不需要唯一,也不需要对进程所属组数量有任何限制。以下呈现的协议都假设进程只多播到它所属的组,且所有多播直接到单组的所有成员
我们的系统模型通常假设一个额外的服务实现进程组抽象。这精确反映我们当前的实现,从一个现存的ISIS进程组服务器上获得组成员管理。事实上,然而,这个需求可去掉
进程加入和离开进程组的接口不在这里考虑,但组服务通讯成员信息到一个进程跟这个相关。一个进程组的视图是它的成员列表。g的视图序列是一个列表 $ view_ {0}(g), view_ {1}(g), \ldots, view_ {n}(g) $
(1) $ view_ {0}(g) = 0 $
(2) $ \forall i: view_ {i}(g) \subseteq P $,P是系统中所有进程集合,且
(3) $ view_ {i}(g)和 view_ {i+1}(g) $不同仅为一个进程的加入或减少
进程对其他组成员故障的学习只通过这个视图机制
我们假设在进程间直接通讯总是可能的;软件实现这个被成为消息传输层。没有我们的协议,进程总是使用点到点和多播消息通讯;多播可能使用多个点到点消息传输如果没有更有效的替代方式的话。原始的传输通讯必须提供无损、无错、序列化的消息转发。消息传输层总是假设一旦发现一个故障检测则截获和丢失的消息来自该进程。这防止进程可能悬挂一个扩展时间的可能性(例如,等待一个分页存储来响应),但然后尝试重启系统通讯。明显,这种短暂的问题不能和永久故障区分出来,因此很少会选择用相同的方式处理,通过强制故障进程运行一个恢复协议
我们的协议架构允许应用程序构建器定义一个新的传输协议,可能对特殊硬件有优势。本文描述的实现使用我们构建在一个不可靠数据层的传输
进程的执行是一个事件序列的偏序,每个对应一个不可分割行为的执行。一个非循环时间序,记为 $ \stackrel{p}{\to} $,反映发生在进程p在另一个之上的事件依赖。事件 $ send_ {p}(m) $记为dests(m),通过进程p到一个或多个目标的集合的传输;通过进程p消息m的接收记为 $ rev_ {p}(m) $。当进程在上下文是清楚的时候我们省略下标。当 $ | dests(m) | > 1 $我们将假设在当个行为中send推送消息到所有通讯频道可能被故障打断,但不会被其他send或rev行为打断
我们记 $ rev_ {p}(view_ {l}(g)) $事件为一个进程p属于 $ view_ {l}(g) $中的学习
我们区分接收消息事件和转发消息事件,因为这允许我们模型协议延迟消息转发直到某些条件满足。转发事件被记为 $ deliver_ {p}(m) $当 $ rcv_ {p}(m) \stackrel{p}{\to} deliver_ {p}(m) $
当一个进程属于多个组,我们可能需要显示一个消息被发送、接收或转发到哪个组。我们将通过用第二个参数扩展我们的记号;例如, $ deliver_ {p}(m, g) $将显示消息m被转发在进程p,且被组g中其他进程发送
和Lamport一样,我们定义潜在的系统关系$ \to $,作为关系的传输闭集定义如下:
(1) 如果 $ \exists p: e \stackrel{p}{\to} e’, 则 e \to e’ $
(2) $ \forall m: send(m) \to rev(m) $
对消息m和m’,记号 $ m \to m’ $将被使用为 $ send(m) \to send(m’) $的简写
最后,为阐明活跃,我们假设任意消息被一个进程发送最终接收除非发送者或目标故障,且故障被检测且最终反映到一个新的组试图忽略该故障进程
-
虚拟同步属性需要多播协议
早期,我们描述ISIS为一个虚拟同步编程环境。直观上,这意味着用户可编程作为系统调度分布式事件在某个时刻(例如,组成员改变,多播和故障)。当一个系统事实上是这样的行为时,我们称它同步;这样的环境将简化分布式算法的发展但提供很少的可能性来利用并行。ISIS使用的调度,同步只在表面。在ISIS工具箱中工具的顺序需要已被分析,且系统事实上强制在每个案例中同步需要的程度,操作经常并行执行且异步多播,但算法仍能发展且使用一个简单的同步模型
虚拟同步有两个主要的方面:
(1) 地址扩展。它可能使用组为多播的目标。协议必须扩展一个组唯一号到目标列表且转发消息使得
a. 当消息到达时所有接收者有相同的组视角
b. 目的列表包含该视图的成员
这些规则的影响是目标列表的扩展和消息转发看似为单个瞬时事件
(2)原子转发和顺序。这包括消息转发容错(所有操作的目标最终接收到一个消息或只有发送者故障,无消息发送)。进一步地,当多个目标接收到相同的消息,他们观察到一致的转发顺序
两种类型的转发顺序很有趣。我们定义关系转发顺序对多播消息m和 $ m^{\prime} $如下:
$ m \to m^{\prime} \Rightarrow \forall p \in dests(m) \cap dests(m^{\prime}): diliver(m) \stackrel{p}{\rightarrow} deliver(m^{\prime}) $
CBCAST只提供关系顺序转发。如果两个CBCAST并发,协议在目标上对它们转发顺序无限制。ABCAST扩展关系顺序为一个总序,通过顺序并发消息m和 $ m^{\prime} $使得
$ \exists m, m^{\prime}, p \in g: deliver_ {p}(m, g) \stackrel{p}{\rightarrow} deliver_ {p}(m^{\prime}, g) \rightarrow \\ \forall q \in g: deliver_ {q}(m, g) \stackrel{q}{\rightarrow} deliver_ {q}(m^{\prime}, g) $
注意ABCAST的这个目标只是顺序化消息发送到相同的组;其他定义也是可能的。我们将在之后章节讨论。因为ABCAST协议顺序并发事件,它比CBCAST成本高,因此需要同步解决方案而CBCAST协议是更高效的异步解决方案
虽然可定义其他的转发顺序,我们在ISIS上的工作建议这不需要。更高层的ISIS工具箱为它们整个用异步CBCAST实现。事实上,Schmuck显示多个算法指定为ABCAST可修改为使用CBCAST而不影响正确性。进一步,他阐述了两种协议对顺序转发类型是完整的。例如,CBCAST可模仿任意顺序属性允许消息转发在通讯的第一轮次上
容错和消息转发顺序不依赖我们的模型。一个进程在观察到发送者故障后将不接收故障发送者的多播;这需要在视图对应故障可被转发到组成员之前在故障时的多播进度可被系统刷新。更进一步,故障不会在一个多播关系序列中离开隔绝。即如果 $ m \to m^{\prime} $且一个进程 $ p_ {l} $已接收到 $ m^{\prime} $,它不需要考虑一个故障可能防止m被转发到任意它的目标(即使m和 $ m^{\prime} $的目标不重叠)。故障原子化不会提供任何保证
-
向量时间
我们转发协议基于一种逻辑时钟称为向量时钟。向量时钟协议维护有效的信息来精确地代表 $ \to $
对一个进程 $ p_ {i} $的向量时间,记为 $ VT(p_ {i}) $,是一个长度为n的向量( $ n = | P | $),已进程号为索引
- 当 $ p_ {i} $开始执行,$ VT(p_ {i}) $初始化为0
- 对在 $ p_ {i} $上的每个事件send(m),$ VT(p_ {i})[i] $增长1
- 每个进程 $ p_ {i} $多播的消息用增加的 $ VT(p_ {i}) $值进行时间戳
-
当进程$ p_ {j} $转发一个从 $ p_ {i} $包含 $ VT(m) $的消息m,$ p_ {j} $修改它的向量时钟如下:
$ \forall k \in 1, \cdots, n: VT(p_ {j})[k] = max(VT(p_ {j})[k], VT(m)[k]) $
即赋给消息m的向量时间戳统计消息的数量,在每个发送者上,先于m
比较向量时间戳的规则如下:
- $ VT_ {1} \le VT_ {2} \quad iff \quad \forall i: VT_ {1}[i] \le VT_ {2}[i] $
- $ VT_ {1} < VT_ {2} \text{ if } VT_ {1} \le VT_ {2} \text{ and } \exists i: VT_ {1}[i] < VT_ {2}[i] $
这可被显示为给定消息m和$ m^{\prime}, m \to m^{\prime} \text{ iff } VT(m) < VT(m^{\prime}) $:向量时间戳精确代表关系
向量时间为Fidge和Mattern以这种形式发表;后者还有一个好的观测。其他研究者也使用向量时间或相似的机制。
CBCAST和ABCAST协议
本章节描述我们新的CBCAST和ABCAST协议。我们初始化考虑一个固定成员关系的进程组的例子。多进程组问题将在下一节说明。本节首先引入关系转发协议,然后扩展它到总序ABCAST协议,并最终考虑视图改变
-
CBCAST协议
假设一个进程P集合只使用广播到系统中全部进程集合来通讯。即,$ \forall m: dests(m) = P $。我们现在开发一个转发协议,每个进程p接收它发送的消息,必要时进行延迟,然后以跟关系顺序一致来转发:
$ m \to m^{\prime} \Rightarrow \forall p: diliver_ {p}(m) \stackrel{p}{\rightarrow} deliver_ {p}(m^{\prime}) $
我们的解决方案是使用向量时间戳转发。基本思想是用时间戳标签每个消息,$ VT(m)[k] $,精确显示进程 $ p_ {k} $中多少个多播先于m。m的接收者将延迟m直到 $ VT(m)[k] $个消息以从 $ p_ {k} $转发。因为 $ \to $是向量时间上精确地非循环表示,转发的结果顺序是关系且deadlock free的
协议:
(1)在发送m之前,进程 $ p_ {\iota} $递增 $ VT(p_ {\iota})[i] $且时间戳m
(2)在收到$ p_ {\iota} $发送的用VT(m)时间戳标签的消息m后,进程 $ p_ {J} \ne p_ {i} $ 延迟转发m直到:
$ \forall k: 1 \cdots n \left\{ \begin{array}{ll} VT(m)[k] = VT(p_ {\jmath})[k] + 1 & \text{if } k = i \\ VT(m)[k] \le VT(p_ {\jmath})[k] & \text{otherwise} \end{array} \right. $
进程$ p_ {J} $不需要延迟从它自身接收到的消息。延迟的消息用队列维持,CBCAST延迟队列。该队列用向量时间存储,通过接到的时间排序并行的消息
(3)当一个消息m被转发,$ VT(p_ {J}) $根据向量时间协议被更新
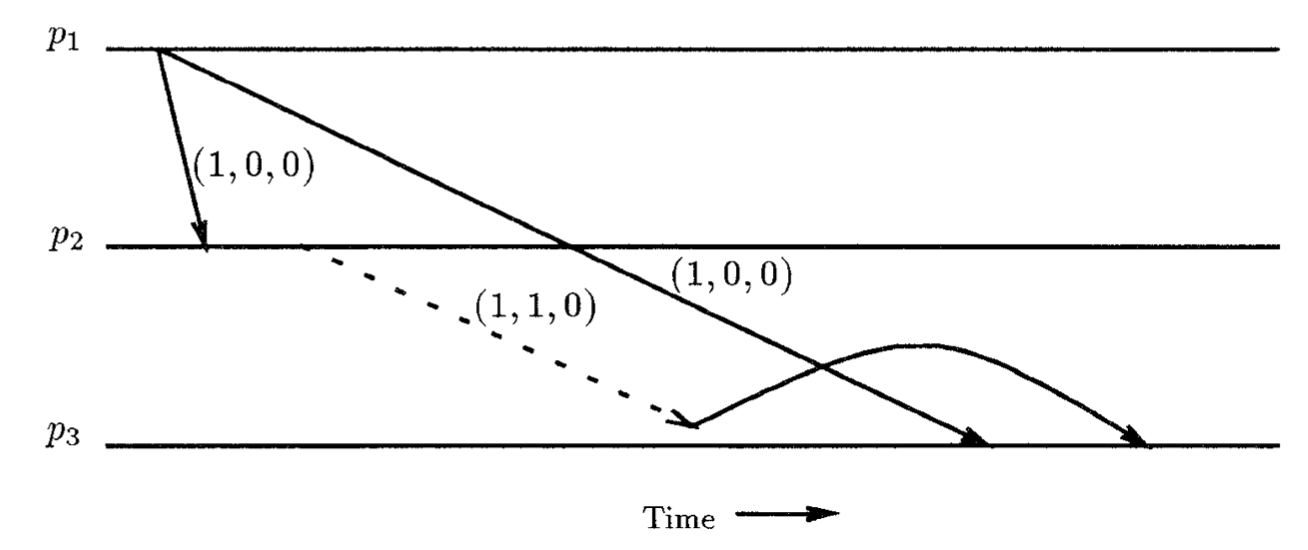
步骤2是协议的关键。这保证任意消息$ m^{\prime} $在m之前关系传输(因此 $ VT(m^{\prime}) < VT(m) $)将被$ p_ {J} $在m之前转发。一个使用这个规则延迟转发消息的例子如上图
我们用两个阶段证明协议的正确性。我们首先显示关系关系不会被违反(安全)且然后我们阐述协议绝不会不清晰地延迟一个消息
安全:考虑一个进程 $ p_ {J} $接收两个消息 $ m_ {1} $和 $ m_ {2} $的行为使得 $ m_ {1} \to m_ {2} $
Case 1: $ m_ {1} $ 和 $ m_ {2} $从相同的进程 $ p_ {i} $传输。回忆我们假设是不会丢失,保活的通讯系统,因此 $ p_ {j} $最终接收到 $ m_ {1} $和 $ m_ {2} $。通过构建,$ VT(m_ {1}) < VT(m_ {2}) $,因此在步骤2,$ m_ {2} $只会在 $ m_ {1} $转发后转发
Case 2: $ m_ {1} $和 $ m_ {2} $为两个不同的进程 $ p_ {i} $和 $ p_ {i^{\prime}} $传输。我们将通过推导显示 $ m_ {2} $不会在 $ m_ {1} $之前被接收。假设 $ m_ {1} $没接收且 $ p_ {j} $已接收了k个消息
首先观察 $ m_ {1} \to m_ {2} $,因此 $ VT(m_ {1}) < VT(m_ {2} $(向量时间的基本属性)。特别地,如果我们考虑进程 $ p_ {i} $对应的域,$ m_ {1} $的发送者,我们有
$ VT(m_ {1})[i] \le VT(m_ {2})[i] $
Base case. $ p_ {j} $转发的第一个消息不能为 $ m_ {2} $。回忆如果没有消息转发到$ p_ {j} $,则 $ VT(p_ {j})[i] = 0 $。然而,$ VT(m_ {1})[i] > 0 $(因为$ m_ {1} $ 由$ p_ {i} $发送,因此 $ TV(m_ {2})[i] > 0 $。通过应用程序的协议步骤2,$ m_ {2} $不能被 $ p_ {j} $转发
推导步骤 假设 $ p_ {j} $接收了k个消息,没有一个消息m使得 $ m_ {1} \to m $。如果 $ m_ {1} $还没被转发,则
$ VT(p_ {j})[i] < VT(m_ {1})[i] $
因为赋值 $ VT(p_ {j})[i] $大于 $ VT(m_ {1})[i] $唯一的方法是从 $ p_ {i} $转发一个在 $ m_ {1} $之后的消息,且这样的消息跟 $ m_ {1} $相关。从关系1和2中我们有
$ VT(p_ {j})[i] < VT(m_ {2})[i] $
通过应用程序的协议步骤2,被 $ p_ {j} $转发的第k + 1个消息不能为 $ m_ {2} $
活跃 假设存在一个由进程 $ p_ {i} $发送的广播消息m不能转发到 $ p_ {j} $。步骤2意味着要么:
$ \exists k: 1 \cdots n \left\{ \begin{array}{ll} VT(m)[k] \ne VT(p_ {j})[k] + 1 & \text{for } k = i, \text{ or} \\ VT(m)[k] > VT(p_ {j})[k] & k \ne i \end{array} \right. $
这样m不被 $ p_ {j} $传输。我们考虑这些情况
- $ VT(m)[i] \ne VT(p_ {j})[i] + 1 $;即m不是从 $ p_ {i} $到 $ p_ {j} $转发的下一条消息。注意只有有限数量的消息在m之前。因为所有消息多播到所有进程且频道是无丢失且序列化的,必须有从 $ p_ {i} $到 $ p_ {j} $之前接收的一些消息 $ m^{\prime} $还没被转发,且它是从 $ p_ {i} $发送的下一条消息,例如,$ VT(m^{\prime})[i] = VT(p_ {j})[i] + 1 $。如果 $ m^{\prime} $也被延迟,它必须是在其他情况下
- $ \exists k \ne i: VT(m)[k] > VT(p_ {j})[k] $。设n = VT(m)[k]。则进程 $ p_ {k} $传输的第n条,必须为某个消息 $ m^{\prime} \to m $要么还未被 $ p_ {j} $接收,或被接收但被延迟。在所有消息被发送到所有进程的假设下,$ m^{\prime} $已多播到 $ p_ {j} $。因为通讯系统最终转发所有消息,我们可假设$ m^{\prime} $已被 $ p_ {j} $接收。相同的原因被应用到m现在可用于 $ m^{\prime} $。在m转发之前的消息数是有限的且非循环的,因此这导致一个矛盾
-
关系ABCAST协议
CBCAST协议已经扩展为一个关系、总序的ABCAST协议。我们应该注意它对一个ABCAST协议是不寻常的,它确保总序用于确认关系。例如,一个进程p使用ABCAST异步传输消息m,然后使用CBCAST发送消息$ m^{\prime} $,一些$ m^{\prime} $的接收者现在使用ABCAST发送 $ m^{\prime \prime} $。这里我们有 $ m \to m^{\prime} \to m^{\prime \prime} $,但m和 $ m^{\prime \prime} $为不同的进程传输。许多ABCAST协议在这种情况下使用一个随机序,我们的解决方案将总是在 $ m^{\prime \prime} $之前转发m。这个属性事实上非常重要:没有它,很少有算法能安全地异步使用ABCAST,且阻塞引入的延迟直到协议提交它的转发序
我们的解决方案基于Birman和Joseph描述的ISIS重复数据更新协议和Birman、Joseph和Schmuck发展的ABCAST协议。关联每个视图 $ view_ {i}(g) $的一个进程组g将为一个token持有进程,$ token(g) \in viwe_ {i}(g) $。我们也假设每个消息m被uid(m)唯一确认
正常情况下对ABCAST m,一个进程使用CBCAST持有token来传输m。如果发送者不持有token,ABCAST分阶段处理:
- 发送者CBCAST的m但标记为不能转发。非token持有者的进程(包括发送者)接收到这个信息通常把m放入CBCAST延迟队列中,但不从转发队列中删除m即使在所有在它之前的消息都被转发。它跟随一个典型的进程可能有一些数目的延迟ABCAST消息在它的CBCAST延迟队列之前。这阻止关系子序列CBCAST消息的转发,因为直到转发发送向量时间不会更新。另一方面,一个CBCAST在那些不可转发ABCAST消息之前或并行的消息不会延迟
- token持有者处理进来的ABCAST消息作为它处理进来的CBCAST消息一样,以正常情况转发它们。然而,它也记录每个这样的ABCAST的uid
- 在token持有者进程已经转发一个或多个ABCAST消息之后,它使用CBCAST来发送一个集合顺序消息给出一个或多个消息的列表,用uid唯一标识,且顺序为步骤2中的转发顺序。如果需要,该CBCAST可被转发这样批量这样的传输,但它必须被发送在token持有者任意ABCAST或CBCAST子序列之前。如果需要,一个新的token持有者可被这个消息说明
-
在接收一个集合顺序消息时,一个进程正常情况下把它放入CBCAST延迟队列。最终,所有在集合顺序消息中的ABCAST消息将被接收,且所有在集合顺序之前的CBCAST消息将被转发
回忆 $ \to $放置延迟队列中消息的一个偏序。我们的协议现在通过给定的集合顺序消息重顺序化放置的并行ABCAST消息,且标签它们为转发
- 可转发ABCAST消息可从队列头转发
步骤4是协议中的关键。该步骤使所有参与者以token持有者使用的顺序转发ABCAST消息。该顺序将以关系一致性因为token持有者本身处理这些ABCAST消息如同它们是CBCAST
一个ABCAST的成本依赖于多播位置和token移动的频率。如果多播趋于重复导向相同的进程,则一旦token被移动到该站点,成本是每个ABCAST一个CBCAST。如果它们导向随机且token不移动,成本是1 + 1 / k 每ABCAST每CBCAST,我们假设一个集合顺序消息在k个ABCAT之后顺序目的被发送
-
多播稳定性
一个多播可以达到所有它的目的地,这一点非常有用。我们将说一个多播m是k稳定的如果它知道多播已被k个目的地接收。当 $ k = | dests(m) | $时我们说m是全稳定的
回忆我们的模型假设一个可靠的传输层。因为信息在传输时因各种原因(缓冲区溢出、通讯链路的噪声,等)导致丢失,这样一个层正常使用一些正面或负面的知识方案来确认转发。我们的活跃假设是强足够,意味着任意多播m将最终变得稳定,如果发送者不故障。它可推理假设这个信息是有效的对进程发送一个CBCAST消息来说
为在群成员间广播稳定性信息,我们将引入如下习性。每个进程 $ p_ {i} $维护一个稳定序列号,$ stable(p_ {i}) $。该号将为最大的整数n使得所有被进程 $ p_ {i} $发送的所有多播有 $ VT(p_ {i})[i] \le n $是稳定的
当发送一个多播消息m,进程 $ p_ {i} $维护它的 $ stable(p_ {i}) $当前值;接收者记录这些收到的值。如果 $ stable(p_ {i}) $改变且 $ p_ {i} $没有输出消息,则当需要,$ p_ {i} $可发送一个稳定消息只包含 $ stable(p_ {i}) $
-
VT压缩
不需要在每个消息上传输完全的向量时间戳
引理1 进程 $ p_ {i} $发送一个多播m。则$ VT(m) $只需要携带自从上个 $ p_ {i} $发送的多播的改变的向量域
证明 考虑两个多播m和 $ m^{\prime} $使得 $ m \ to m^{\prime} $。如果 $ p_ {i} $是m的发送者且 $ p_ {j} $是 $ m^{\prime} $的发送者,则有两种情况。如果 i = j 则 $ VT(m)[i] < VT(m^{\prime})[i] $,因此 $ m^{\prime} $直到m被转发前都不能转发。现在,如果 $ i \ne j $但 $ m^{\prime} $携带 $ p_ {i} $的域,则 $ VT(m)[i] \le VT(m^{\prime})[i] $,且 $ m^{\prime} $将在步骤2被延迟直到m被转发。但,如果该域被忽略,则必须有某个更早的消息 $ m^{\prime \prime} $,被 $ p_ {j} $广播,携带该域。则m将在 $ m^{\prime \prime} $之前被转发,在第一种情况下, $ m^{\prime \prime} $将在 $ m^{\prime} $之前转发
压缩不总是好的,数据需要引入哪个域被传输可事实上增加VT表示的大小。然而,在应用程序中被相对本地特征,爆发的通讯,压缩可缩减时间戳的大小。事实上,如果一个进程发送一系列消息,且在发送期间不接收消息,则在所有消息上的VT时间戳只有第一个包含一个域。更进一步,在这种情况下,域的值可对应频道的FIFO属性,这样的消息不需要保护任何时间戳。我们将更近一步利用这个想法
转发原子性和组成员改变
我们现在考虑原子实现和组成员变化如何影响以上协议。这样的事件会引起一些问题:
- 虚拟同步地址
- 重初始化VT时间戳
- 当故障发生时转发原子性
- 当没有发送一个集顺序消息token持有失败时处理延迟ABCAST消息
虚拟同步地址 为达到当组成员改变而多播以激活时同步地址,我们在进程组中引入刷新通讯的记号。初始化,我们将假设进程不会故障或离开组(我们将在下一节处理这些情况)。考虑 $ view_ {i} $中的一个进程组。说 $ view_ {i+1} $现在变成已定义。我们可通过在 $ view_ {i+1} $中所有进程发送一个消息“刷新 i+1“,给这个view中所有其他进程来刷新通讯。在发这样的消息和从 $ view_ {i+1} $所有成员中接收到这样的刷新消息之前,一个进程将接收并转发消息但不初始化新的多播。因为通讯是FIFO的,如果进程p在 $ View_ {i+1} $中从所有进程接收到一个刷新消息,它将首先接收 $ view_ {i} $成员发送的所有消息。因故障缺失,这样确定了多播将虚拟同步
这个刷新协议的一个缺点是它发送 $ n^{2} $个消息。幸运地是,解决方案通过使用一个消息的线性号能修改为一个。我们依然推迟处理故障问题,说我们指定 $ view_ {i+1} $中的一个成员 $ p_ {c} $,作为刷新协调器。任意确定性规则可被用于这个目的。一个不同于协调器的进程 $ p_ {i} $首先等待直到所有它发送的多播已经稳定后才被刷新,然后发送一个 $ view_ {i+1} $的刷新消息给协调器。协调器,$ p_ {c} $,等待直到刷新消息被 $ view_ {i+1} $的其他所有成员接收。它然后多播它自己的刷新消息给 $ view_ {i+1} $的成员(它不需要等待它自己的多播稳定)。从 $ p_ {c} $接收到的刷新消息提供和原始解决方案相同的保障。如果稳定性快速达成,新协议的成本非常低:2n个消息
重初始化VT域 在执行刷新协议后,所有进程可重置VT域为0。这非常有用。我们现在讲假设消息中的向量时间戳,VT(m),包含 $ view_ {i} $的索引i。一个向量时间戳携带一个过期的索引将被忽略,因为刷新协议使用切换视图将强制转发在之前的视图中悬置的所有多播
当故障发生时原子转发和虚拟同步 我们现在考虑在执行时一些进程故障的情况。我们会在 本子节最后讨论这个问题引起当进程自愿离开组的情况
故障引起两个基本问题:
- 一个故障可能干扰一个多播的传输。然后,如果$ p_ {j} $从进程 $ p_ {i} $接收到一个多播消息m,且还没有学习到多播稳定性,一些其他m的目的地可能还没有收到拷贝
- 我们可不再假设所有进程将认可刷新协议,因为一个进程 $ p_ {i} $的故障将阻碍它发送刷新消息到一些视图中,甚至视图报告 $ p_ {i} $依然在操作中。另一方面,我们也知道一个视图显示 $ p_ {i} $故障,将最终接收到
为解决第一个问题,我们让所有进程保留它们接收到的消息拷贝。如果 $ p_ {j} $检测到 $ p_ {i} $故障,它将转发从 $ p_ {i} $接收到的任意未稳定多播到组的其他成员。所有进程确定且拒绝重复。然而,第二个问题可能现在会阻碍协议被认可,使第一个问题无法解决,如下图所示。这显示两个问题是紧密相关的
原子和虚拟同步问题的解决方案最可靠的理解为原始的 $ n^{2} $消息刷新协议。如果我们运行该协议,它导致延迟 $ view_ {i+1} $的安装,直到对某个 $ k \ge 1 $,$ view_ {i+k} $的刷新消息从所有 $ view_ {i+k} \cap view_ {i + 1} $的进程中接收到。注意一个进程可能运行在 $ view_ {i+k} $的刷新协议下尽管还没有安装 $ view_ {i+1} $
更形式化的,一个进程p执行地算法如下:
- 在接收到 $ view_ {i+k} $,p增加一个本地变量inhibit_sends;然而计数器依然大于0,新的消息将不被初始化。p转发从 $ view_ {j}(j < i + k) $到 $ view_ {j} \cap view_ {i+k} $中的所有进程的任意未稳定消息m的一个拷贝,然后标签m为稳定。最后,p发送“刷新 i + k“给 $ view _{i+k} $的每个成员
- 当接收到消息m的一个拷贝,p检查发送m的视图的索引。如果p最近安装了 $ view_ {i} $,且m被发送的 $ view(m) < i $,p忽略m认为它是一个重复。如果m是在 $ view_ {i} $中被发送,p应用正常的转发规则,以明显的方法确定且丢弃重复。如果m被 $ view(m) > i $的发送,p保存m直到view(m)已经被安装
-
当接收到 $ view_ {i+1} \cap view_ {i+k} (\forall k \ge 1) $的所有进程的“刷新 i + k “消息后,p安装$ view_ {i+1} $,转发它到应用层。它减少inhibit_sends计算器,如果计算器现在为0,则允许新的消息被初始化
$ view_ {i} $中发送的任意消息m和还没有被转发的可能会被丢弃。这可能只发生在当m的发送者故障,且之前接收到并转发的消息 $ m^{\prime} (m^{\prime} \to m) $被丢弃。在这样的情况下,m是系统执行中的一个孤儿被多个故障擦除
- 一个消息在被本地转发且变得稳定后会被丢弃。注意一个消息在被转发多于一次后变得稳定
- 一个进程p在 $ view_ {i} $中发送一个消息m,如果转发确认被从 $ view_ {i} \cap view_ {i+k}, (\forall k) $的所有进程获得则m为稳定的,或者如果 $ view_ {i+1} $被安装
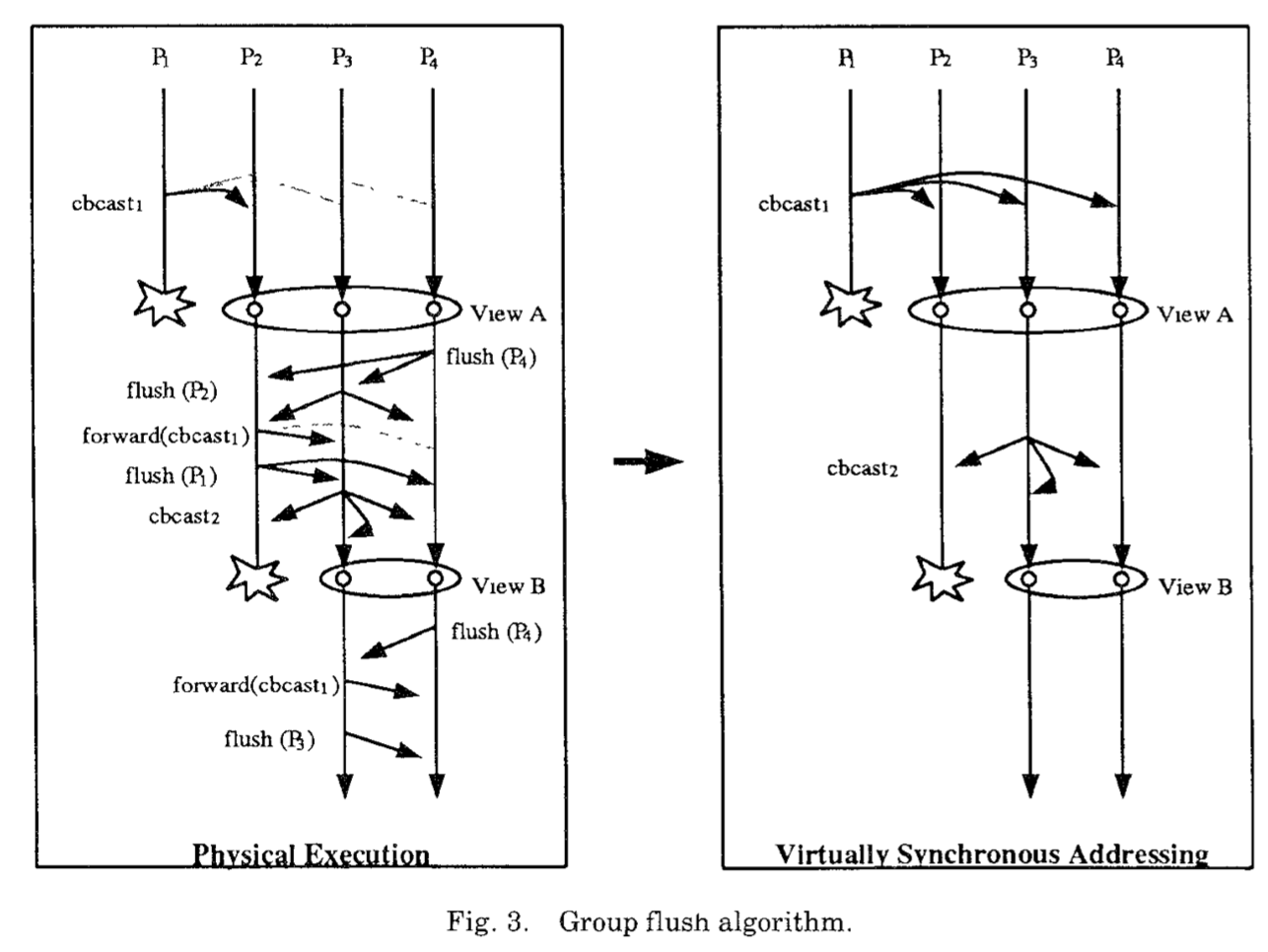
引理2 刷新算法是安全且活跃的
证明 协议的一个参与者p,延迟安装 $ view_ {i+1} $直到它接收到在 $ view_ {i+k} $中仍然在操作的所有 $ view_ {i+1} $成员在 $ view_ {i+k}, \quad (k \ge 1) $中发送的刷新消息。这些只处理在 $ view_ {i} $中发送的可能有的一个不稳定消息的拷贝。这是因为故障进程的消息被丢弃,且因为消息只转发到原始发送的view中还活跃的进程。因为参与者在发送刷新前转发不稳定消息,且频道是FIFO的,p将在安装 $ view_ {i+1} $前接收到 $ view_ {i} $发送的所有消息。它使得协议是安全的。因为协议只在 $ view_ {i+1} $成员故障时延迟安装 $ view_ {i+1} $,所以是活跃的。因为 $ view_ {i+1} $有有限个成员,任意的延迟都是有限的
该协议可被修改为在每个view中发送一个线性数量的消息,使用之前提议的基于相同协调者的方案。与其发送”flush i + k”消息给 $ view_ {i+1} \cap view_ {i+k} $中的所有进程,一个进程可转发不稳定消息的拷贝到协调者,跟随一个”flush i + k”消息。(一个被进程p在 $ view_ {i} $发送的消息m,在变成稳定之前故障,被认为是对 $ q \in view_ {i} $中存活进程的一个不稳定消息,直到q安装 $ view_ {i+1} $)。协调者转发这些消息到view的其他进程,然后接收在 $ view_ {i+k} $中所有成员多播它自己的刷新消息。$ view_ {i+k} $在从接收到协调者发送的刷新消息后被安装
我们现在考虑在执行如上协议时发送故障的情况。协调者应该中止它的协议如果它等待一些进程p的刷新消息,且 $ view_ {i + k + \ell} $变得已定义,显示p已经故障。在这种情况下,$ view_ {i+k+\ell} $ 协议将包含 $ view_ {i+k} $。相似地,如果协调者故障,一个其他协调者的将来的刷新运行将包含该中断的协议。一个成功地完成刷新允许安装所有之前的view
对活跃,它现在变成需要避免无限地延迟view的安装在扩展进程加入/故障序列事件中。我们因此修改协议使参与者通知它们当前view的协调者。一个协调者收集 $ view_ {i+k} $的刷新消息,该消息从 $ view_ {i+1} \cap veiw_ {i+k} $中所有进程可发送一个 $ view_ {i+1} $刷新消息给任意还在 $ view_ {i} $中的进程,甚至它还没有收到所有需要的刷新消息来终止 $ view_ {i+k} $协议。对这种改变,协议是活跃的
如之前图中所示,协议转换一个非原子多播的执行为一个线性成本的所有原子转发的多播
协议需要一个小的改变当一个进程以非故障原因离开一个组。ISIS支持这个可能性,且它触发一个跟故障相似地视图改变,但离开进程被报道作为有弱点地离开。在这种情况下,刷新算法必须包含离开进程,其被作为组成员对待直到它要么故障要么算法终止。这确保即使离开的成员是唯一的进程收到一些被故障中断的多播,转发原子性依然保留
当token持有者故障时ABCAST顺序 原子机制需要ABCAST协议有一个小的修改。考虑一个ABCAST在视图中被发送,且在发送集合顺序消息前token持有者故障
在完成 $ view_ {i} $的刷新协议之后,ABCAST消息将在每个延迟队列中,但不转发。更进一步,任何在故障之前被初始化的集合顺序消息将被转发到所有,因此未转发的ABCAST消息集合在所有进程中相同。这些消息必须在 $ view_ {i+1} $被安装前转发
注意延迟队列是部分有序 $ \to $。我们可通过任意并行的ABCAST消息,其使用任意集合上著名的、确定性的规则解决我们的问题。例如,它们可通过uid排序。ABCAST消息总序结果在所有进程中相同且有一致性
基本协议的扩展
上节中的协议都不能用于多进程组的情况。我们首先引入修改,需要扩展CBCAST到多组设置中。我们然后简短地检查这种设置下ABCAST的问题
CBCAST解决方案在非常大数量进程组或动态改变的组的系统中初始化会比较耗资源。这在当前的ISIS系统中不是个问题因为当前的应用程序使用比较性的进程组,且进程趋于在相同的组中扩展多播区间。然而,这些特征将在之后的ISIS应用程序中没有必要。章节的下半部分将探索协议额外的扩展允许在非常大数量动态进程组中使用设置。结果的协议是有趣的因为它利用我们称之为系统通信结构的属性
扩展CBCAST到多组
协议的第一个扩展考虑系统组成多播进程组。我们将继续假设一个给定的多播发送到单个组目标,但它可能现在为一种情况即一个进程属于多个组且在这些组中能自由的多播
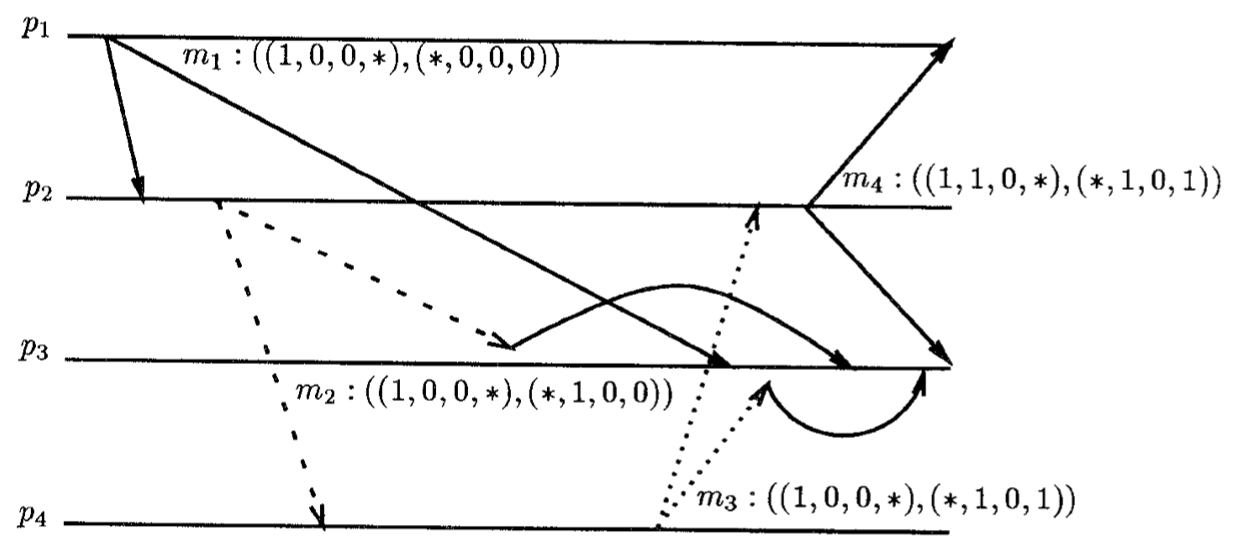
假设进程 $ p_ {\ell} $属于组 $ g_ {a} $ 和 $ g_ {b} $,且在两个组里多播。从 $ p_ {\ell} $发送到 $ g_ {a} $的多播必须和到 $ g_ {b} $的进行区分。否则,一个进程属于 $ g_ {b} $而不属于 $ g_ {a} $接收到一个消息 $ VT(m)[i] = k $将没法区分发送到 $ g_ {b} $的k消息有多少,因此跟m相关
这使得我们扩展单个VT时钟为多VT时钟。我们将使用记号 $ VT_ {a} $来标记跟组 $ g_ {a} $相关的逻辑时钟;$ VT_ {a}[i] $统计 $ p_ {\ell} $到组 $ g_ {a} $的多播。稳定序号,$ stable(p_ {\ell}) $将跟 $ stable_ {a}(p_ {\ell}) $相似。在系统中进程维护每个组的VT时钟,且把所有VT时钟放入它们多播的每个消息
另一个改变是协议的步骤2。假设进程 $ p_ {j} $接收到 $ p_ {\ell} $发送的属于组 $ g_ {a} $的消息m,且 $ p_ {j} $也属于组 $ \{ g_ {1}, \ldots, g_ {n} \} \equiv G_ {j} $,步骤2可被如下规则替换:
接收到 $ g_ {a} $中 $ p_ {\ell} \neq p_ {j} $的消息m,进程 $ p_ {j} $延迟m直到
- $ VT_ {a}(m)[i] = VT_ {a}(p_ {j})[i] + 1 $,且
- $ \forall k: (p_ {k} \in g_ {a} \land k \neq i): VT_ {a}(m)[k] \le VT(p_ {j})[k] $,且
- $ \forall g: (g \in G_ {j}): VT_ {g}(m) \le VT_ {g}(p_ {j}) $
这是原始协议修改为迭代进程所属的组集合。在原始的协议中,$ p_ {j} $不延迟从它自身接收到的消息
上图阐释了4个进程 $ p_ {1}, \ldots, p_ {4} $的例子遵从该协议的应用程序。进程 $ p_ {1}, p_ {2} $和$ p_ {3} $属于组 $ G_ {1} $,且进程 $ p_ {2}, p_ {3} $和 $ p_ {4} $属于组 $ G_ {2} $。注意 $ m_ {2} $和 $ m_ {3} $在 $ p_ {3} $中延迟,因为它是 $ G_ {1} $的成员,且必须先接收 $ m_ {1} $。然而, $ m_ {2} $在 $ p_ {4} $上不延迟,因为 $ p_ {4} $不是 $ G_ {1} $的成员。且 $ m_ {3} $在 $ p_ {2} $上不延迟,因为 $ p_ {2} $已接收到 $ m_ {1} $且它是 $ m_ {2} $的发送者
章节5的证明适配这个新的形式没有什么困难;我们忽略最近确定的争论。我们可直观地理解这个修改的协议。通过忽略步骤 $ 2.3^{\prime} $给某个组的向量时间戳,我们断言不需要考虑从这些组任何未转发的消息可能导致在m之前。但,该忽略的条目对应 $ p_ {j} $不属于的组。因为所有的通信在组间完成,这些条目跟 $ p_ {j} $不相关
多组ABCAST
当运行在这个扩展CBCAST协议中,我们的ABCAST解决方案将继续提高对任意单一进程组的一个总的,关系转发顺序。然而,它不会顺序多播到不同的组即使这些组有相同的组员。在之前的文章中我们检查对全局ABCAST顺序属性的需要和建议它可能有很少地实际重要性,因为单组协议满足我们已知的所有现存的ISIS应用程序的需求。我们扩展我们的ABCAST解决方案为一个提高一个全局总序结果协议的方案,在任意单一组g中,有一个比例给其他组的数量覆盖g。细节在Stephenson的文章中。这个扩展,全局顺序ABCAST协议可被实现如果需要
扩展VT压缩
在之前的章节中我们引入一个规则在传输之前压缩一个向量时间戳。我们可问这样的技术工具在单一进程组中,特别是如果该组很小时。在多组设置中,相同的技术可允许一个进程从它相同的多播中删除整个向量时间戳。另外,因为我们的组刷新算法重置组时间戳为0,多组算法将频繁地获得一个组向量时间戳,其没有通信因为最后的刷新,且因此所有是0。明显地,这样的一个时间戳可以删除
更一般地,对组 $ g_ {a} $最新的非零时间戳只需要包含从某个组 $ g_ {b} $发送的任意系列消息的第一个。这是对组中所有接收到的时间戳一个元素一个元素最大值统计获得。进一步和 $ g_ {b} $通信不需要包含该时间戳,因为所有这个通信将跟包含更新值 $ VT_ {\alpha} $相关。更准确地,$ g_ {b} $中任意进程更新 $ VT_ {\alpha} $的值作为不是 $ g_ {b} $进程接收到的消息的结果包含在多播到 $ g_ {b} $的下一个消息中的 $ VT_ {\alpha} $更新值中。更新值不需要包含多播到 $ g_ {b} $消息的任意子序列。这个优化的进一步细节,和正确性证明,可在Stephenson的文章中找到
我们可做得更好。回忆多播稳定性的定义。一个组对进程p是活跃的,如果
(1) p是一个多播到不稳定的g的初始者,或
(2) p已接收到一个到g的不稳定多播
活动是本地属性;例如,p可通过检查本地状态计算是否某个组g对它是活跃的。更进一步,g可能在某一时刻被p激活,p被q非激活(事实上,通过延迟消息转发,一个进程可通过等待直到任意活跃多播稳定来强制一个组变成非活跃)
现在,我们修改扩展协议的步骤 $ 2^{\prime} $如下。一个进程p在组 $ g_ {a} $中接收到一个多播m必须延迟m直到任意多播 $ m^{\prime} $,其跟m并行,且之前在其他组 $ g_ {b} (b \ne a) $被接收已被本地转发。例如,进程p在组 $ g_ {1} $中接收到 $ m_ {1} $,然后在组 $ g_ {2} $中接收到 $ m_ {2} $,然后在组 $ g_ {1} $中接收到 $ m_ {3} $。按照规则,$ m_ {2} $必须在 $ m_ {1} $之后转发。相似地,$ m_ {3} $必须在 $ m_ {2} $之后转发。因为基本协议在任意单个组中是活跃的,没有消息将在这个修改规则中被非定义地转发
然后,当发送消息(在任意组),时间戳对应非激活组在一个消息中被忽略。这里的意图是它可能对一个稳定消息已到达它的目的地,但仍然阻塞在某些转发队列中。我们的改变确保这样的一个消息将在其他组接收到任意子序列消息之前被转发。这种情况下,向量时间戳可被忽略
这是有趣地当问到在典型的ISIS应用程序中如何有效压缩时间戳。特别地,如果压缩戏剧性地减少发送在一个典型消息上的时间戳数量,我们将如预想到达,低负载协议。另一方面,如果压缩不高效,需要方法来进一步缩减传送的向量时间戳数量。不幸地是,我们缺乏有效地经验来回答这个问题。在这个阶段,任何讨论必须必要地猜测
回忆ISIS应用程序相信展示通信本地化。在我们的设置中,本地化意味着一个进程多数最近是在组 $ g_ {\ell} $中接收到一个消息将可能发送和接收在 $ g_ {\ell} $中几次在发送或接收某些其他组之前。如果分布式系统不展示通信本地化则这将是一个惊喜。因为类似的属性包含一些形式的循环。基于进程组的系统也将期望展示本地化有第二个原因:当一个分布式算法在一个组g执行时,通常参与者会忙乱于信息交换。例如,如果一个进程组被用来管理交易的复制数据,一个更新交易可能多播来请求一个锁,为处理每次更新,初始化提交协议。这样序列的多播在ISIS算法中有很多
扩展压缩规则有利本地通讯,因为少量的向量时间戳需要在爆发的活动中传送。多数组很小,因此消息上的时间戳需要被优化的很少。更进一步,在高度本地系统中,一个向量时间戳穿过的每个进程组将短暂地延迟时间戳
例如,假设一个进程在组 $ g_ {\ell} $中发送一个多播,一般地,$ g_ {\ell} $中发送和接收的总n个多播在一些其他组中先发送或接收。在我们的扩展规则中,只有这些多播的第一个将携带其他组的向量时间戳。子序列多播使用之前章节的方法可被减少。更近一步,如果组 $ g_ {\ell} $的向量时间戳每秒改变k次,邻接组 $ g_ {2} $的成员(不一定是 $ g_ {1} $的成员)将看到一个 $ k / n $的改变速度。一个距离为d的组将看到每个 $ n^{d} $个的值,给定每秒 $ k / n^{d} $的速度。这样,压缩组合和本地通讯可显著地缩减消息上的时间戳。事实上,如果多数消息爆发式地发送,平均多播可能不携带任何时间戳
向量时间戳的垃圾收集
我们的方案是累积旧的时间戳可发生在不属于组的进程中。例如,进程p,不是组g的成员,接收到一个消息依赖组g的某些事件。然后p将获得VT(g)的一个拷贝,且将只在组中每个进程有它之后才传送。 这将引入相当的成本当一个进程加入一个组的时候,因为它将需要传送它组中第一个多播大量的时间戳,且组成员将相互需要发送它持有的任意向量时间戳
事实上,有一些方法使得旧时间戳可以被垃圾回收。一个特别简单的解决方案是定期刷新任意活跃组(至少每n秒一次)。然后如果一个接收到的时间戳时间已知,时间戳可在n秒后丢弃
原子性和组成员改变
协议的组刷新和多播原子性需要在这个多播组扩展中重新考虑
虚拟同步地址 回忆虚拟同步地址使用一个组刷新协议实现。在无故障的情况下,之前的协议继续支持这个属性
Tips
- 感觉要看的东西太多,需要根据自己的规划、喜好、节奏做些取舍
Share
WebRTC Today & Tomorrow: Interview with W3C WebRTC Chair Bernard Aboba
https://webrtchacks.com/webrtc-today-tomorrow-bernard-aboba-qa/
每年我会在IIT-RTC会议上遇到许多WebRTC标准的人员。今年的传染病使得今年明显不同往年。Bernard Aboba代表Edge在这年的WebRTC浏览器更新轮桌上在Kranky Geek(他在这里经常是Edge WebRTC的代言人)。Bernard也是W3C的WEBRTC Working Group的联合主席。当我们在这年的Kranky Geek会议上接触标准化工作和“WebRTC未来“,我们没有时间深入很多细节所以我们将在这里说明
Bernard有一个长且不同的实时通讯职业。还有他的W3C WebRTC联合主席角色,他也是WEBTRANS和AVTCORE工作组的联合主席和ORTC, WebRTC-SVC, WebRTC-NV Use Cases, WebRTC-ICE, WebTransport和WebRTC-QUIC文档的作者。不要忘记WebRTC也是IETF部分标准,Bernard也是WEBTRANS and AVTCORE WGs的联合主席。在微软他是微软组媒体组织称为IC3的组的架构师,该小组职责是支持微软组和其他项目基于Teams架构比如Azure通讯服务
WebRTC Standardization Status
作为W3C’s WebRTC Working Group主席之一,Bernard是WebRTC标准化进程中的权威人物。我开始问他Working Group当前的角色
Bernard: 在April 2020 presentation to W3C讨论的那样,WebRTC Working Group官方描述工作在3个方面:
- 完成WebRTC Peer Connection (WebRTC-PC),这是第一优先级,及相关的指导说明比如WebRTC状态
- 捕获,流和输出相关说明,包括媒体捕获和流,屏幕捕获,从DOM Elements中媒体捕获,媒体流图像捕获,媒体流记录,音频输出设备和内容提示
- WebRTC-NV,下一版WebRTC
WebRTC-NV是WebRTC的下一版,它将在当前1.0指导说明中出现
Bernard: WebRTC-NV工作主要在4个分类
- 一个分类是扩展WebRTC PeerConnection。这包括WebRTC扩展,WebRTC-SVC和可插入流。我将提及WebRTC提议推荐和所有依赖RTCPeerConnection的工作需要“统一计划”,这是现在所有浏览器中默认的SDP方言。这样,例如在你的应用程序中,如果不支持“统一计划”它不可能利用可插入流来支持端到端加密
- 第二个分类包括在WebRTC-PC提议推荐中没有实现或成熟需求的特性,包括WebRTC唯一标识,WebRTC优先级控制和WebRTC DSCP
- 第三个分类是捕获扩展,比如MediaStreamTrack可插入流,媒体捕获和流扩展和媒体捕获深度流扩展(最近复苏)
- 第四个分类是我称之为独立指导说明,其不需要依赖RTCPeerConnection或存在的媒体捕获指导说明。WebRTC-ICE(已被实现为独立指导说明)在这个分类中,及在W3C WEBRTC外部发展的API指导说明比如WebTransport(在W3C WebTransport WG),WebRTC-QUIC(在ORTC CG)和WebCodecs(在WICG)
给定不同的工作分类,”NV”这个术语有些模糊且可能使人困惑。该术语源之于ORTC,但今天它一般为多个说明,而不是单个文档。在当前的使用中,有一些歧义,因为”NV”可能指定为RTCPeerConnection扩展和现存的捕获APIs,或跟RTCPeerConnection或现存的捕获APIs不相关的API,比如WebTransport和WebCodecs,这样当有人提及”WebRTC-NV”时,它通常需要问一些问题来理解它们到底是哪个意思
The path to being a full Recommendation
WebRTC使用的协议被定义在IETF,W3C定义浏览器中使用的API。W3C的正式标准化之路 - 和争论应该包括那些东西 - 一度成为争议的话题
Bernard给出这些方面的一些背景和状态
Chad: 你能给我们的听众介绍W3C指导说明的阶段状况吗?
Bernard: 第一个标准化阶段是CR - 替代者推荐。替代者推荐意味着指导说明已被广泛审查,已经达到WG要求且可实现。在CR时,指导说明可能还没有完全实现(有特征风险)且可能被浏览器内部处理
你可看到整个进程细节描述在 https://www.w3.org/2020/Process-20200915/
Chad: 当你说最后的CR,我猜测有多个CR或CR进程是多阶段的?
Bernard: 有一个新的W3C进程有实时的指导说明。让我们说我们在最后一个之前我们将文档化一个提议的推荐
这样PR[提议推荐]即是你可以尝试实验指导说明已实现的每一个条目。下一个步骤是PR且我们收集你们需要的大量的数据。比如Peer Connection,它有大量的数据因为你需要所有你的内部操作测试,包括你的WPT测试结果,也包括潜在的你的KITE测试结果

WPT指web-platform-tests,是W3C上一系列测试检查API实现,该结果放在https://wpt.fyi
KITE是一个开源,内部操作测试项目指定给WebRTC。Alex博士讨论了相关内容在他的webrtcHacks博客上 - https://webrtchacks.com/sfu-load-testing/
Chad: WPT即wpt.fyi,是一般化类型自动特性测试,而KITE是WebRTC特定内部操作测试
Barnard: WebRTC WPT测试运行在单个浏览器上,WebRTC WPT上我们没有服务器测试,但有一些像WebTransport这样的服务器测试。这样WebRTC WPT测试不需要在浏览器间或浏览器与议会服务器间demo化操作,而KITE测试是在浏览器和潜在的多个条目中测试
Chad: 这就是WebRTC指导说明 - 你们事实上发送媒介给不同的浏览器
Bernard: 为理解WPT测试覆盖水平,我们有指导说明的注释。除了测试结果,你也想要知道指导说明被测试事实上覆盖了多少
流行病使标准影响缓慢
WebRTC有一些有趣的影响。它使我们所有人在WebRTC社区非常忙碌,更多聚焦于所有新流量的扩展和可靠性。然而,聚焦的改变极大地影响了现在的进程。这也影响到标准进程了吗?
Bernard: 底线是我们尝试收集所有证据我们将要呈现在W3C上声明我们准备好了提议推荐阶段。这是非常大的一步,但进度被病毒影响放慢。我的意思,我们认为我们将获得进一步的实现进程,但病毒让所有人放慢
Chad: 因为人们忙于支持他们的产品或因为事实上你们不能频繁聚集在一起?
Bernard: 流行病打乱了很多事,例如,KITE内部操作测试通常由IETF的人来完成但我们还没有IETF的人。我们已尝试去搞清楚我们如何使测试完成,但由于没法把人聚集在一处统计很困难。如果人员分散在全世界各地想要在同一时间同一地点组织所有人是困难的。
病毒不仅打乱了测试,也影响了实现计划。当几乎所有提议推荐的特性已实现在至少一个浏览器时,我们原本相信我们将在2020年秋的code base上有更多的特性实现在多个浏览器上。这样实现进度和测试都不在我们的预期中
标准化工作有多重要?
WebRTC已在非常多浏览器实现,在过去几年有一个更新。WebRTC支持了VoIP流量的重要部分。标准化工作的下一个阶段还很重要吗?
Bernard指出标准化不仅仅是写指导说明 - 它实际上是内部操作能力
Bernard: 标准化工作聚焦在测试和稳定性上。WebRTC Peer Connection最大的挑战之一是它的宽度太广。我们了解到仅从每天从bug中分离出的严重bug,知道我们的覆盖不是我们真实想要的。我们也了解到它有多困难达到可接受的测试覆盖。这里有很多最近的bug比如多路,其事实上已有主要的影响在现存的服务且我们还没有测试。我们从这些bug中看到这些不是WPT发现的。这些需要有类似KITE的框架来做且我们还没有在KITE中接近百分比测试覆盖
我将说最大的不同之一是我认为在实时通讯 vs 网络其他方面有很大的测试矩阵尺寸。甚至想象如果我告诉你Chad,我想要让你开发,获得95%的覆盖。我想通过这样测试的进程是有帮助的,但它还使我们欣赏让每一件事都覆盖的挑战。非常难
WebRTC扩展
WebRTC事项列表变得越来越长。如Bernard所提及的,WebRTC 1.0进度跟随标准进程所以只需要画一条线来添加新的特性。如Bernard将解释的,WebRTC扩展有一些特性不会进入WebRTC 1.0
Bernard: 有一系列指导说明依赖RTCPeerConnection。WebRTC扩展是其中之一。有一些指导说明添加功能到PC端WebRTC。这里有大量事项例如,RTP头扩展加密。WebRTC SVC - 可扩展视频编码 - 不在WebRTC扩展文档中,但我认为它是一个扩展。我将考虑可插入流为WebRTC PC端的一个扩展,它的编码版本。这些事项假设你有RTCPeerConnection
getCurrentBrowsingContextMedia
随着视频会议的使用增长,有几个频率高的问题即webcam出错和偶尔的屏幕共享。同时,快速webcam访问通常是WebRTC服务的一个问题。平衡访问速度和隐私控制是一个难题。另外,getMediaDevices提供的媒体设备信息使用的指纹成为一个持续的隐私挑战
getCurrentBrowsingContextMedia的提议是一个处理这些挑战的尝试
Chad: 我们能说下getCurrentBrowsingContextMedia媒体提议吗?
Bernard: 这是一个扩展,我认为是一个屏幕捕获的扩展。让我说说捕获的问题 - 聚焦于捕获的很多是隐私和安全问题。我们发现媒体捕获流对隐私不是很好。假设你给应用程序所有设备信息,是否它们被选择或否,则让它创建自己的picker。这对指纹是一个问题因为现在我知道在你的机器上所有的设备。虽然你不想使用摄像头,但我知道有。Jan-ivar已经提议我们移动到另一个模型,其跟屏幕捕获相似
在屏幕捕获中你只获得访问用户选择的摄像头。这样它不像我获得访问你所有的apps且我能看到每个窗口且然后我决定作为一个应用程序购买我想看的。现在用户选择源且你只能获得访问它。这是Jan-ivar提议的媒体捕获和流模型。它会变成浏览器picker的一部分。应用程序只能获得用户选择的设备信息。这是一个大变动。它也将带来一些基本的媒体捕获和流问题。例如,如果用户依然想要选择的话限制的目的是什么?
Chad: 这是否意味着设备picker有更多的指导说明?
Bernard: 我认为是。然而,我们决定根据该模型升级现存的指导说明。然后Jan-ivar创建该新模型的一个独立的说明针对所有这些问题。这是一个非常不同的模型,当人们使用应用程序picker时如何使用这新模型呢?这将花费很长的时间
WebRTC NV
一个激烈争论的标准结论是一个勉强地决定指定一个形式化的版本名称因为每个人有不同的观点在什么组成一个主发布版本(例如,1.0, 2.0) vs 一个小版本(例如,1.1, 1.2等)。曾有一个替代的提议称为ORTC有时指WebRTC的前身。WebRTC 1.0已合并我们讨论的指导说明。然而,还有很多债在下一个版本中。他们最终命名下一个版本为”WebRTC Next Version”或WebRTC-NV
Bernard解释这意味着什么
Chad: 我们讨论一下我们将看到的下一代WebRTC。我猜我们不称其为2.0因为1.0还没有完成?
Bernard: 我想可能是时候想想NV术语因为它代表两个潜在的非常不同的事。一个是如我提及的Peer Connection扩展 - 可插入流,WebRTC扩展,WebRTC SVC。我认为当你把所有指导说明和在一块它将是ORTC的所有功能,所以我们在WebRTC PC上已兼容大多数ORTC对象模型
另一个非常独立的是我所说的单独说明。这包括WebTransport, WebCodecs, WebRTC ICE - 这些是非常独立的,且不依赖RTCPeerConnection,所以它是下一代跟现在的不同
明显地,WebTransport是一个原始的尝试。WebCodecs在Chrome上是一个原始尝试。现在这非常不同因为你使用的许多事情作为WebRTC PC的一部分,你现在不得不在Web Assembly上写。所以它是非常非常不同的开发模型
WebTransport继承客户端-服务器模型。有一个点对点扩展在之前尝试过一段时间,但当前它是客户端服务器模型。这样你不能写完整的WebRTC PC使用用例带着WebCodecs和WebTransport
我想说在WebRTC NV上发生的另一件事,它变得非常重要,即人们已聚焦于机器学习和访问裸媒体。这是ORTC没有提供的。且我想说的是WebTransport或WebCodecs模型相比ORTC在更底层。ORTC不会给你直接访问编码器和解码器。这在WebCodecs中能获得。所以我认为我们将带着ORTC的思想且我们已使它更底层到传输层
我们将谈论ML和WebRTC的交集,但首先让我们说一下ORTC
ORTC发生了什么
Object RTC(ORTC)是WebRTC的替代模型提供不使用SDP的底层控制。Bernard是作者之一且微软启动Edge支持ORTC。我们没有听说过ORTC更多的消息,所以它发生了什么?Bernard刚才解释了,它的许多部分被吸收进了WebRTC标准核心。这导致ORTC前景的失败还是成功?
Chad: 你是原始ORTC指导说明的作者之一。你怎么比较现在和你原始的ORTC前景?
Bernard: 对象模型在Chromium里是完整的。所以我们有了ORTC的一切 - 数据频道的Ice Transport, DTLS Transport, SCTP Transport - 所有这些对象现在在PC端WebRTC和Chromium浏览器上
ORTC也有高级功能比如兼容的simulcast和SVC。加上我们有原始ORTC没有的端到端加密,其通过可插入流支持。这样我们使WebRTC PC版在对象模型和所有这些扩展上和ORTC相当
我们寻求的场景像因特网一样聚焦于数据传输。你可看到WebRTC里的反应和使用案例 - 像点到点数据交换
WebTransport
WebTransport是另一个W3C指导说明,有它自己的工作组和指导说明。你可看到在WebRTC里熟悉的名字,包括Bernard
QUIC是一个改进的传输协议 - 像TCP/2,用于WebTransport
所以WebTransport是什么,它来自哪里和在WebRTC里它要做些什么
Bernard: WebTransport也是一个API,其在W3C WebTransport组中。它也是一系列协议 - 传输的系列 - 在IETF中。协议包括QUIC上的WebTrasnport被称为QUIC Transport或HTTP/3上及可能的HTTP/2上的WebTransport。这样W3C上的WebTrasnport API只支持QUIC和HTTP/3。HTTP/2被认为是传输的失败,其将可能有一个独立的API
这些API是一个客户端服务器API。有点像WebSockets。构建WebTransport,你给定一个URL,得到一个WebTrasport。它不同于你创建的可靠流和数据报
数据报,用于UDP,它很快,但它是不可靠地转发
Bernard: 且它是双向的,一旦WebTransport在客户端初始化,但一旦连接已经好了,服务器可初始化一个单向或一个双向流给客户端且数据报可前向后向流动
双向 - 和websocket一样?
Bernard: WebSocket只是客户端。WebSocket不能被服务器初始化,但WebTransport可以。在QUIC上的WebTransport连接是非池化的。在HTTP/3上的WebTransport它可被池化 - 创建一些非常有趣的场景,一些被IETF BoFs恢复。你可认为你可做HTTP/3请求响应和WebTransport,包括基于相同QUIC连接的流和数据报
一个场景是justin Uberti基于以下人的想法把IETF的RIPT BOF放到一起。在这个场景下,你有一个RPC前向后向 - RPC请求响应 - 结果是从服务器到客户端的流。所以认为它是一个客户端,我想要播放影片或进入游戏或进入一个视频会议,且然后一个流可能是一个从服务器来的可靠的QUIC流、或数据报
我认为WebTransport有潜力对web带来革命性的改变。HTTP/3本身对web是一个革命性的改变。很多这些在一个更复杂的版本里,为HTTP/3池化传输。QUIC传输更简单,它给我们一个socket且我将发送前向后向数据